复制集高可用
复制集选举
MongoDB 的复制集选举使用 Raft 算法(https://raft.github.io/)来实现,选举成功的必要条件是大多数投票节点存活。在具体的实现中,MongoDB 对 raft 协议添加了一些自己的扩展,这包括:
- 支持 chainingAllowed 链式复制,即备节点不只是从主节点上同步数据,还可以选择一个离自己最近(心跳延时最小)的节点来复制数据。
- 增加了预投票阶段,即 preVote,这主要是用来避免网络分区时产生 Term(任期)值激增的问题。
- 支持投票优先级,如果备节点发现自己的优先级比主节点高,则会主动发起投票并尝试成为新的主节点。
一个复制集最多可以有 50 个成员,但只有 7 个投票成员。这是因为一旦过多的成员参与数据复制、投票过程,将会带来更多可靠性方面的问题。
| 投票成员数 | 大多数 | 容忍失效数 |
|---|---|---|
| 1 | 1 | 0 |
| 2 | 2 | 0 |
| 3 | 2 | 1 |
| 4 | 3 | 1 |
| 5 | 3 | 2 |
| 6 | 4 | 2 |
| 7 | 4 | 3 |
当复制集内存活的成员数量不足大多数时,整个复制集将无法选举出主节点,此时无法提供写服务,这些节点都将处于只读状态。此外,如果希望避免平票结果的产生,最好使用奇数个节点成员,比如 3 个或 5 个。当然,在 MongoDB 复制集的实现中,对于平票问题已经提供了解决方案:
- 为选举定时器增加少量的随机时间偏差,这样避免各个节点在同一时刻发起选举,提高成功率。
- 使用仲裁者角色,该角色不做数据复制,也不承担读写业务,仅仅用来投票。
自动故障转移
在故障转移场景中,我们所关心的问题是:
- 备节点是怎么感知到主节点已经发生故障的?
- 如何降低故障转移对业务产生的影响?
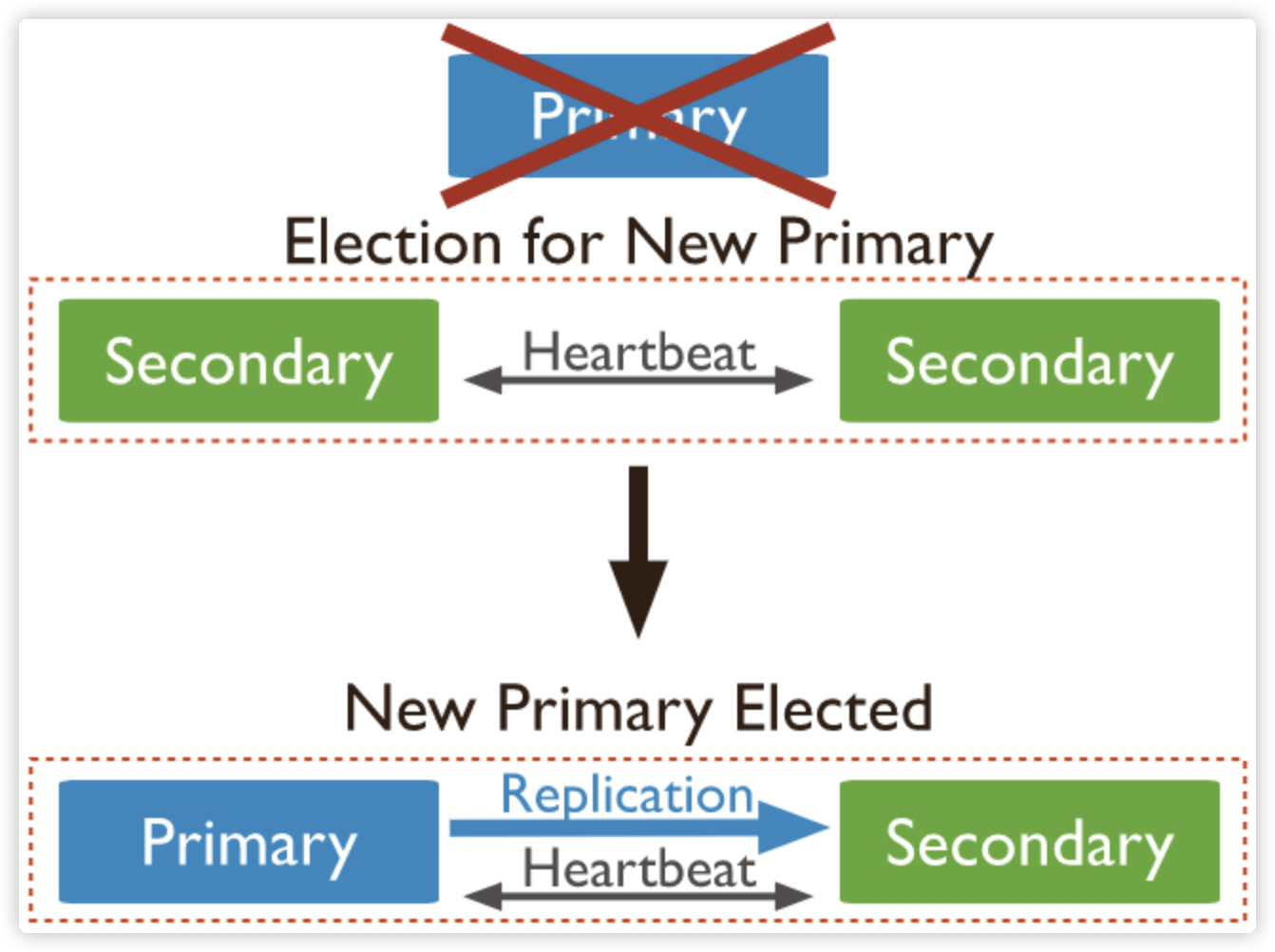
一个影响检测机制的因素是心跳,在复制集组建完成之后,各成员节点会开启定时器,持续向其他成员发起心跳,这里涉及的参数为 heartbeatIntervalMillis,即心跳间隔时间,默认值是 2s。如果心跳成功,则会持续以 2s 的频率继续发送心跳;如果心跳失败,则会立即重试心跳,一直到心跳恢复成功。
另一个重要的因素是选举超时检测,一次心跳检测失败并不会立即触发重新选举。实际上除了心跳,成员节点还会启动一个选举超时检测定时器,该定时器默认以 10s 的间隔执行,具体可以通过 electionTimeoutMillis 参数指定:
- 如果心跳响应成功,则取消上一次的 electionTimeout 调度(保证不会发起选举),并发起新一轮 electionTimeout 调度。
- 如果心跳响应迟迟不能成功,那么 electionTimeout 任务被触发,进而导致备节点发起选举并成为新的主节点。
在 MongoDB 的实现中,选举超时检测的周期要略大于 electionTimeoutMillis 设定。该周期会加入一个随机偏移量,大约在 10~11.5s,如此的设计是为了错开多个备节点主动选举的时间,提升成功率。
因此,在 electionTimeout 任务中触发选举必须要满足以下条件:
(1)当前节点是备节点。
(2)当前节点具备选举权限。
(3)在检测周期内仍然没有与主节点心跳成功。
业务影响评估:
- 在复制集发生主备节点切换的情况下,会出现短暂的无主节点阶段,此时无法接受业务写操作。如果是因为主节点故障导致的切换,则对于该节点的所有读写操作都会产生超时。如果使用 MongoDB 3.6 及以上版本的驱动,则可以通过开启 retryWrite 来降低影响。
# MongoDB Drivers 启用可重试写入
mongodb://localhost/?retryWrites=true
# mongo shell
mongosh --retryWrites
- 如果主节点属于强制掉电,那么整个 Failover 过程将会变长,很可能需要在 Election 定时器超时后才被其他节点感知并恢复,这个时间窗口一般会在 12s 以内。然而实际上,对于业务呼损的考量还应该加上客户端或 mongos 对于复制集角色的监视和感知行为(真实的情况可能需要长达 30s 以上)。
- 对于非常重要的业务,建议在业务层面做一些防护策略,比如设计重试机制。
思考:如何优雅的重启复制集?
如果想不丢数据重启复制集,更优雅的打开方式应该是这样的:
- 逐个重启复制集里所有的 Secondary 节点
- 对 Primary 发送
rs.stepDown()命令,等待 primary 降级为 Secondary - 重启降级后的 Primary
复制集数据同步机制
在复制集架构中,主节点与备节点之间是通过 oplog 来同步数据的,这里的 oplog 是一个特殊的固定集合,当主节点上的一个写操作完成后,会向 oplog 集合写入一条对应的日志,而备节点则通过这个 oplog 不断拉取到新的日志,在本地进行回放以达到数据同步的目的。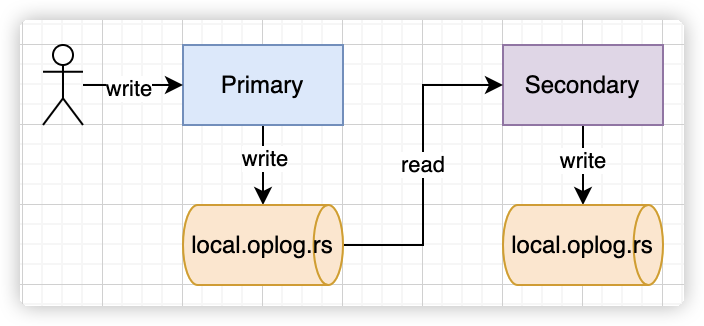
什么是 oplog
- MongoDB oplog 是 Local 库下的一个集合,用来保存写操作所产生的增量日志(类似于 MySQL 中 的 Binlog)。
- 它是一个 Capped Collection(固定集合),即超出配置的最大值后,会自动删除最老的历史数据, MongoDB 针对 oplog 的删除有特殊优化,以提升删除效率。
- 主节点产生新的 oplog Entry,从节点通过复制 oplog 并应用来保持和主节点的状态一致。
查看 oplog
use local
db.oplog.rs.find().sort({$natural:-1}).pretty()
说明:
local.system.replset:用来记录当前复制集的成员。
local.startup_log:用来记录本地数据库的启动日志信息。
local.replset.minvalid:用来记录复制集的跟踪信息,如初始化同步需要的字段。
ts:操作时间,当前 timestamp + 计数器,计数器每秒都被重置
v:oplog 版本信息
op:操作类型
i:插⼊操作
u:更新操作
d:删除操作
c:执行命令(如 createDatabase,dropDatabase)
n:空操作,特殊用途
ns:操作针对的集合
o:操作内容
o2:操作查询条件,仅 update 操作包含该字段
ts 字段描述了oplog 产生的时间戳,可称之为 optime。optime 是备节点实现增量日志同步的关键,它保证了 oplog 是节点有序的,其由两部分组成:
- 当前的系统时间,即 UNIX 时间至现在的秒数,32 位。
- 整数计时器,不同时间值会将计数器进行重置,32 位。
optime 属于 BSON 的 Timestamp 类型,这个类型一般在 MongoDB 内部使用。既然 oplog 保证了节点级有序,那么备节点便可以通过轮询的方式进行拉取,这里会用到可持续追踪的游标(tailable cursor)技术。
每个备节点都分别维护了自己的一个 offset,也就是从主节点拉取的最后一条日志的 optime,在执行同步时就通过这个 optime 向主节点的 oplog 集合发起查询。为了避免不停地发起新的查询链接,在启动第一次查询后可以将 cursor 挂住(通过将 cursor 设置为 tailable)。这样只要 oplog 中产生了新的记录,备节点就能使用同样的请求通道获得这些数据。tailable cursor 只有在查询的集合为固定集合时才允许开启。
oplog 集合的大小
oplog 集合的大小可以通过参数replication.oplogSizeMB设置,对于 64 位系统来说,oplog 的默认值为:
oplogSizeMB = min(磁盘可用空间*5%,50GB)
对于大多数业务场景来说,很难在一开始评估出一个合适的 oplogSize,所幸的是 MongoDB 在 4.0 版本之后提供了 replSetResizeOplog 命令,可以实现动态修改 oplogSize 而不需要重启服务器。
# 将复制集成员的oplog大小修改为60g
db.adminCommand({replSetResizeOplog: 1, size: 60000})
# 查看oplog大小
use local
db.oplog.rs.stats().maxSize
幂等性
每一条 oplog 记录都描述了一次数据的原子性变更,对于 oplog 来说,必须保证是幂等性的。也就是说,对于同一个 oplog,无论进行多少次回放操作,数据的最终状态都会保持不变。某文档 x 字段当前值为 100,用户向 Primary 发送一条{$inc: {x: 1}},记录 oplog 时会转化为一条{$set: {x: 101}的操作,才能保证幂等性。
(1)幂等性的代价
简单元素的操作,$inc 转化为 $set 并没有什么影响,执行开销上也差不多,但当遇到数组元素操作时,情况就不一样了。
测试:
db.coll.insert({_id:1,x:[1,2,3]})
在数组尾部 push 2 个元素,查看 oplog 发现 $push 操作被转换为了 $set 操作(设置数组指定位置的元素为某个值)
rs0:PRIMARY> db.coll.update({_id: 1}, {$push: {x: { $each: [4, 5] }}})
WriteResult({ "nMatched" : 1, "nUpserted" : 0, "nModified" : 1 })
rs0:PRIMARY> db.coll.find()
{ "_id" : 1, "x" : [ 1, 2, 3, 4, 5 ] }
rs0:PRIMARY> use local
switched to db local
rs0:PRIMARY> db.oplog.rs.find({ns:"test.coll"}).sort({$natural:-1}).pretty()
{
"op" : "u",
"ns" : "test.coll",
"ui" : UUID("69c871e8-8f99-4734-be5f-c9c5d8565198"),
"o" : {
"$v" : 1,
"$set" : {
"x.3" : 4,
"x.4" : 5
}
},
"o2" : {
"_id" : 1
},
"ts" : Timestamp(1646223051, 1),
"t" : NumberLong(4),
"v" : NumberLong(2),
"wall" : ISODate("2022-03-02T12:10:51.882Z")
}
$push 转换为带具体位置的 $set 开销上也差不多,但接下来再看看往数组的头部添加 2 个元素
rs0:PRIMARY> use test
switched to db test
rs0:PRIMARY> db.coll.update({_id: 1}, {$push: {x: { $each: [6, 7], $position: 0 }}})
WriteResult({ "nMatched" : 1, "nUpserted" : 0, "nModified" : 1 })
rs0:PRIMARY> db.coll.find()
{ "_id" : 1, "x" : [ 6, 7, 1, 2, 3, 4, 5 ] }
rs0:PRIMARY> use local
switched to db local
rs0:PRIMARY> db.oplog.rs.find({ns:"test.coll"}).sort({$natural:-1}).pretty()
{
"op" : "u",
"ns" : "test.coll",
"ui" : UUID("69c871e8-8f99-4734-be5f-c9c5d8565198"),
"o" : {
"$v" : 1,
"$set" : {
"x" : [
6,
7,
1,
2,
3,
4,
5
]
}
},
"o2" : {
"_id" : 1
},
"ts" : Timestamp(1646223232, 1),
"t" : NumberLong(4),
"v" : NumberLong(2),
"wall" : ISODate("2022-03-02T12:13:52.076Z")
}
可以发现,当向数组的头部添加元素时,oplog 里的 $set 操作不再是设置数组某个位置的值(因为基本所有的元素位置都调整了),而是 $set 数组最终的结果,即整个数组的内容都要写入 oplog。当 push 操作指定了 $slice 或者 $sort 参数时,oplog 的记录方式也是一样的,会将整个数组的内容作为
s
e
t
的参数。
set 的参数。
set的参数。pull、$addToSet 等更新操作符也是类似,更新数组后,oplog 里会转换成 $set 数组的最终内容,才能保证幂等性。
(2)oplog 的写入被放大,导致同步追不上——大数组更新
当数组非常大时,对数组的一个小更新,可能就需要把整个数组的内容记录到 oplog 里,我遇到一个实际的生产环境案例,用户的文档内包含一个很大的数组字段,1000 个元素总大小在 64KB 左右,这个数组里的元素按时间反序存储,新插入的元素会放到数组的最前面(
p
o
s
i
t
i
o
n
:
0
),然后保留数组的前
1000
个元素(
position: 0),然后保留数组的前 1000 个元素(
position:0),然后保留数组的前1000个元素(slice: 1000)。
上述场景导致,Primary 上的每次往数组里插入一个新元素(请求大概几百字节),oplog 里就要记录整个数组的内容,Secondary 同步时会拉取 oplog 并重放,Primary 到 Secondary 同步 oplog 的流量是客户端到 Primary 网络流量的上百倍,导致主备间网卡流量跑满,而且由于 oplog 的量太大,旧的内容很快被删除掉,最终导致 Secondary 追不上,转换为 RECOVERING 状态。
在文档里使用数组时,一定得注意上述问题,避免数组的更新导致同步开销被无限放大的问题。使用数组时,尽量注意:
- 数组的元素个数不要太多,总的大小也不要太大
- 尽量避免对数组进行更新操作
- 如果一定要更新,尽量只在尾部插入元素,复杂的逻辑可以考虑在业务层面上来支持
复制延迟
由于 oplog 集合是有固定大小的,因此存放在里面的 oplog 随时可能会被新的记录冲掉。如果备节点的复制不够快,就无法跟上主节点的步伐,从而产生复制延迟(replication lag)问题。这是不容忽视的,一旦备节点的延迟过大,则随时会发生复制断裂的风险,这意味着备节点的 optime(最新一条同步记录)已经被主节点老化掉,于是备节点将无法继续进行数据同步。
为了尽量避免复制延迟带来的风险,我们可以采取一些措施,比如:
- 增加 oplog 的容量大小,并保持对复制窗口的监视。
- 通过一些扩展手段降低主节点的写入速度。
- 优化主备节点之间的网络。
- 避免字段使用太大的数组(可能导致 oplog 膨胀)。
数据回滚
由于复制延迟是不可避免的,这意味着主备节点之间的数据无法保持绝对的同步。当复制集中的主节点宕机时,备节点会重新选举成为新的主节点。那么,当旧的主节点重新加入时,必须回滚掉之前的一些“脏日志数据”,以保证数据集与新的主节点一致。主备复制集合的差距越大,发生大量数据回滚的风险就越高。
对于写入的业务数据来说,如果已经被复制到了复制集的大多数节点,则可以避免被回滚的风险。应用上可以通过设定更高的写入级别(writeConcern:majority)来保证数据的持久性。这些由旧主节点回滚的数据会被写到单独的 rollback 目录下,必要的情况下仍然可以恢复这些数据。
当 rollback 发生时,MongoDB 将把 rollback 的数据以 BSON 格式存放到 dbpath 路径下 rollback 文件夹中, BSON 文件的命名格式如下:<database>.<collection>.<timestamp>.bson。
mongorestore --host 192.168.192:27018 --db test --collection emp -ufirechou -pfirechou
--authenticationDatabase=admin rollback/emp_rollback.bson
同步源选择
MongoDB 是允许通过备节点进行复制的,这会发生在以下的情况中:
- 在
settings.chainingAllowed开启的情况下,备节点自动选择一个最近的节点(ping 命令时延最小)进行同步。settings.chainingAllowed选项默认是开启的,也就是说默认情况下备节点并不一定会选择主节点进行同步,这个副作用就是会带来延迟的增加,你可以通过下面的操作进行关闭:
cfg = rs.config()
cfg.settings.chainingAllowed = false
rs.reconfig(cfg)
- 使用 replSetSyncFrom 命令临时更改当前节点的同步源,比如在初始化同步时将同步源指向备节点来降低对主节点的影响。
db.adminCommand( { replSetSyncFrom: "hostname:port" })
原文地址:https://blog.csdn.net/u010355502/article/details/135444671
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。
如若转载,请注明出处:http://www.7code.cn/show_52770.html
如若内容造成侵权/违法违规/事实不符,请联系代码007邮箱:suwngjj01@126.com进行投诉反馈,一经查实,立即删除!