1、Spark Shuffle过程
1.1MapReduce的Shuffle过程介绍
Shuffle的本义是洗牌、混洗,把一组有一定规则的数据尽量转换成一组无规则的数据,越随机越好。MapReduce中的Shuffle更像是洗牌的逆过程,把一组无规则的数据尽量转换成一组具有一定规则的数据。
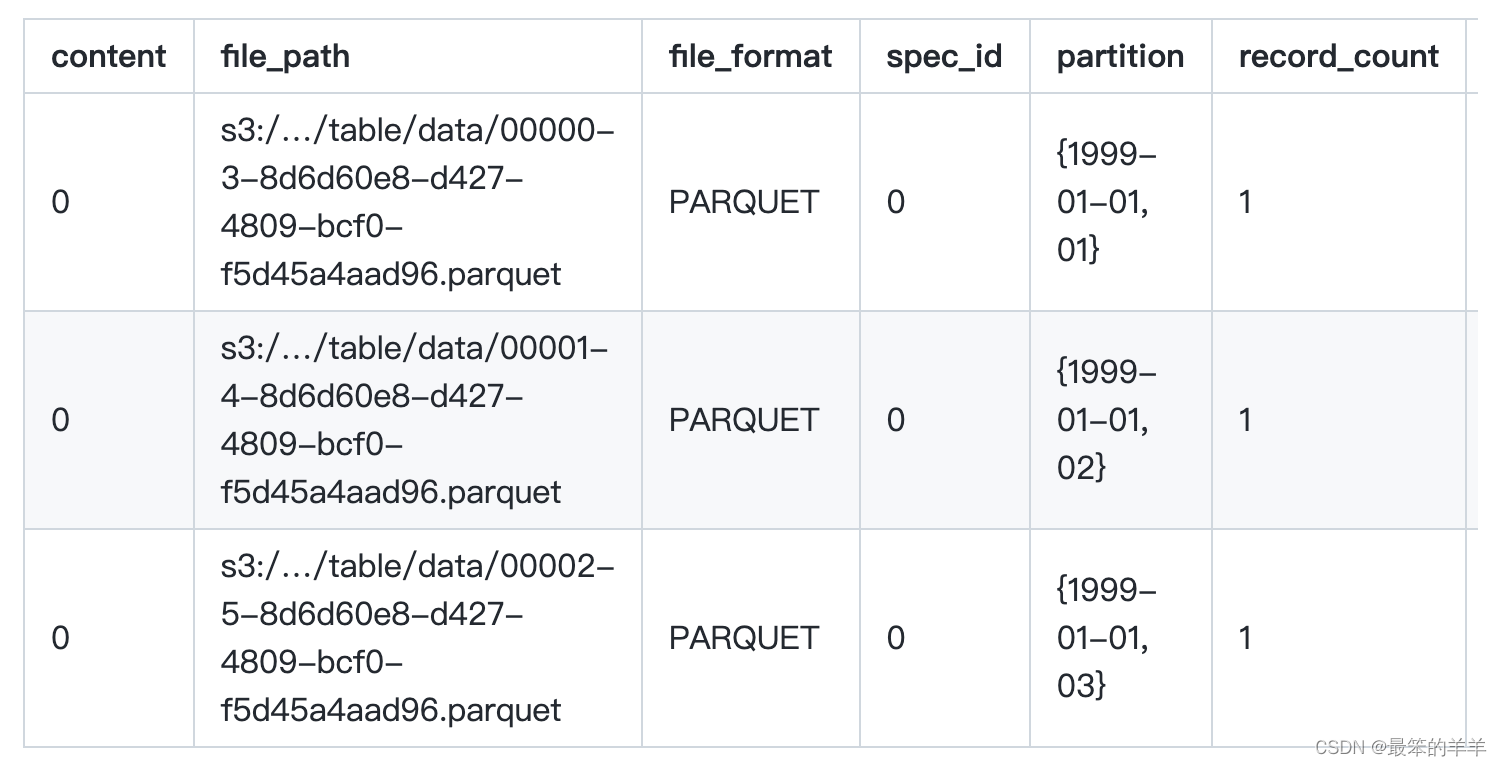
为什么MapReduce计算模型需要Shuffle过程?我们都知道MapReduce计算模型一般包括两个重要的阶段:Map是映射,负责数据的过滤分发;Reduce是规约,负责数据的计算归并。Reduce的数据来源于Map,Map的输出即是Reduce的输入,Reduce需要通过Shuffle来获取数据。
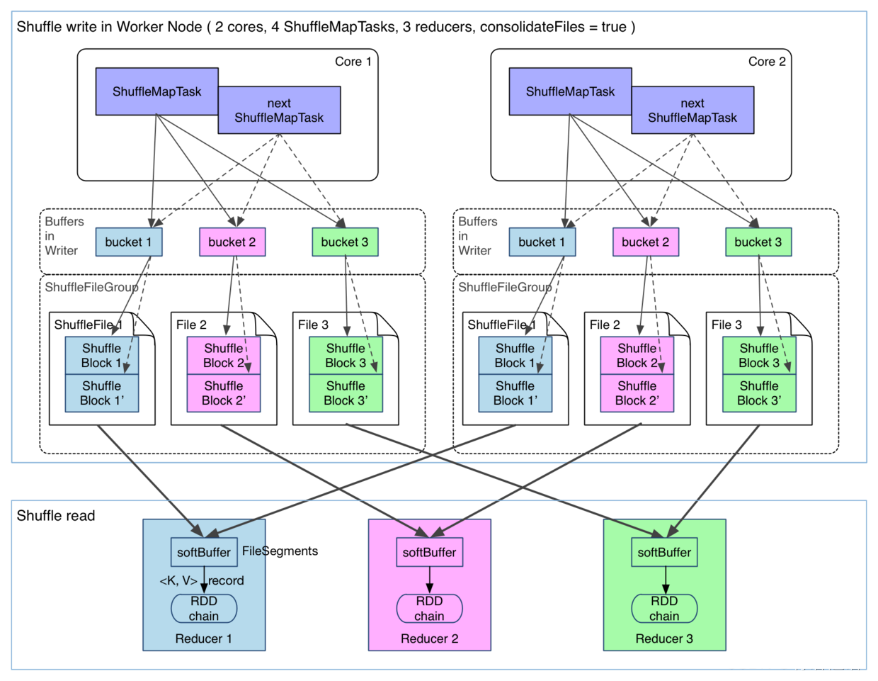
从Map输出到Reduce输入的整个过程可以广义地称为Shuffle。Shuffle横跨Map端和Reduce端,在Map端包括Spill过程,在Reduce端包括copy和sort过程,如图所示:
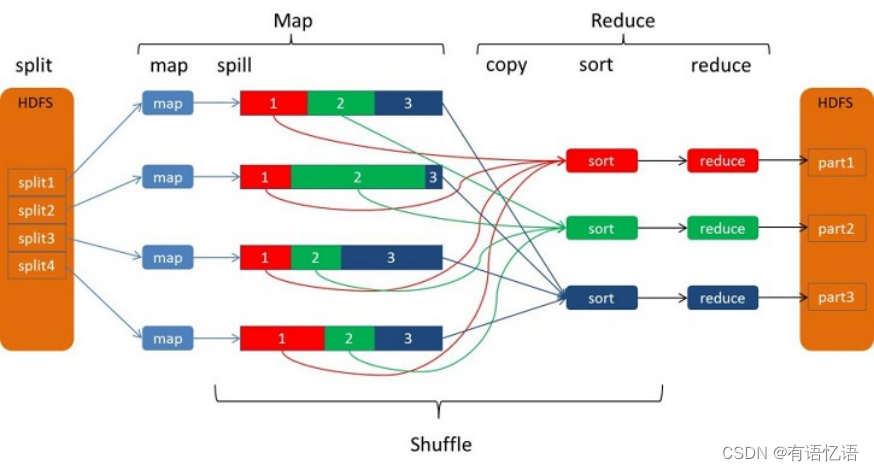
1.1.1Spill过程
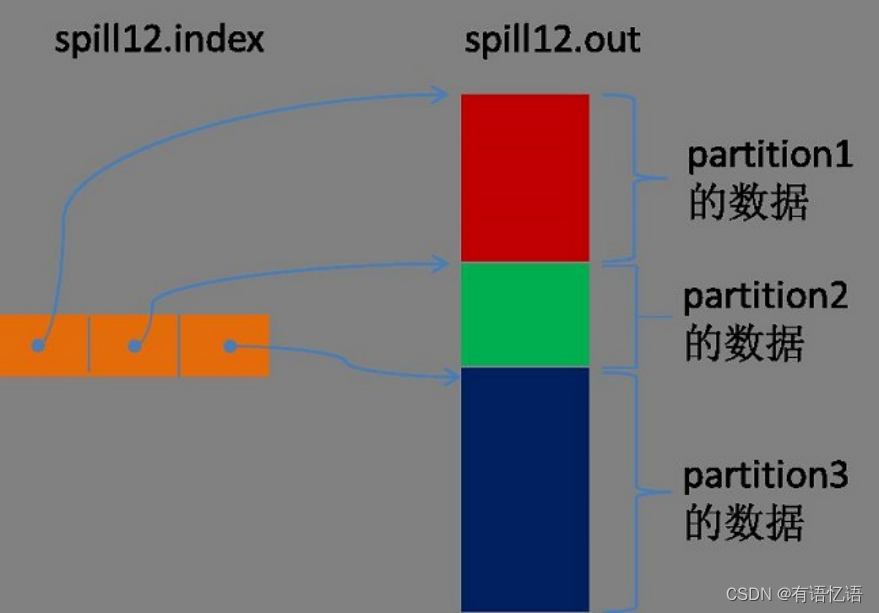
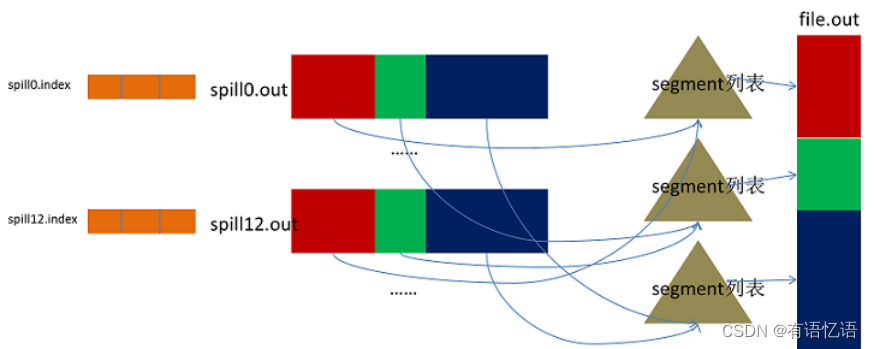
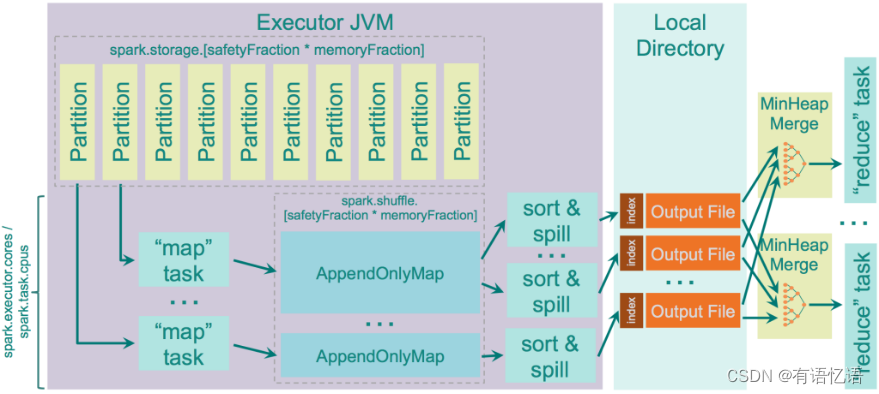
Spill过程包括输出、排序、溢写、合并等步骤,如图所示:
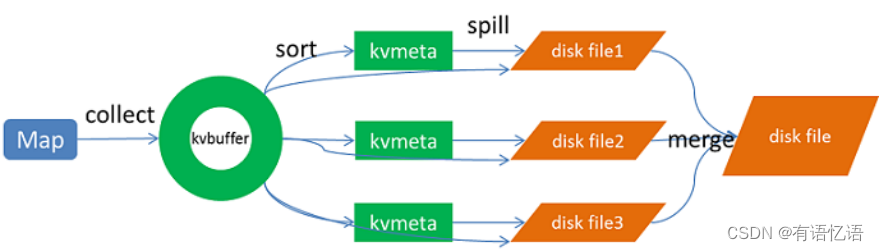
1.1.1.1 Collect
每个Map任务不断地以<key, value>对的形式把数据输出到在内存中构造的一个环形数据结构中。使用环形数据结构是为了更有效地使用内存空间,在内存中放置尽可能多的数据。
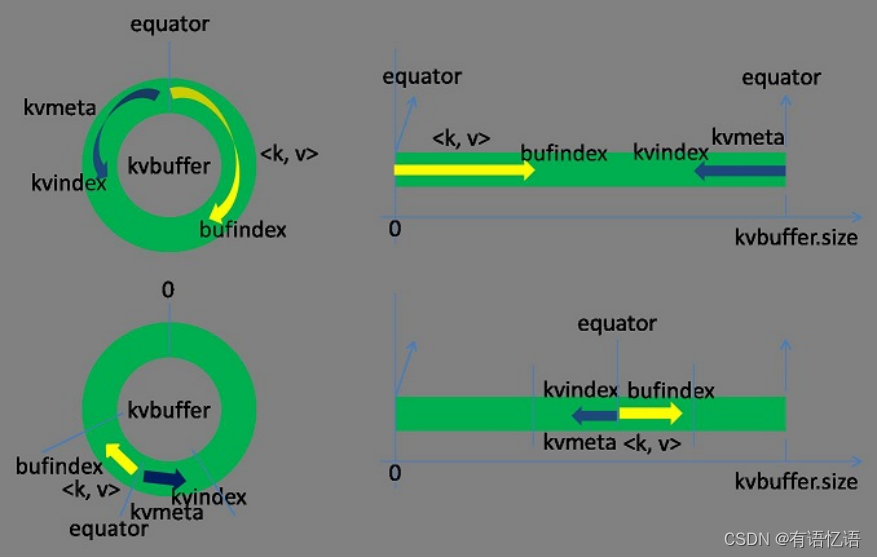
这个数据结构其实就是个字节数组,叫Kvbuffer,名如其义,但是这里面不光放置了<key, value>数据,还放置了一些索引数据,给放置索引数据的区域起了一个Kvmeta的别名,在Kvbuffer的一块区域上穿了一个IntBuffer(字节序采用的是平台自身的字节序)的马甲。<key, value>数据区域和索引数据区域在Kvbuffer中是相邻不重叠的两个区域,用一个分界点来划分两者,分界点不是亘古不变的,而是每次Spill之后都会更新一次。初始的分界点是0,<key, value>数据的存储方向是向上增长,索引数据的存储方向是向下增长,如图所示:
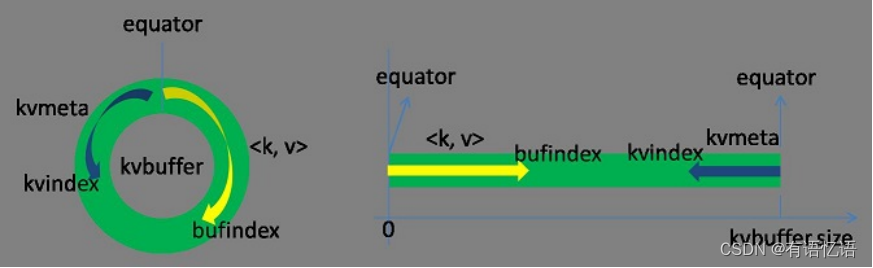
Kvbuffer的存放指针bufindex是一直闷着头地向上增长,比如bufindex初始值为0,一个Int型的key写完之后,bufindex增长为4,一个Int型的value写完之后,bufindex增长为8。
索引是对<key, value>在kvbuffer中的索引,是个四元组,包括:value的起始位置、key的起始位置、partition值、value的长度,占用四个Int长度,Kvmeta的存放指针Kvindex每次都是向下跳四个“格子”,然后再向上一个格子一个格子地填充四元组的数据。比如Kvindex初始位置是-4,当第一个<key, value>写完之后,(Kvindex+0)的位置存放value的起始位置、(Kvindex+1)的位置存放key的起始位置、(Kvindex+2)的位置存放partition的值、(Kvindex+3)的位置存放value的长度,然后Kvindex跳到-8位置,等第二个<key, value>和索引写完之后,Kvindex跳到-32位置。
Kvbuffer的大小虽然可以通过参数设置,但是总共就那么大,<key, value>和索引不断地增加,加着加着,Kvbuffer总有不够用的那天,那怎么办?把数据从内存刷到磁盘上再接着往内存写数据,把Kvbuffer中的数据刷到磁盘上的过程就叫Spill,多么明了的叫法,内存中的数据满了就自动地spill到具有更大空间的磁盘。
关于Spill触发的条件,也就是Kvbuffer用到什么程度开始Spill,还是要讲究一下的。如果把Kvbuffer用得死死得,一点缝都不剩的时候再开始Spill,那Map任务就需要等Spill完成腾出空间之后才能继续写数据;如果Kvbuffer只是满到一定程度,比如80%的时候就开始Spill,那在Spill的同时,Map任务还能继续写数据,如果Spill够快,Map可能都不需要为空闲空间而发愁。两利相衡取其大,一般选择后者。
Spill这个重要的过程是由Spill线程承担,Spill线程从Map任务接到“命令”之后就开始正式干活,干的活叫SortAndSpill,原来不仅仅是Spill,在Spill之前还有个颇具争议性的Sort。
1.1.1.2 Sort
先把Kvbuffer中的数据按照partition值和key两个关键字升序排序,移动的只是索引数据,排序结果是Kvmeta中数据按照partition为单位聚集在一起,同一partition内的按照key有序。