1、Pix2Video: Video Editing using Image Diffusion
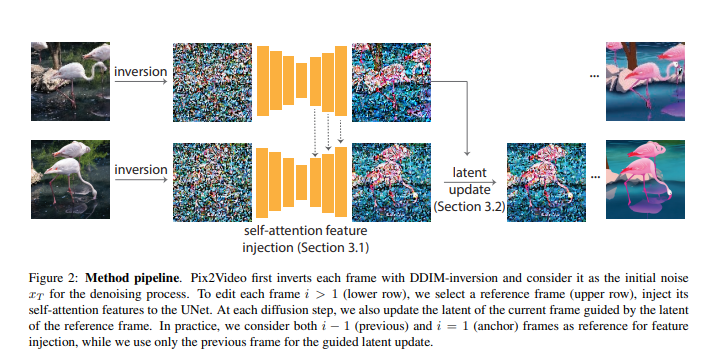
基于大规模图像库训练的图像扩散模型已成为质量和多样性方面最为通用的图像生成模型。它们支持反转真实图像和条件生成(例如,文本生成),使其在高质量图像编辑应用中具有吸引力。本文研究如何利用这些预训练的图像模型进行文本引导的视频编辑。
关键挑战在于在保留源视频内容的同时实现目标编辑。方法分为两个简单的步骤:首先,用预训练的结构引导(例如,深度)图像扩散模型对锚点帧进行文本引导编辑;然后,在关键步骤中,通过将变化逐步传播到未来帧来适应扩散模型的核心去噪步骤,使用自注意力特征注入。然后,在继续处理之前,通过调整帧的潜在编码来巩固这些变化。
方法无需训练,可以推广到各种编辑。通过广泛的实验证明了该方法的有效性,并将其与四种不同的先前和并行努力(在ArXiv上)进行比较。证明实现逼真的文本引导视频编辑是可行的,无需进行任何计算密集的预处理或特定于视频的微调。开源在:https://duyguceylan.github.io/pix2video.github.io/
2、StableVideo: Text-driven Consistency-aware Diffusion Video Editing

扩散方法可生成逼真的图像和视频,但在保持现有对象外观的同时编辑视频中的对象时遇到困难。这阻碍了将扩散模型应用于实际场景中的自然视频编辑。本文通过为现有的文本驱动扩散模型引入时序依赖性来解决这个问题,这使它们能够为编辑后的对象生成一致的外观。
具体来说,开发一种新的帧间传播机制,用于视频编辑,利用分层表示的概念将外观信息从一个帧传播到下一个帧。然后,基于此机制构建了一个基于文本驱动的视频编辑框架,即StableVideo,它可以实现具有一致性意识的视频编辑。大量实验证明方法的强大编辑能力。与最先进的视频编辑方法相比,展示了更好的定性和定量结果。开源在:https://github.com/rese1f/StableVideo
3、Structure and Content-Guided Video Synthesis with Diffusion Models

文本引导的生成扩散模型,为图像的创作和编辑提供了强大的工具。最近一些方法可编辑镜头内容并保留结构,但每次输入都需要昂贵的重新训练,或者依赖于易出错的图像编辑在帧之间的传播。
这项工作提出一种基于结构和内容引导的视频扩散模型,根据所期望输出的描述来编辑视频。由于结构与内容之间的解耦不足,用户提供的内容编辑与结构表示之间会发生冲突。作为解决方案,展示了使用具有不同详细级别的单眼深度估计进行训练可以提供对结构和内容准确性的控制。通过联合视频和图像训练而启用的一种新颖的引导方法,可以对时间一致性进行明确控制。
实验展示了各种成功案例;对输出特征的细粒度控制,基于少量参考图像的定制,以及用户对模型结果的强烈偏好。https://research.runwayml.com/gen1
4、The Power of Sound (TPoS):Audio Reactive Video Generation with Stable Diffusion

视频生成已成为一种重要生成工具,受到极大关注。然而,对于音频到视频生成,很少有考虑,尽管音频具有时间语义和幅度等独特性质。
提出The Power of Sound(TPoS)模型,将包含可变时间语义和幅度的音频输入纳入其中。为生成视频帧,TPoS利用了具有文本语义信息的潜在稳定扩散模型,然后通过预训练的音频编码器产生的顺序音频嵌入进行引导。结果,该方法生成与音频相关的视频内容。
通过各种任务展示了TPoS的有效性,并将其结果与当前音频到视频生成领域的最先进技术进行了比较。开源在:https://ku-vai.github.io/TPoS/
5、Preserve Your Own Correlation: A Noise Prior for Video Diffusion Models
 提出PYoCo,一种大规模文本到视频扩散模型,该模型是从现有的图像生成模型eDiff-I进行微调的,并引入了一种新的视频噪声先验。结合之前的设计选择,包括使用时间注意力、联合图像-视频微调、级联生成架构和专家去噪器的集成,PYoCo在几个基准数据集上建立了新的最先进,优于其他竞争方法的视频生成水平。
提出PYoCo,一种大规模文本到视频扩散模型,该模型是从现有的图像生成模型eDiff-I进行微调的,并引入了一种新的视频噪声先验。结合之前的设计选择,包括使用时间注意力、联合图像-视频微调、级联生成架构和专家去噪器的集成,PYoCo在几个基准数据集上建立了新的最先进,优于其他竞争方法的视频生成水平。
PYoCo能够以卓越的照片真实感和时间一致性实现高质量的零样视频综合能力。项目在:https://research.nvidia.com/labs/dir/pyoco/
6、Text2Video-Zero:Text-to-Image Diffusion Models are Zero-Shot Video Generators

文本到视频生成方法依赖于计算密集型训练,并需要大规模的视频数据集。本文介绍一个新的任务,零样本文本到视频生成,并提出一种低成本的方法(无需任何训练或优化),通过利用现有的文本到图像合成方法,使其适用于视频领域。
关键修改包括:(i)通过动态运动丰富生成帧的潜在编码,以保持全局场景和背景时间的一致性;(ii)重新编程帧级自注意力,使用每一帧对第一帧的新的跨帧注意力,以保留前景对象的上下文、外观和身份。达到了低开销但高质量和非常一致的视频生成。
此外,方法不仅限于文本到视频合成,还适用于其他任务,例如条件和内容专项的视频生成,以及视频指导像素到像素,即指令引导的视频编辑。实验证明,尽管没有在额外的视频数据上训练,方法与最近方法相比具有可比或更好的性能。开源在:https://github.com/Picsart-AI-Research/Text2Video-Zero
7、Tune-A-Video: One-Shot Tuning of Image Diffusion Models for Text-to-Video Generation

为复制文本到图像生成的成功,最近工作采用大规模视频数据集来训练文本到视频生成器。尽管这些方法有着很好的结果,但这种方法计算上是昂贵的。
这项工作提出一种新的文本到视频生成设置——One-Shot Video Tuning,在这种设置下只呈现一个文本到视频对。模型是基于最先进的文本到图像扩散模型,在大规模图像数据上进行预训练的。做出了两个关键观察:1)文本到图像模型可以生成表示动词概念的静态图像;2)扩展文本到图像模型以同时生成多个图像表现出惊人的内容一致性。
为进一步学习连续的运动,引入了调整视频的Tune-A-Video方法,包括一个定制的时空注意机制和一个高效的One-Shot Video Tuning。在推理过程中,用DDIM逆变换来提供采样的结构指导。广泛的定性和定量实验证明了方法在各种应用中的显著能力。开源在:https://tuneavideo.github.io/
关注公众号【机器学习与AI生成创作】,更多精彩等你来读
不是一杯奶茶喝不起,而是我T M直接用来跟进 AIGC+CV视觉 前沿技术,它不香?!
卧剿,6万字!30个方向130篇!CVPR 2023 最全 AIGC 论文!一口气读完
深入浅出stable diffusion:AI作画技术背后的潜在扩散模型论文解读
深入浅出ControlNet,一种可控生成的AIGC绘画生成算法!

最新最全100篇汇总!生成扩散模型Diffusion Models
附下载 |《TensorFlow 2.0 深度学习算法实战》
《礼记·学记》有云:独学而无友,则孤陋而寡闻
点击跟进 AIGC+CV视觉 前沿技术,真香!,加入 AI生成创作与计算机视觉 知识星球!
原文地址:https://blog.csdn.net/lgzlgz3102/article/details/135435062
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。
如若转载,请注明出处:http://www.7code.cn/show_52912.html
如若内容造成侵权/违法违规/事实不符,请联系代码007邮箱:suwngjj01@126.com进行投诉反馈,一经查实,立即删除!





