前言
Spark 是 UC Berkeley AMP Lab 开源的通用分布式并行计算框架。
Spark基于map reduce算法实现的分布式计算,拥有Hadoop MapReduce所具有的优点;但不同于MapReduce的是Job中间输出和结果可以保存在内存中,从而不再需要读写HDFS,因此Spark能更好地适用于数据挖掘与机器学习等需要迭代的map reduce的算法。
spark是基于内存计算框架,计算速度非常之快,但是它仅仅只是涉及到计算,并没有涉及到数据的存储,后期需要使用spark对接外部的数据源,比如hdfs。
Spark的四大特性
Simple(易用性)
Spark 提供了丰富的高级运算操作,支持丰富的算子,并支持 Java、Python、Scala、R、SQL 等语言的 API,使用户可以快速构建不同的应用。
开发人员只需调用 Spark 封装好的 API 来实现即可,无需关注 Spark 的底层架构。
Fast(速度快)
Spark 将处理的每个任务都构造成一个DAG(Directed Acyclic Graph, 有向无环图)来执行,实现原理是基于RDD(Resilient Distributed Dataset, 弹性分布式数据集)在内存中对数据进行迭代计算,以实现批量和流式数据的高性能快速计算处理。
Spark比MR速度快的原因
基于内存
mapreduce任务后期再计算的时候,每一个job的输出结果会落地到磁盘,后续有其他的job需要依赖于前面job的输出结果,这个时候就需要进行大量的磁盘io操作。性能就比较低。
spark任务后期再计算的时候,job的输出结果可以保存在内存中,后续有其他的job需要依赖于前面job的输出结果,这个时候就直接从内存中获取得到,避免了磁盘io操作,性能比较高
对于spark程序和mapreduce程序都会产生shuffle阶段,在shuffle阶段中它们产生的数据都会落地到磁盘。
进程与线程
mapreduce任务以进程的方式运行在yarn集群中,比如程序中有100个MapTask,一个task就需要一个进程,这些task要运行就需要开启100个进程。
spark任务以线程的方式运行在进程中,比如程序中有100个MapTask,后期一个task就对应一个线程,这里就不再是进程,这些task需要运行,这里可以极端一点:只需要开启1个进程,在这个进程中启动100个线程就可以了。
进程中可以启动很多个线程,而开启一个进程与开启一个线程需要的时间和调度代价是不一样。 开启一个进程需要的时间远远大于开启一个线程。## Scalable(可融合性)
Unified(通用性)
大数据处理的传统方案需要维护多个平台,比如,离线任务是放在 Hadoop MapRedue 上运行,实时流计算任务是放在 Storm 上运行。
而Spark 提供了一站式的统一解决方案,可用于批处理、交互式查询(Spark SQL)、实时流处理(Spark Streaming)、机器学习(Spark MLlib)和图计算(GraphX)等。这些不同类型的处理都可以在同一个应用中无缝组合使用。
Scalable(兼容性)
Spark 可以非常方便地与其他的开源产品进行融合。比如:Spark 可以使用 Hadoop 的 YARN 和 Apache Mesos 作为它的资源管理和调度器;可以处理所有 Hadoop 支持的数据,包括 HDFS、HBase 和 Cassandra 等。
本博的重点: spark的分布式部署
第一步 下载spark和 scala
scala的下载地址:官网下载scala:https://www.scala-lang.org/download/2.13.1.html
spark的下载地址: https://dlcdn.apache.org/spark/spark-3.5.0/spark-3.5.0-bin-hadoop3.tgz
cd /opt/module
官网下载scala:https://www.scala-lang.org/download/2.13.1.html
tar -xvf scala-2.13.1.tgz -C /opt/module#主节点的服务器 进入系统准备安装的路径
cd /opt/module/spark
wget https://mirrors.tuna.tsinghua.edu.cn/apache/spark/spark-3.3.1/spark-3.3.1-bin-hadoop3.tgz --no-check-certificate
tar -xvf spark-3.3.1-bin-hadoop3.tgz -C /opt/module/spark/spark-3.5.0
第二步 配置SPARK_HOME环境变量
vi /etc/profile
#添加以下配置内容,配置jdk环境变量
export JAVA_HOME=/kkb/install/jdk1.8.0_202
export PATH=$PATH:$JAVA_HOME/bin
export HADOOP_HOME=/kkb/install/hadoop-2.6.0-cdh5.14.2
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
export SPARK_HOME=/opt/module/spark/spark-3.5.0
export PATH=$PATH:$SPARK_HOME/bin:$SPARK_HOME/sbin
export SCALA_HOME=/opt/module/scala/scala-2.12.8
export PATH=$PATH:$SCALA_HOME/bin# 加载使其生效
source /etc/profile第三步 修改spark的配置文件
# 进入spark conf目录
cd /home/spark-3.3.1-bin-hadoop3/conf
# 拷贝模板文件
cp spark-defaults.conf.template spark-defaults.conf
cp spark-env.sh.template spark-env.sh
1、修改 spark-defaults.conf
##增加如下内容
spark.master spark://node01:7077
spark.serializer org.apache.spark.serializer.KryoSerializer
spark.driver.memory 512m
spark.executor.memory 512m2、修改spark-env.sh
#增加如下内容
export SPARK_DIST_CLASSPATH=$(/kkb/install/hadoop-2.6.0-cdh5.14.2/bin/hadoop classpath)
export HADOOP_CONF_DIR=/kkb/install/hadoop-2.6.0-cdh5.14.2/etc/hadoop
export JAVA_HOME=/kkb/install/jdk1.8.0_202
export HADOOP_HOME=/kkb/install/hadoop-2.6.0-cdh5.14.2
export YARN_CONF_DIR=/kkb/install/hadoop-2.6.0-cdh5.14.2/etc/hadoop
export SPARK_MASTER_HOST=node01
export SPARK_MASTER_PORT=70773、修改slaves文件
vi slaves
# 修改为如下内容
node01
node02
node03
第四步 将spark目录分发到其他节点
cd /home
scp -r ./spark-3.5.0/ hadoop@node02:/opt/module/spark/
scp -r ./spark-3.5.0/ hadoop@node03:/opt/module/spark第五步 启动Spark集群
cd /opt/module/spark/spark-3.5.0/sbin
./ start-all.sh第六步 . 在web界面查看Spark UI
在浏览器里面输入主节点的ip:8080

第七步 spark的运行作业测试案例
##提交作业
spark-submit --class org.apache.spark.examples.SparkPi $SPARK_HOME/examples/jars/spark-examples_2.12-3.5.0.jar 10 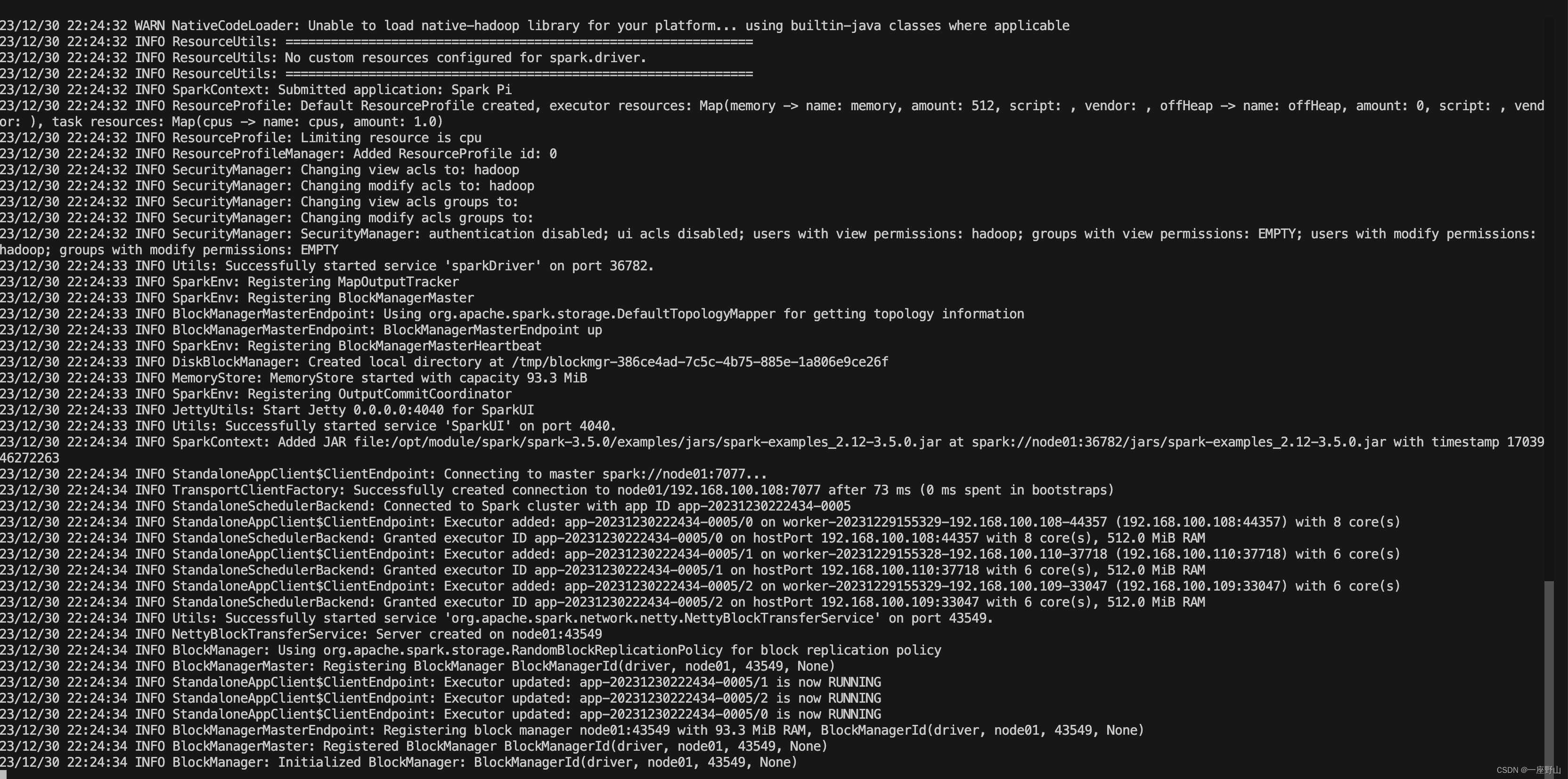
第八步. Yarn模式
上面默认是用standalone模式启动的服务,如果想要把资源调度交给yarn来做,则需要配置为yarn模式:
需要启动的服务:hdfs服务、yarn服务
需要关闭 Standalone 对应的服务(即集群中的Master、Worker进程)。
在Yarn模式中,Spark应用程序有两种运行模式:
yarn-client:Driver程序运行在客户端,适用于交互、调试,希望立2. 即看到app的输出
yarn-cluster:Driver程序运行在由RM启动的 AppMaster中,适用于生产环境
二者的主要区别:
Driver在哪里!
8.1 启动hdfs、yarn服务
此处略过
8.2 修改Hadoop中的 yarn-site.xml 配置
在$HADOOP_HOME/etc/hadoop/yarn-site.xml中增加如下配置,然后分发到集群其他节点,重启yarn 服务。
# 打开yarn-site.xml文件
vi /home/hadoop-3.3.2/etc/hadoop/yarn-site.xml
<property>
<name>yarn.nodemanager.pmem-check-enabled</name>
<value>false</value>
</property>
<property>
<name>yarn.nodemanager.vmem-check-enabled</name>
<value>false</value>
</property> 说明:yarn.nodemanager.pmem-check-enabled : 是否启动一个线程检查每个任务正使用的物理内存量,如果任务超出分配值,则直接将其杀掉,默认是true。
yarn.nodemanager.vmem-check-enabled :是否启动一个线程检查每个任务正使用的虚拟内存量,如果任务超出分配值,则直接将其杀掉,默认是true。
8.3 向hdfs上传spark纯净版jar包
cd /home/software
wget https://mirrors.tuna.tsinghua.edu.cn/apache/spark/spark-3.3.1/spark-3.3.1-bin-without-hadoop.tgz --no-check-certificate
tar -zxvf spark-3.3.1-bin-without-hadoop.tgz上传spark纯净版jar包到hdfs
hdfs dfs -mkdir /spark-jars
hdfs dfs -put /home/software/spark-3.3.1-bin-without-hadoop/jars/* /spark-jars说明:
Spark任务资源分配由Yarn来调度,该任务有可能被分配到集群的任何一个节点。所以需要将spark的依赖上传到hdfs集群路径,这样集群中任何一个节点都能获取到,依此达到Spark集群的HA。
Spark纯净版jar包,不包含hadoop和hive相关依赖,避免和后续安装的Hive出现兼容性问题。
8.4 Spark on Yarn测试
记得,先把Master与worker进程停掉,否则会走standalone模式。
# 停掉standalone模式的服务
stop-all.sh
8.4.1 client运行模式
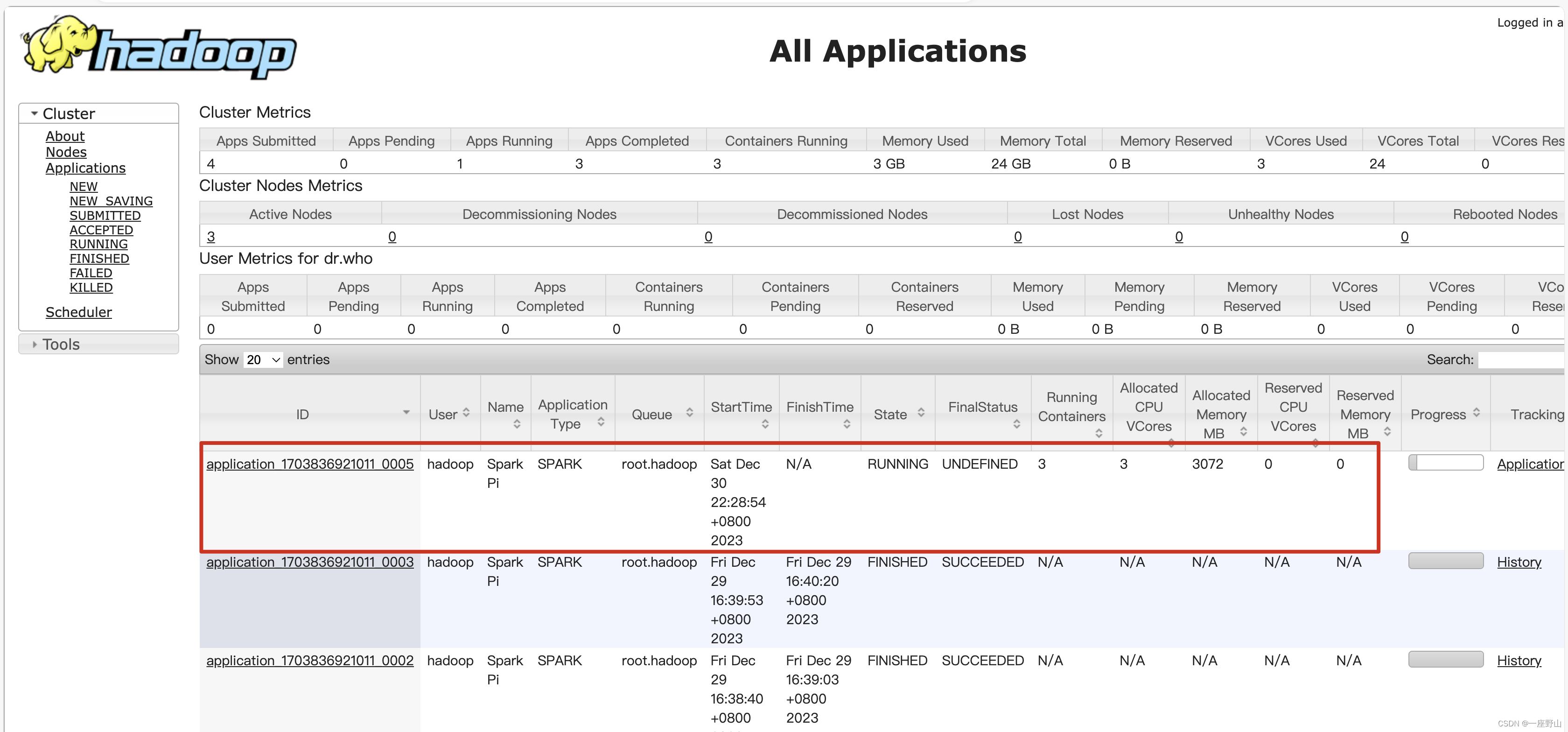
这种模式可以看见:程序计算的结果(即可以看见计算返回的结果)!
# client
spark-submit --master yarn
--deploy-mode client
--class org.apache.spark.examples.SparkPi
$SPARK_HOME/examples/jars/spark-examples_2.12-3.5.0.jar 20 
原文地址:https://blog.csdn.net/2301_81547508/article/details/135310281
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。
如若转载,请注明出处:http://www.7code.cn/show_52566.html
如若内容造成侵权/违法违规/事实不符,请联系代码007邮箱:suwngjj01@126.com进行投诉反馈,一经查实,立即删除!






