本文介绍: 大型语言模型是一种机器学习模型,它在大型文本数据语料库上进行训练,以生成各种自然语言处理(NLP)任务的输出,如文本生成、问答和机器翻译大型语言模型通常基于深度学习神经网络,如Transformer架构,并在大量文本数据上进行训练,通常涉及数十亿个单词。较大的模型,如谷歌的BERT模型,使用来自各种数据源的大型数据集进行训练,这使它们能够为许多任务生成输出。如果您是大型语言模型的新手,请查看我们的“大型语言模型:2023年完整指南”文章。做一个简单介绍,酒研。
2022年底,大型语言模型(LLM)在互联网上掀起了风暴,OpenAI的ChatGPT在推出5天后就达到了100万用户。ChatGPT的功能和广泛的应用程序可以被认可为GPT-3语言模型所具有的1750亿个参数
尽管使用像ChatGPT这样的最终产品语言模型很容易,但开发一个大型语言模型需要大量的计算机科学知识、时间和资源。我们撰写这篇文章是为了让商业领袖了解:
这样他们就可以有效地利用人工智能和机器学习。
什么是大型语言模型?
大型语言模型是一种机器学习模型,它在大型文本数据语料库上进行训练,以生成各种自然语言处理(NLP)任务的输出,如文本生成、问答和机器翻译
大型语言模型通常基于深度学习神经网络,如Transformer架构,并在大量文本数据上进行训练,通常涉及数十亿个单词。较大的模型,如谷歌的BERT模型,使用来自各种数据源的大型数据集进行训练,这使它们能够为许多任务生成输出。
如果您是大型语言模型的新手,请查看我们的“大型语言模型:2023年完整指南”文章。
按参数大小排列的顶级大型语言模型
大型语言模型的架构
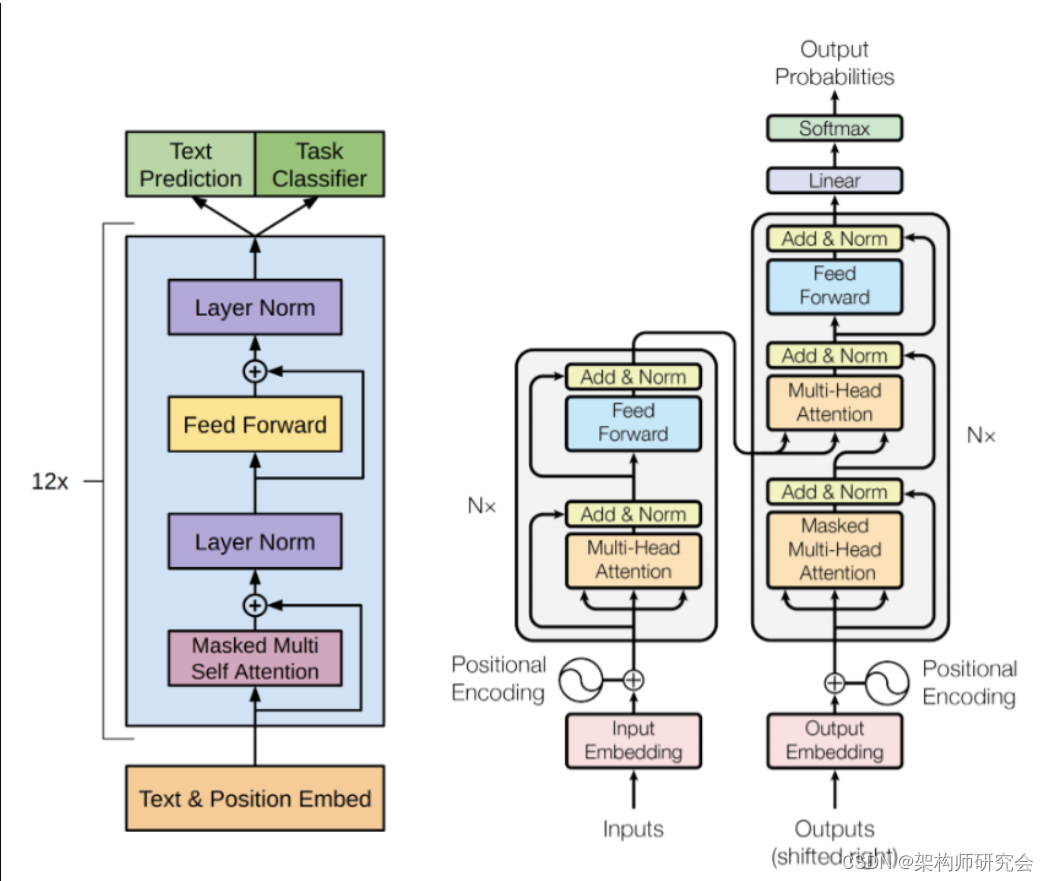 Source:
Source:1.输入嵌入
2.多头自我关注
3.前馈网络
4.归一化和剩余连接
训练大型语言模型
1.数据收集和预处理
2.型号选择和配置
3.模型培训
4.评估和微调
针对特定用例培训LLM
自我介绍

声明:本站所有文章,如无特殊说明或标注,均为本站原创发布。任何个人或组织,在未征得本站同意时,禁止复制、盗用、采集、发布本站内容到任何网站、书籍等各类媒体平台。如若本站内容侵犯了原著者的合法权益,可联系我们进行处理。






