本文介绍: 在了解一致性Hash算法之前,先来讨论一下Hash本身的特点。普通的Hash函数最大的作用是散列,或者说是将一系列在形式上具有相似性质的数据,打散成随机的均匀分布的数据。负载均衡正是利用这一特性,对于大量随机的请求或调用,通过一定形式的Hash将他们均匀的散列,从而实现压力的平均化。举个例子,如果我们给每个请求生成一个Key,只要使用一个非常简单的Hash算法来实现请求的负载均衡,如下:不难发现,这样的Hash只要集群的数量N发生变化,之前的所有Hash映射就会全部失效。
一致性Hash是一种特殊的Hash算法,由于其均衡性、持久性的映射特点,被广泛的应用于负载均衡领域,如nginx和memcached都采用了一致性Hash来作为集群负载均衡的方案。
一致性Hash算法简介
在了解一致性Hash算法之前,先来讨论一下Hash本身的特点。普通的Hash函数最大的作用是散列,或者说是将一系列在形式上具有相似性质的数据,打散成随机的、均匀分布的数据。负载均衡正是利用这一特性,对于大量随机的请求或调用,通过一定形式的Hash将他们均匀的散列,从而实现压力的平均化。
举个例子,如果我们给每个请求生成一个Key,只要使用一个非常简单的Hash算法Group = Key % N来实现请求的负载均衡,如下:
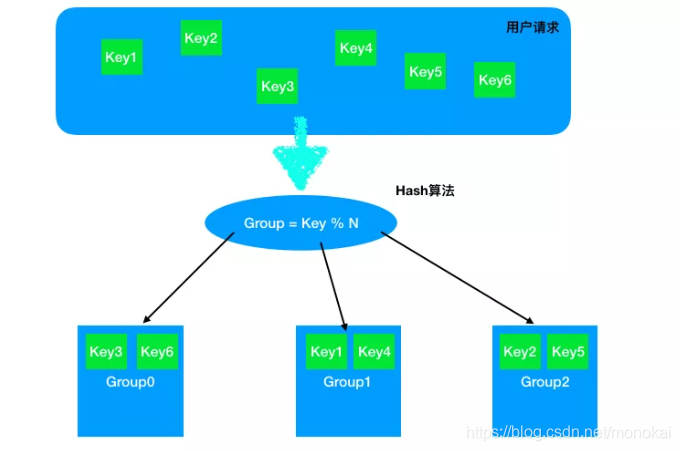
不难发现,这样的Hash只要集群的数量N发生变化,之前的所有Hash映射就会全部失效。如果集群中的每个机器提供的服务没有差别,倒不会产生什么影响,但对于分布式缓存这样的系统而言,映射全部失效就意味着之前的缓存全部失效,后果将会是灾难性的。
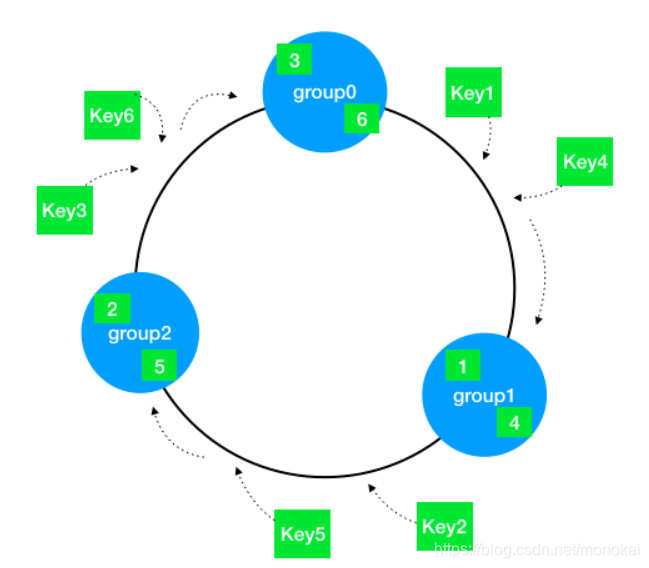
一致性Hash通过构建环状的Hash空间代替线性Hash空间的方法解决了这个问题,如下图:
问题与优化
数据倾斜
缓存雪崩
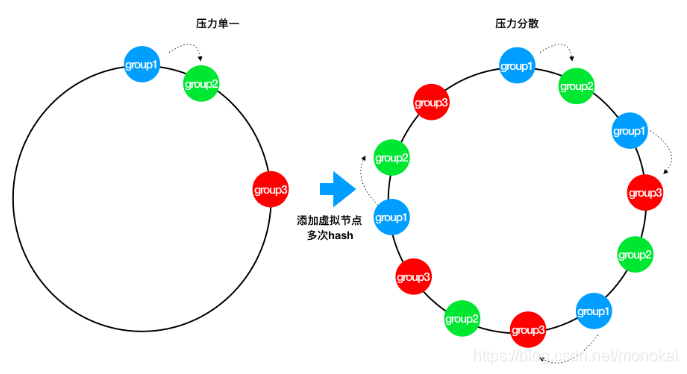
引入虚拟节点
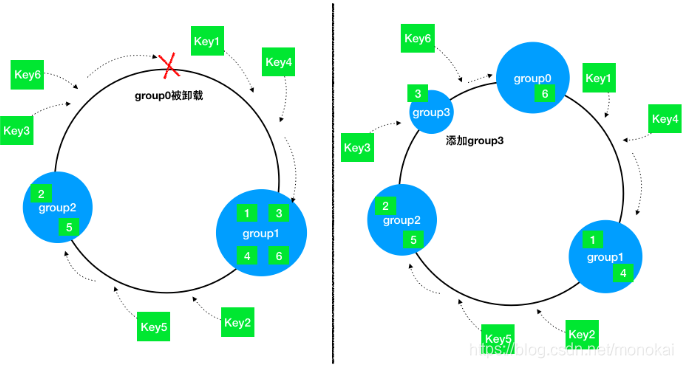
优雅缩扩容
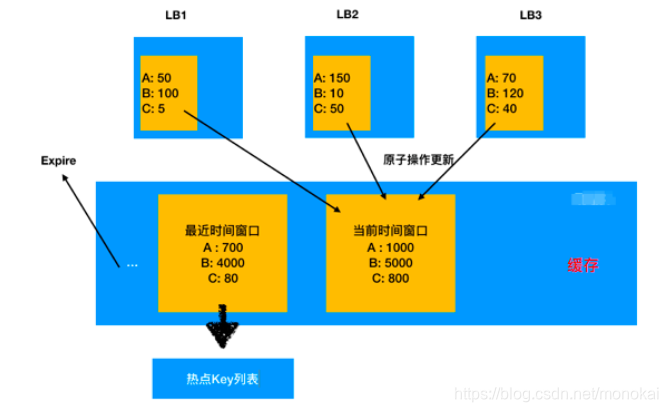
高频Key预热
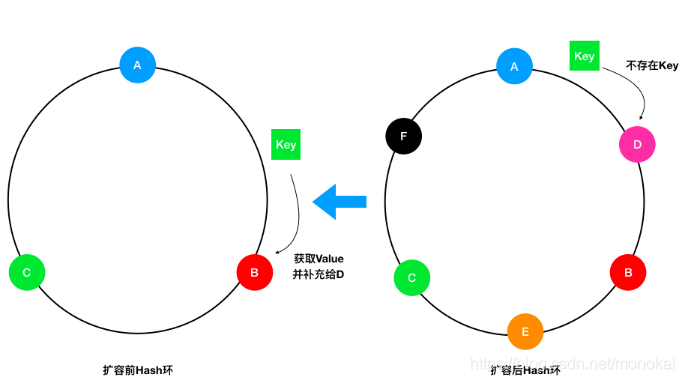
历史Hash环保留
声明:本站所有文章,如无特殊说明或标注,均为本站原创发布。任何个人或组织,在未征得本站同意时,禁止复制、盗用、采集、发布本站内容到任何网站、书籍等各类媒体平台。如若本站内容侵犯了原著者的合法权益,可联系我们进行处理。