想象一下,你是一名侦探,身处庞大的信息世界,试图在堆积如山的数据中找到隐藏的一条重要线索,这就是检索增强生成(RAG)发挥作用的地方,它就像你在人工智能和语言模型世界中的可靠助手。但即使是最好的助理也有其局限性,因此,让我们开始探索RAG的高级方法,重点关注大规模文档检索中的精度和上下文。
一、基本RAG
想象一下,有一本和地平线一样宽百科全书。基本的RAG试图将这些丰富的知识提炼成一个单一的“嵌入”——本质上是一个数字。但是,当你在一个特定的主题上寻求智慧时,比如神秘的百慕大三角,基本的RAG的粗笔画会覆盖更多细节,给你留下一幅不完整的画面。这种限制就像试图用一张只显示大陆的地图来寻找隐藏的宝藏,而不是通往标有“X”的地点的复杂路径。
另一方面,如果我们只拥有带有嵌入的单个页面,我们可能会找出具体的事实,但当它们交织在一起时,我们就会失去它们所讲述的故事。如果没有叙事,大型语言模型(LLM)很难找到一个能抓住我们探究的真正本质的答案。
基本RAG,虽然是一个值得称赞的里程碑,但没有做的更好。基本RAG只是一个基础,需要跨越通用知识和精确见解之间的距离,我们需要做更细致的优化工作。
二、路径的细化:父子文档关系
我们不是对整个百科全书进行单一的总结,而是为每一页(子文档)进行简洁的概述,注意包含的章节(父文档)。该方法在我之前的LLM之RAG实战(五)| 高级RAG 01:使用小块检索,小块所属的大块喂给LLM,可以提高RAG性能博客中有所介绍,这里略过。
2.1 步骤1:父子文档关系
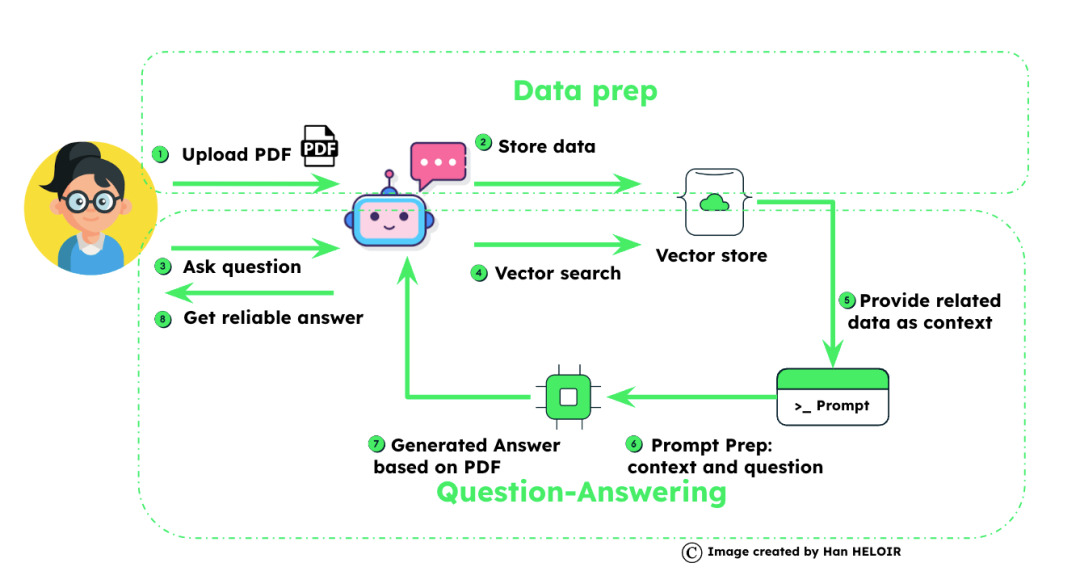
想象一下,你有一本又大又笨重的书——一本关于所有电器的用户手册。现在,有人问了一个特定的问题:“为什么我的洗衣机显示错误代码2?”,对于基本的RAG,我们要么得到缺乏上下文的小块,要么得到搜索不够准确的大块。然而,高级RAG采用了更聪明的方法。
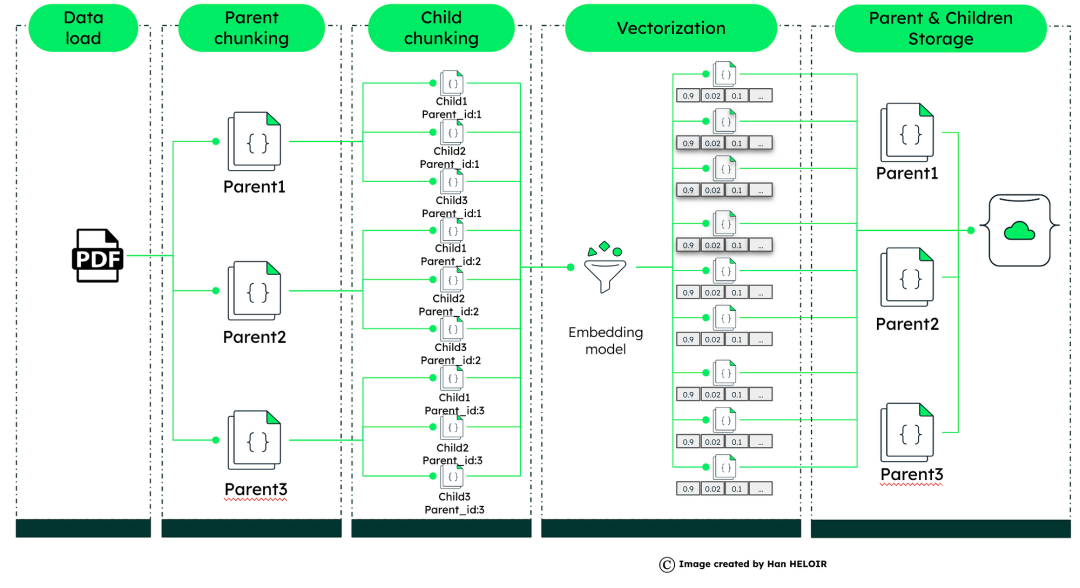
首先,手册被分解成大块——这些是我们的“父”文档。每一节都涉及更大的信息。在这些部分中,我们拆分了涵盖特定问题的“子”文档,如洗衣机的错误代码。
现在,来看看矢量化的魔力。每个子文档都通过嵌入模型进行处理,该模型分析文本并将其转换为向量——一系列表示文本本质的数字。这就像为每一小段信息创建一个DNA图谱。
每个子文档的文本都被提取到一个向量中,然后将其存储在向量存储中,其父文档也存储在这个向量存储中——这也是一个通用数据库。这使我们不仅可以快速检索最相关的小信息,还可以保留父文档提供的上下文。
2.2 步骤二:问答
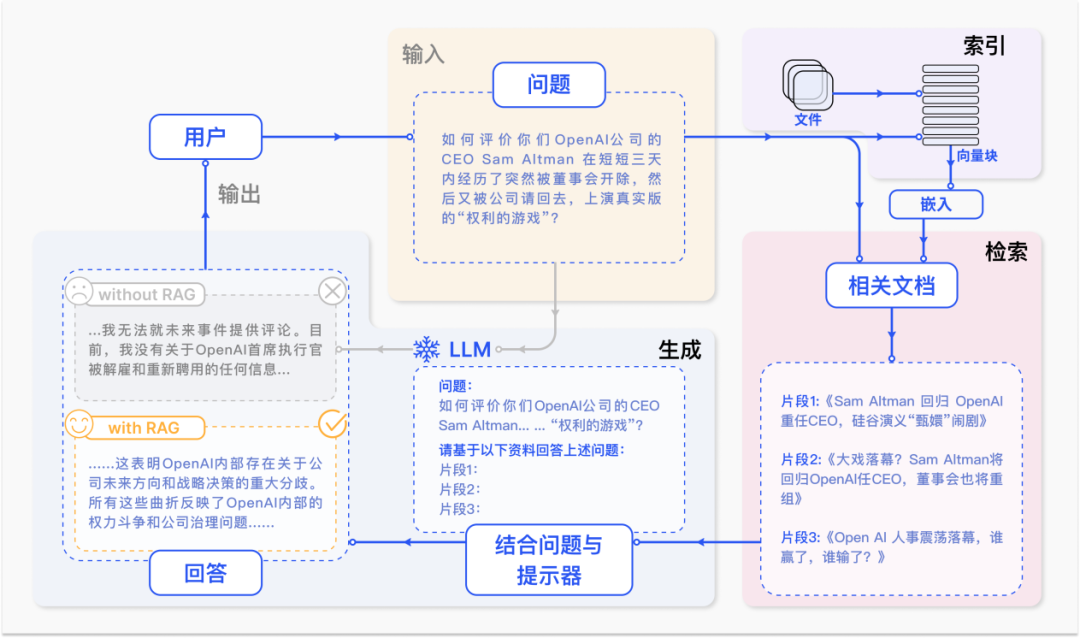
当关于洗衣机的问题出现时,它就变成了一个“嵌入”——把它想象成一个独特的数字签名。然后使用矢量搜索将这些嵌入与类似的子文档进行匹配。如果它与“洗衣机”部分的子文档嵌入紧密对齐,我们就找到了匹配项。
有了我们的矢量存储和准备,当出现问题时,我们可以迅速找到最相关的子文档。但是,我们没有提供狭义的回应,而是引入了母文档,它提供了更多的背景和上下文。这个准备好的提示富含特定信息和广泛的上下文,然后被输入到大型语言模型(LLM)中,该模型生成精确的上下文感知答案。
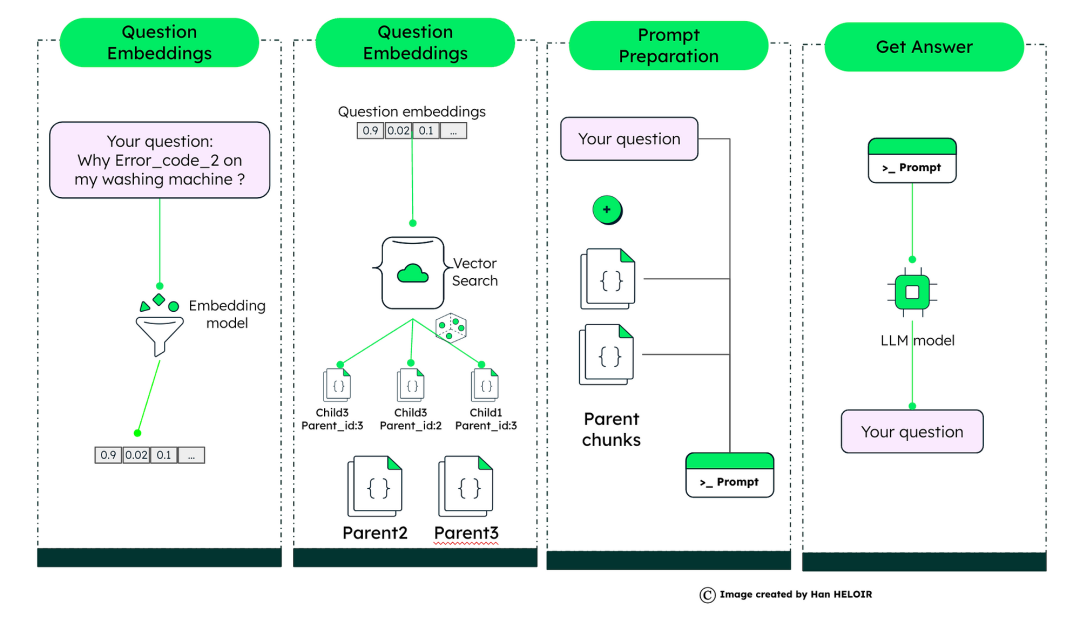
如图所示,这种先进的RAG过程确保LLM具有生成准确响应所需的所有上下文,就像侦探拼凑线索来解开谜团一样。借助MongoDB矢量搜索的强大功能,我们可以以超级计算机的速度和精度浏览这一过程,确保每个问题都得到尽可能好的答案。
三、MongoDB矢量搜索:高级RAG背后的动力
从父子关系和矢量化的复杂关系中走出来,我们直接进入了MongoDB的矢量搜索领域,该引擎为我们的高级RAG过程提供了动力。让我们深入研究一下MongoDB矢量搜索是如何将筛选堆积如山的数据这一艰巨任务转变为一个精简高效的过程的。
3.1 矢量搜索:快速寻找答案
MongoDB中的矢量搜索就像在浩瀚的数据海洋中拥有一盏高功率探照灯。当我们的洗衣机爱好者询问那个令人讨厌的错误代码时,矢量搜索不仅仅是梳理数据,它还可以精确定位信息的确切位置,这要归功于我们早些时候创建的独特的“数字签名”。最棒的部分?它以惊人的速度做到了这一点,使得搜索答案的速度就像翻阅一个组织良好的文件柜一样快。
3.2 结构与速度想结合
MongoDB的矢量搜索将结构和速度和谐地结合在一起。父文档和子文档的存储,以及它们的矢量化本质,使MongoDB能够快速识别最相关的数据片段,而不会被不太相关的信息所困扰。这是一位一丝不苟的图书管理员和一位侦探大师的完美结合,确保了没有遗漏任何线索,每个答案都切中要害。
3.3 语境丰富性:增加的层次
在这里,事情变得更加有趣。一旦矢量搜索精确定位了相关的子文档,它就不会止步于此。通过检索父文档,它确保了上下文的丰富性不会丢失。这意味着我们的LLM不仅了解“什么”,还了解“为什么”和“如何”,提供了超出表面水平的答案。
3.4 MongoDB:不仅仅是一个数据库
MongoDB不仅仅是一个存储数据的地方;这是一个动态的生态系统,支持先进的RAG过程的每一步。它可以轻松管理复杂的父文档和子文档网络,并促进快速矢量搜索,使高级RAG功能强大。使用MongoDB,我们不仅仅是在寻找答案;我们正在制定既能提供信息又能与上下文相关的回应。
3.5 结果:知情、准确的回答
由于高级RAG和MongoDB矢量搜索之间的强大协作,生成的响应不仅准确,而且信息丰富。当我们的用户询问洗衣机上的错误代码时,他们会收到一个既准确又充满有用上下文的回复,类似于为他们量身定制的全面指南。
MongoDB矢量搜索是这一高级RAG过程的支柱,提供了在复杂的数据检索环境中导航所需的速度和精度。在下一节中,我们将探索这一过程的实际实施,展示如何将先进的RAG系统应用到生活中,为用户提供人工智能所能提供的最佳答案。请继续关注我们将理论转化为实践,并充分发挥先进RAG的潜力。
四、用MongoDB矢量搜索实现高级RAG
将Advanced RAG与MongoDB Vector Search集成到我们的系统中,首先是几个技术组件的和数据处理流程。下面看一下具体步骤:
4.1 步骤1:设置和初始化
我们通过设置环境和建立必要的联系来启动工作,这包括加载环境变量,初始化OpenAI和MongoDB客户端,以及定义我们的数据库和集合名称。
import osfrom dotenv import load_dotenvfrom pymongo import MongoClientfrom langchain.embeddings import OpenAIEmbeddings# Load environment variables from .env fileload_dotenv(override=True)# Set up MongoDB connection detailsOPENAI_API_KEY = os.environ["OPENAI_API_KEY"]MONGO_URI = os.environ["MONGO_URI"]DB_NAME = "pdfchatbot"COLLECTION_NAME = "advancedRAGParentChild"# Initialize OpenAIEmbeddings with the API keyembeddings = OpenAIEmbeddings(openai_api_key=OPENAI_API_KEY)# Connect to MongoDBclient = MongoClient(MONGO_URI)db = client[DB_NAME]collection = db[COLLECTION_NAME]
4.2 步骤2:数据加载和分块
接下来,我们将重点处理作为数据源的PDF文档。文档被加载并拆分为“父”和“子”块,以准备嵌入和向量化。
from langchain.document_loaders import PyPDFLoaderfrom langchain.text_splitter import RecursiveCharacterTextSplitter# Initialize the text splitters for parent and child documentsparent_splitter = RecursiveCharacterTextSplitter(chunk_size=2000)child_splitter = RecursiveCharacterTextSplitter(chunk_size=200)# Function to process PDF document and split it into chunksdef process_pdf(file):loader = PyPDFLoader(file.name)docs = loader.load()parent_docs = parent_splitter.split_documents(docs)# Process parent documentsfor parent_doc in parent_docs:parent_doc_content = parent_doc.page_content.replace('n', ' ')parent_id = collection.insert_one({'document_type': 'parent','content': parent_doc_content}).inserted_id# Process child documentschild_docs = child_splitter.split_documents([parent_doc])for child_doc in child_docs:child_doc_content = child_doc.page_content.replace('n', ' ')child_embedding = embeddings.embed_documents([child_doc_content])[0]collection.insert_one({'document_type': 'child','content': child_doc_content,'embedding': child_embedding,'parent_ref': parent_id})return "PDF processing complete"
4.3 步骤3:查询嵌入和矢量搜索
当提交查询时,我们将其转换为嵌入,并执行向量搜索以找到最相关的子文档,链接回它们的父文档以获取上下文。
# Function to embed a query and perform a vector searchdef query_and_display(query):query_embedding = embeddings.embed_documents([query])[0]# Retrieve relevant child documents based on querychild_docs = collection.aggregate([{"$vectorSearch": {"index": "vector_index","path": "embedding","queryVector": query_embedding,"numCandidates": 10}}])# Fetch corresponding parent documents for additional contextparent_docs = [collection.find_one({"_id": doc['parent_ref']}) for doc in child_docs]return parent_docs, child_docs
4.4 步骤4:通过上下文感知生成响应
在识别出相关文档后,我们为LLM创建一个提示,其中包括用户的查询和匹配文档中的内容。这确保了响应具有信息性和上下文相关性。
from langchain.llms import OpenAI# Initialize the OpenAI clientopenai_client = OpenAI(api_key=OPENAI_API_KEY)# Function to generate a response from the LLMdef generate_response(query, parent_docs, child_docs):response_content = " ".join([doc['content'] for doc in parent_docs if doc])chat_completion = openai_client.chat.completions.create(messages=[{"role": "user", "content": query}],model="gpt-3.5-turbo")return chat_completion.choices[0].message.content
4.5 第五步:串联所有组件
最后,我们将这些元素组合成一个连贯的界面,用户可以在其中上传文档并提出问题。这是使用Gradio实现的,它提供了一种用户友好的方式来与我们先进的RAG系统交互。
with gr.Blocks(css=".gradio-container {background-color: AliceBlue}") as demo:gr.Markdown("Generative AI Chatbot - Upload your file and Ask questions")with gr.Tab("Upload PDF"):with gr.Row():pdf_input = gr.File()pdf_output = gr.Textbox()pdf_button = gr.Button("Upload PDF")with gr.Tab("Ask question"):question_input = gr.Textbox(label="Your Question")answer_output = gr.Textbox(label="LLM Response and Retrieved Documents", interactive=False)question_button = gr.Button("Ask")question_button.click(query_and_display, inputs=[question_input], outputs=answer_output)pdf_button.click(process_pdf, inputs=pdf_input, outputs=pdf_output)demo.launch()
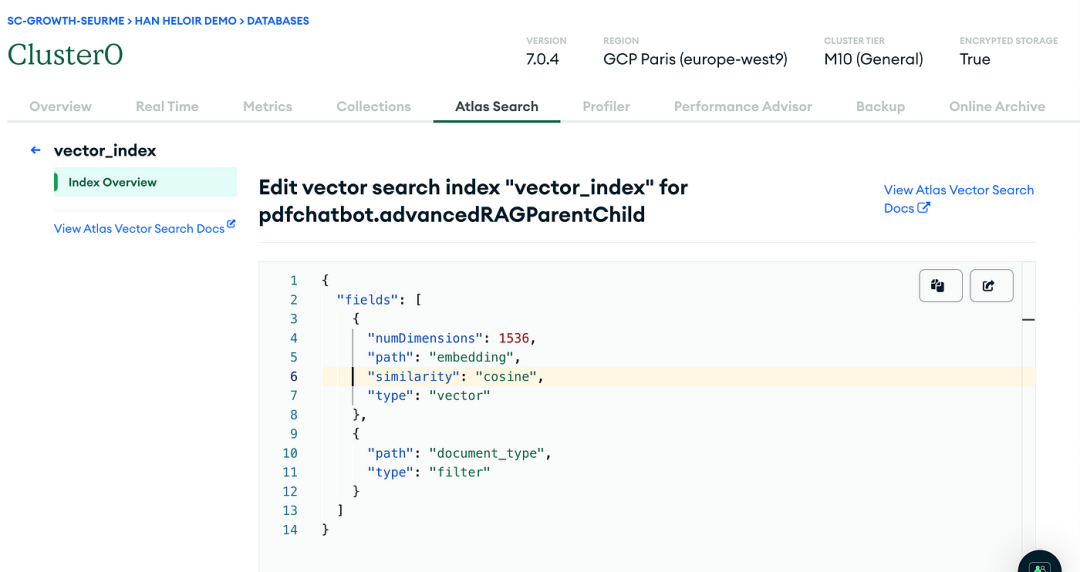
4.6 步骤6:在MongoDB Atlas上创建索引
{"fields": [{"numDimensions": 1536,"path": "embedding","similarity": "cosine","type": "vector"},{"path": "document_type","type": "filter"}]}
参考文献:
[1] https://ai.gopubby.com/byebye-basic-rag-embracing-advanced-retrieval-with-mongodb-vector-search-47b550be2c59
原文地址:https://blog.csdn.net/wshzd/article/details/135426788
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。
如若转载,请注明出处:http://www.7code.cn/show_52732.html
如若内容造成侵权/违法违规/事实不符,请联系代码007邮箱:suwngjj01@126.com进行投诉反馈,一经查实,立即删除!