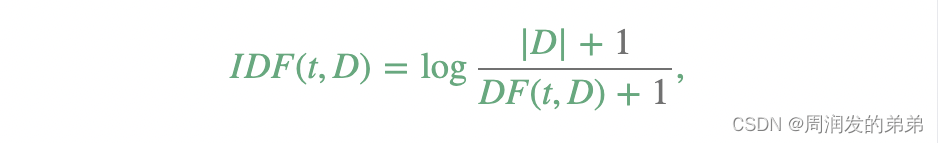本文介绍: TF-IDF的介绍与实现
TF-IDF
TF-IDF全称为“Term Frequency-Inverse Document Frequency”,是一种用于信息检索与文本挖掘的常用加权技术。该方法用于评估一个词语(word)对于一个文件集(document)或一个语料库中的其中一份文件的重要程度。它是一种计算单词在文档集合中的分布情况的统计方法。
TF(Term Frequency,词频)
TF指的是某一个给定的词语在该文件中出现的频率。这个数字是对词数(term count)进行归一化(通常是文档中单词总数),以防止它偏向长的文件。(即某个单词在文章中出现次数越多,其TF值也就越大)
TF的公式如下:
T
F
(
IDF(Inverse Document Frequency,逆向文件频率)
Python实现-sklearn
Python实现
声明:本站所有文章,如无特殊说明或标注,均为本站原创发布。任何个人或组织,在未征得本站同意时,禁止复制、盗用、采集、发布本站内容到任何网站、书籍等各类媒体平台。如若本站内容侵犯了原著者的合法权益,可联系我们进行处理。