文章目录
本文主要描述:Calcite 相关的基础性内容。
- 关系代数基础概念
- 查询优化简单介绍
- sql关键字解析顺序
- calcite基础概念
上篇了解了【源码分析】 Calcite 处理流程详解:calcite架构、处理流程以及就一个运行示例进行源码分析之后,我们对calcite有了一定的认知,但有些细节还未说明,所以本篇讨论对 Calcite 相关的基础性内容进行说明。希望通过本篇能够对Calcite的原理细节有一个更加清晰的了解。
一. 关系代数的基本知识
在学习Apache Calcite的一些基本概念之前,首先要弄懂关系表达式,并且要知道SQL与关系表达式的关系,因为Calcite的最核心的概念就是关系表达式。
关系代数是关系型数据库操作的理论基础,关系代数支持并、差、笛卡尔积、投影和选择等基本运算。关系代数也是 Calcite 的核心,任何一个查询都可以表示成由关系运算符组成的树。
在 Calcite 中,它会先将 SQL 转换成关系表达式(relational expression),然后通过规则匹配(rules match)进行相应的优化,优化会有一个成本(cost)模型为参考。
关系代数相关内容,简单总结如下:

二. 查询优化
查询优化主要是围绕着 等价交换 的原则做相应的转换,相关文章
三. SQL语句的解析顺序
一个sql语句是按照如下的顺序解析的:
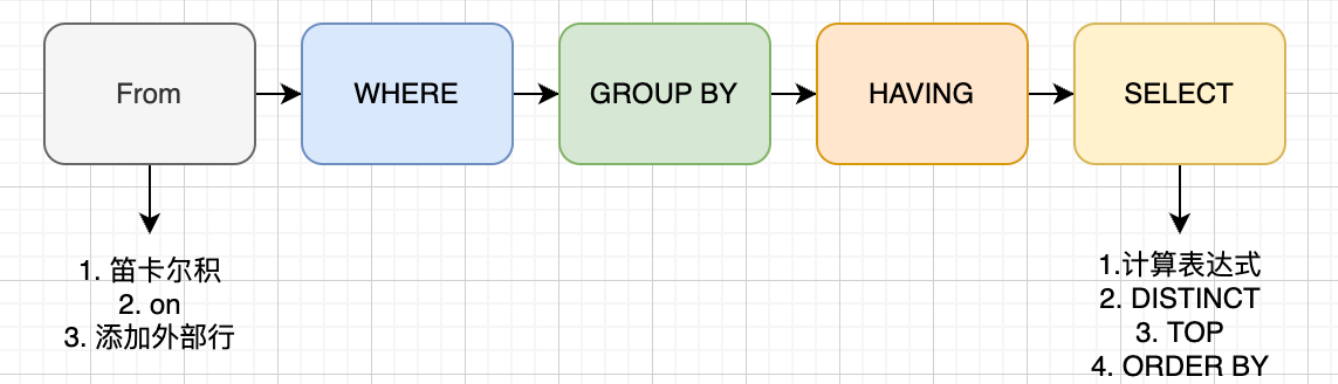
1. FROM
FROM后面的表标识了这条语句要查询的数据源。和一些子句如,(1-J1)笛卡尔积,(1-J2)ON过滤,(1-J3)添加外部列,所要应用的对象。FROM过程之后会生成一个虚拟表VT1。
- (1-J1)笛卡尔积 这个步骤会计算两个相关联表的笛卡尔积(CROSS JOIN) ,生成虚拟表VT1-J1。
- (1-J2)ON过滤 这个步骤基于虚拟表VT1-J1这一个虚拟表进行过滤,过滤出所有满足ON 谓词条件的列,生成虚拟表VT1-J2。
- (1-J3)添加外部行 如果使用了外连接,保留表中的不符合ON条件的列也会被加入到VT1-J2中,作为外部行,生成虚拟表VT1-J3。
2. WHERE
对VT1过程中生成的临时表进行过滤,满足where子句的列被插入到VT2表中。
3. GROUP BY
这个子句会把VT2中生成的表按照GROUP BY中的列进行分组。生成VT3表。
4. HAVING
这个子句对VT3表中的不同的组进行过滤,满足HAVING条件的子句被加入到VT4表中。
5. SELECT
这个子句对SELECT子句中的元素进行处理,生成VT5表。
- (5-1)计算表达式 计算SELECT 子句中的表达式,生成VT5-1
- (5-2) DISTINCT 寻找VT5-1中的重复列,并删掉,生成VT5-2
- (5-3) TOP 从ORDER BY子句定义的结果中,筛选出符合条件的列。生成VT5-3表
- ORDER BY 从VT5-3中的表中,根据ORDER BY 子句的条件对结果进行排序,生成VC6表。
四. Apache Calcite中的基本概念
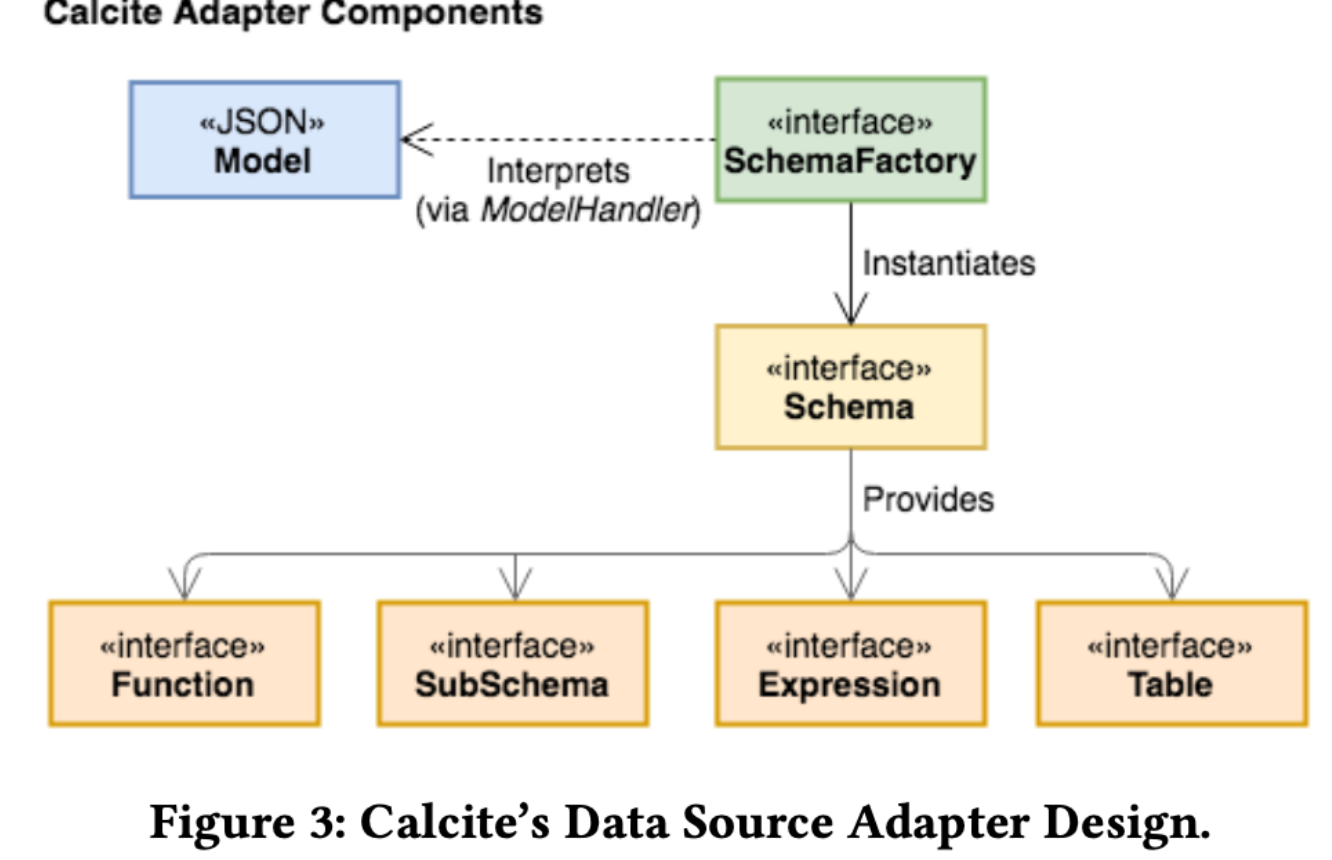
1. Adapter
在Calcite的架构中,Adapter的概念使Calcite知道如何去访问不同的数据源。一个数据源的Adapter对应有一个model,一个schema,一个schema Factory。
model定义了数据源的物理属性,比如下面的JDBC Adapter的model:
{
"defaultSchema": "db1",
"schemas": [
{
"factory": "org.apache.calcite.adapter.jdbc.JdbcSchema$Factory",
"name": "db1",
"operand": {
"jdbcDriver": "com.mysql.cj.jdbc.Driver",
"jdbcPassword": "changeme",
"jdbcUrl": "jdbc:mysql://localhost:3306/test",
"jdbcUser": "root"
},
"type": "custom"
}
],
"version": "1.0"
}
schema定义了数据的格式和层次。schema factory可以解析model来创建schema。
2. Calcite中的关系表达式
在 Calcite 中,关系表达式通常以树形结构的形式表示。树的根节点是查询的最外层操作符,例如 SELECT、FROM、WHERE 等,每个操作符都有其对应的子节点,子节点可以是另一个关系表达式或者具体的数据源(where: 由adapter实现?)。
2.1. 关系表达式例子
如下 SQL 查询及其关系表达式
SELECT *
FROM orders o
JOIN customers c ON o.customer_id = c.customer_id
WHERE c.state = 'CA';
LogicalProject(order_id=[$0], order_date=[$1], customer_id=[$2], order_total=[$3])
LogicalFilter(condition=[=($5, 'CA')])
LogicalJoin(condition=[=($2, $6)], joinType=[inner])
EnumerableTableScan(table=[[MY_DB, ORDERS]])
EnumerableTableScan(table=[[MY_DB, CUSTOMERS]])
说明
- 每个节点代表一个操作符,例如 LogicalProject 代表 SELECT 操作,LogicalFilter 代表 WHERE 操作,LogicalJoin 代表 JOIN 操作。
- 节点的顺序和嵌套结构代表了查询的**执行顺序(从下往上看)**和逻辑关系。
- 节点参数:包括操作符参数和子节点引用。例如 LogicalProject 的参数是输出的列,子节点是它所操作的关系表达式。
理解关系表达式对于理解 Calcite 的查询优化和执行过程非常重要。
2.2. 源码底层结构
转换为关系表达式的基本逻辑
在calcite中,当一个sql字符串被解析为SqlNode结构的AST树(抽象语法树)后,并不能直接被Calcite的优化器优化。还需要通过SqlToRelConverter将SqlNode结构转换成为RelNode结构组成的树。
关系表达式算子接口与实现
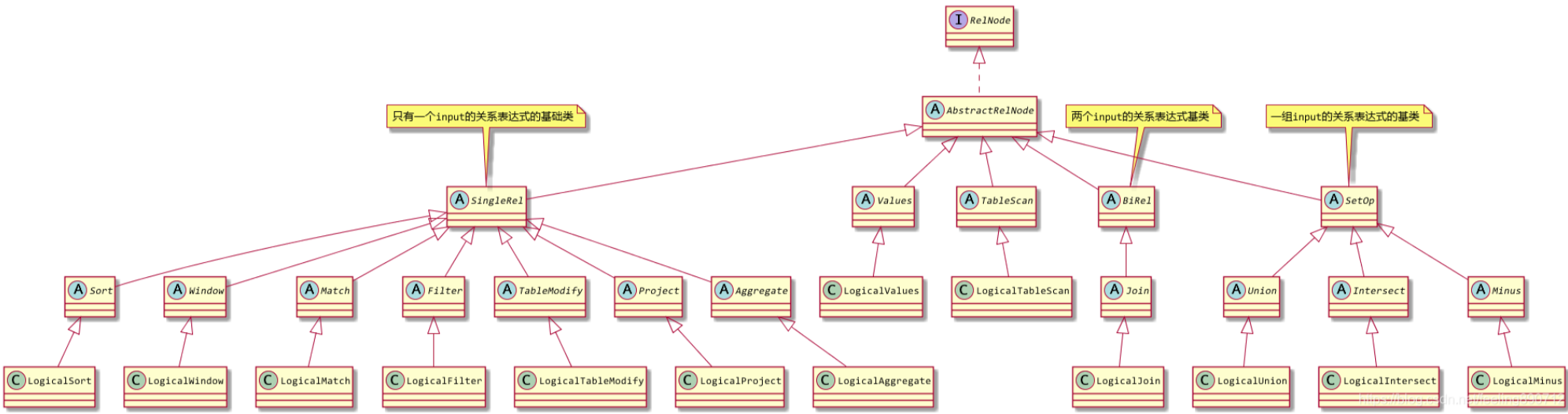
如上图所示,Calcite所有的关系表达式算子都需要实现RelNode接口。其中Calcite的核心算子有:TableScan, TableModify, Values, Project, Filter, Aggregate, Join, Sort, Union, Intersect, Minus, Window 与Match。
通过这些类的名字比较容易理解它们与SQL的对应关系,比如TableModify对应SQL中的INSERT、UPDATE、CREATE操作,Minus对应SQL中的EXCEPT操作,Window对应流处理的window概念等。
Calcite中的这些核心算子都有对应的纯逻辑子类LogicalXXX,SqlToRelConverter将SqlNode转换出来的RelNode树中,每个节点都是这些LogicalXXX子类组成的。它们并不能生成可执行的执行计划,只是用于表示SQL对应的关系表达式结构。
Adapter 对接实现
与Calcite对接的后端执行引擎的Adapter都会实现这些算子的可执行的实现。比如Cassandra adpter会有CassandraProject 在Calcite中逻辑算子转换成后端引擎实现的对应算子是在Calcite Planner(优化器)对RelNode树执行优化时候根据优化Rule将逻辑算子替换成对应的实际算子。
这里的adapter与flink的connector设计上是什么关系?
3. Calcite的优化规则
Calcite的优化器规则可以将一个关系表达式转换成等价的关系表达式,而这些优化器规则的基类都是RelOptRule。如下图的EnumerableSortRule可以将LogicalSort逻辑算子转换成Calcite内建的可执行的算子EnumerableSort。
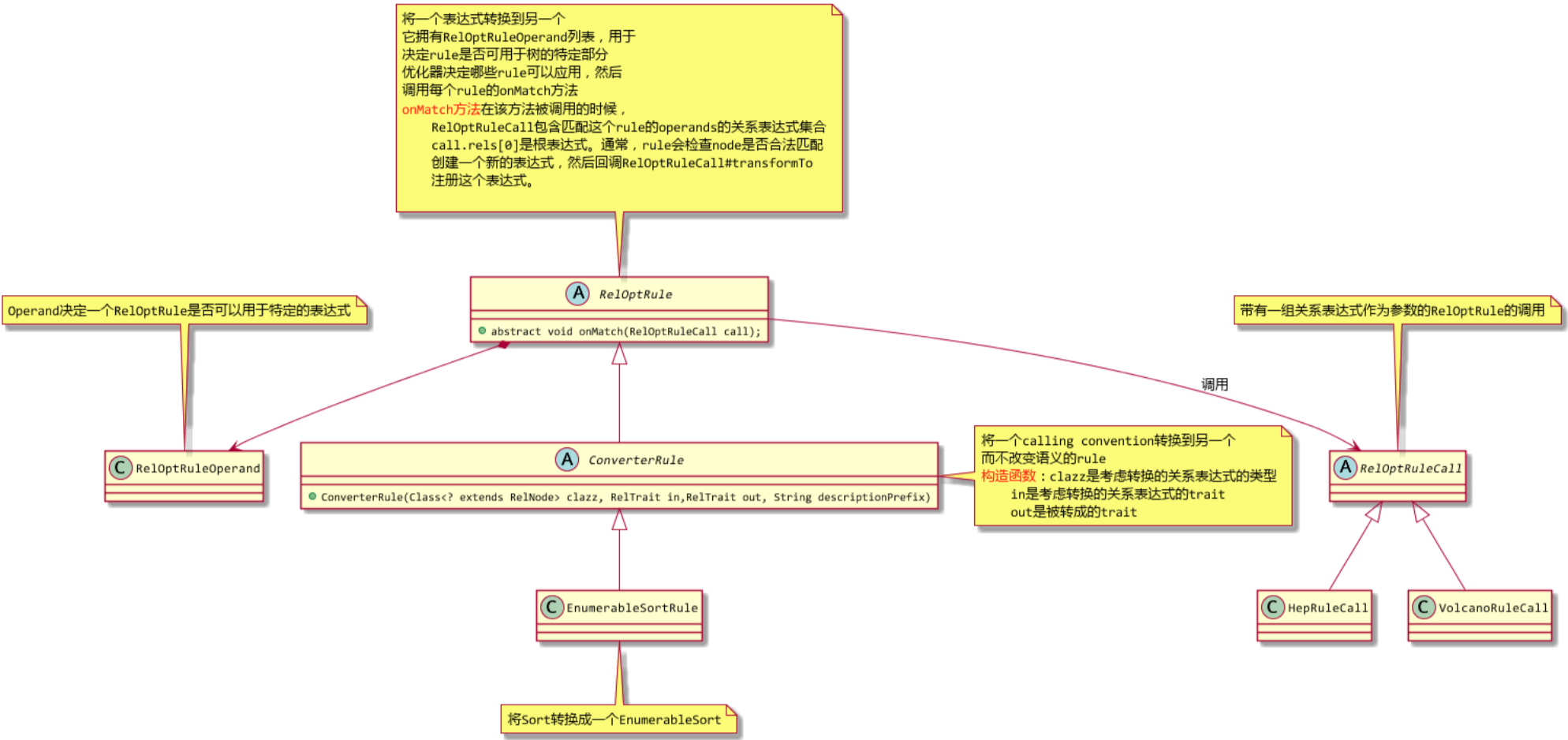
package org.apache.calcite.adapter.enumerable;
class EnumerableSortRule extends ConverterRule {
EnumerableSortRule() {
super(Sort.class, Convention.NONE, EnumerableConvention.INSTANCE,
"EnumerableSortRule");
}
public RelNode convert(RelNode rel) {
final Sort sort = (Sort) rel;
if (sort.offset != null || sort.fetch != null) {
return null;
}
final RelNode input = sort.getInput();
return EnumerableSort.create(
convert(
input,
input.getTraitSet().replace(EnumerableConvention.INSTANCE)),
sort.getCollation(),
null,
null);
}
}
Sort.class在优化器运行时匹配这条规则,然后优化器调用convert将原来的Sort算子转换为EnumerableSort算子。比如,LogicalSort在优化器优化时会匹配到这条规则,EnumerableSort就会替代LogicalSort。
除了上面的转换规则以外,Calcite已经实现了许多规则可以注册到优化器中,在优化时调用,比如filter、project等算子下推的优化规则等。目前Calcite已经实现了两种优化器引擎:基于代价优化的class VolcanoPlanner和基于经验的优化class HepPlanner。
4. Calcite的Trait–算子物理属性
在Calcite中没有使用不同的对象代表逻辑和物理算子,而是使用trait来表示一个算子的物理属性。
Calcite中使用接口RelTrait来代表一个关系表达式节点的物理属性,使用RelTraitDef来表示Reltrait的class。
RelTrait与RelTraitDef的关系就像java中对象与Class的关系一样,每个对象都有Class。
对于物理的关系表达式算子会有一些物理属性,这些物理属性都会用RelTrait来表示。
比如每个算子都有Calling Convention这一Reltrait。比如上图中Sort算子还会有一个物理属性RelCollation,因为Sort算子会对表的一些字段进行排序,RelCollation这一物理属性就会记录这个Sort算子要排序的字段索引、排序方向,null值怎么排序等信息。

5. Calcite的Calling Convention(调用约定)
Calling Convention在Calcite中使用接口Convention表示,Convention接口是RelTrait的直接口,所以是一个算子的属性。
Calling Convention可以理解为一个特定数据引擎协议,拥有相同Convention的算子可以认为都是同一个数据引擎的算子可以相互连接起来。比如JDBC的算子JDBCXXX都有JdbcConvention,Calcite的内建Enumerable算子EnumerableXXX都有EnumerableConvention。
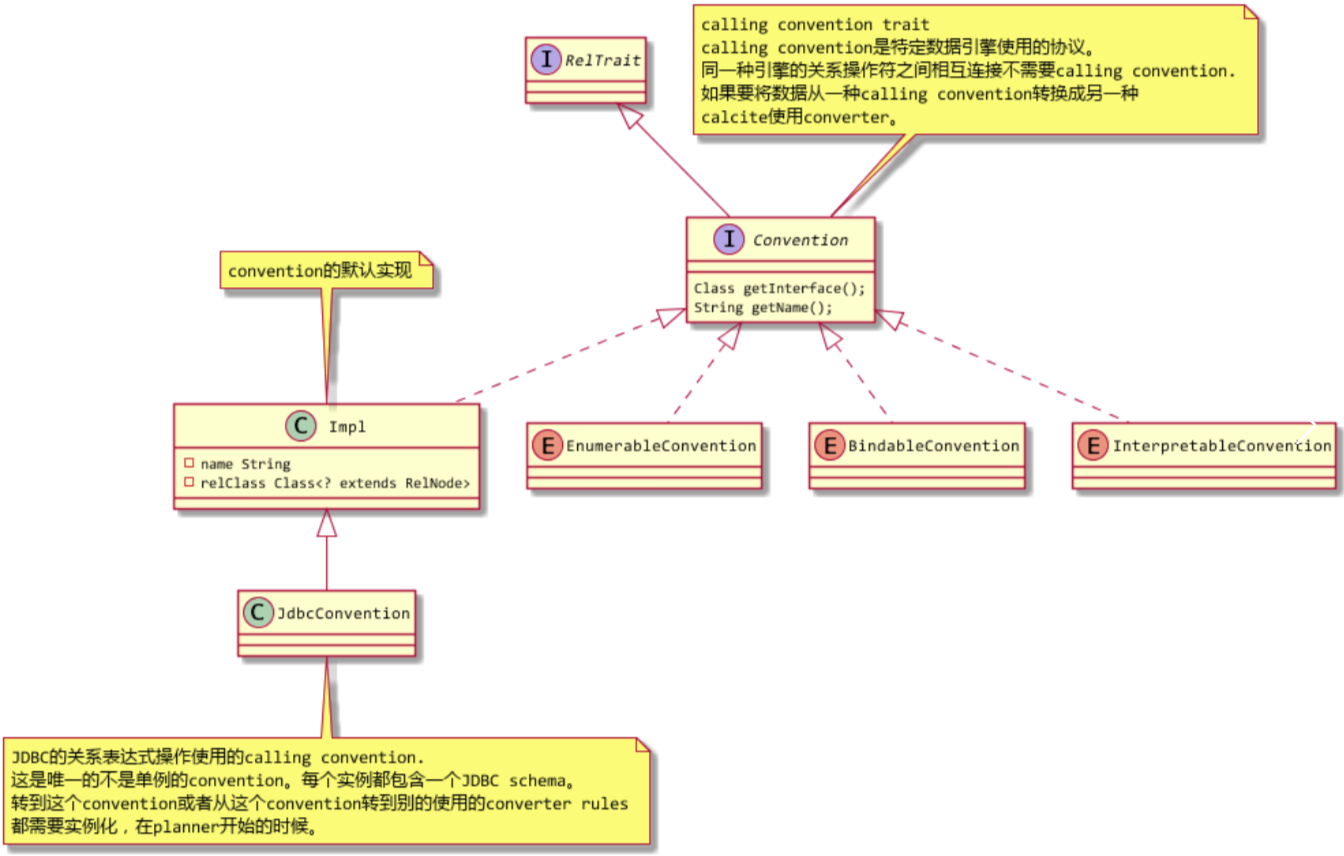
上图中,Jdbc算子可以通过JdbcConvention获得对应数据库的SqlDialect和JdbcSchema等数据,这样可以生成对应数据库的sql,获得数据库的连接池与数据库交互实现算子的逻辑。
join场景
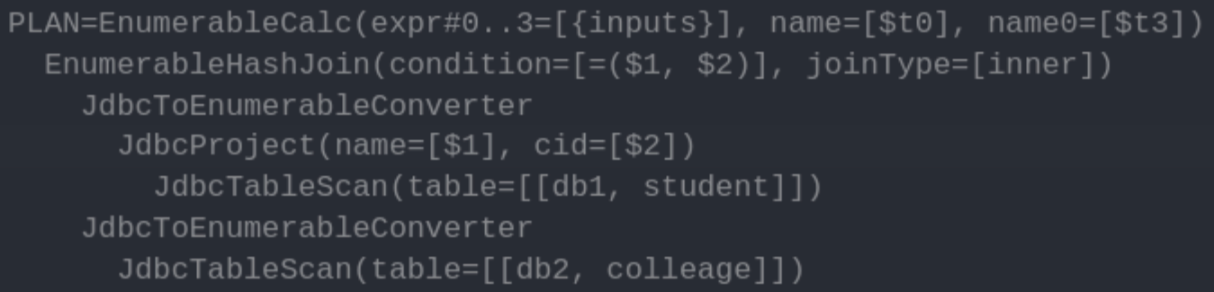
如果数据要从一个Calling Convention的算子到另一个Calling Convention算子的时候,比如使用Calcite进行跨库join的场景。需要接口Converter的子类作为两种算子之间的桥梁将两种算子连接起来。
比如上面的执行计划,要将Enumerable的算子与Jdbc的算子连接起来,中间就要使用JdbcToEnumerableConverter作为桥梁。
6. Calcite内建算子
如果一个Adapter没有实现所有的核心关系表达式算子,Calcite也能生成完整的执行计划,完成整个数据处理过程。这是因为Calcite内建了EnumerableConvention作为Calling Convention的Enumerable算子,实现了所有核心的关系表达式算子,比如EnumerableFilter,EnumerableSrt,EnumerableHashJoin等。
Enumerable算子效率不高
使用Enumerable算子效率不高,而且都是在内存中处理的。比如EnumerableHashJoin算子join两个表都是在内存中处理表的所有数据,数据量一大就会造成内存溢出。如果实现一个数据引擎的Adapter,能提供对应算子的处理能力就应该实现这个算子,将工作推到后端的数据引擎中处理,避免回退到使用Enumerable算子。
参考:
https://blog.csdn.net/feeling890712/article/details/106333425
原文地址:https://blog.csdn.net/hiliang521/article/details/135397456
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。
如若转载,请注明出处:http://www.7code.cn/show_52336.html
如若内容造成侵权/违法违规/事实不符,请联系代码007邮箱:suwngjj01@126.com进行投诉反馈,一经查实,立即删除!