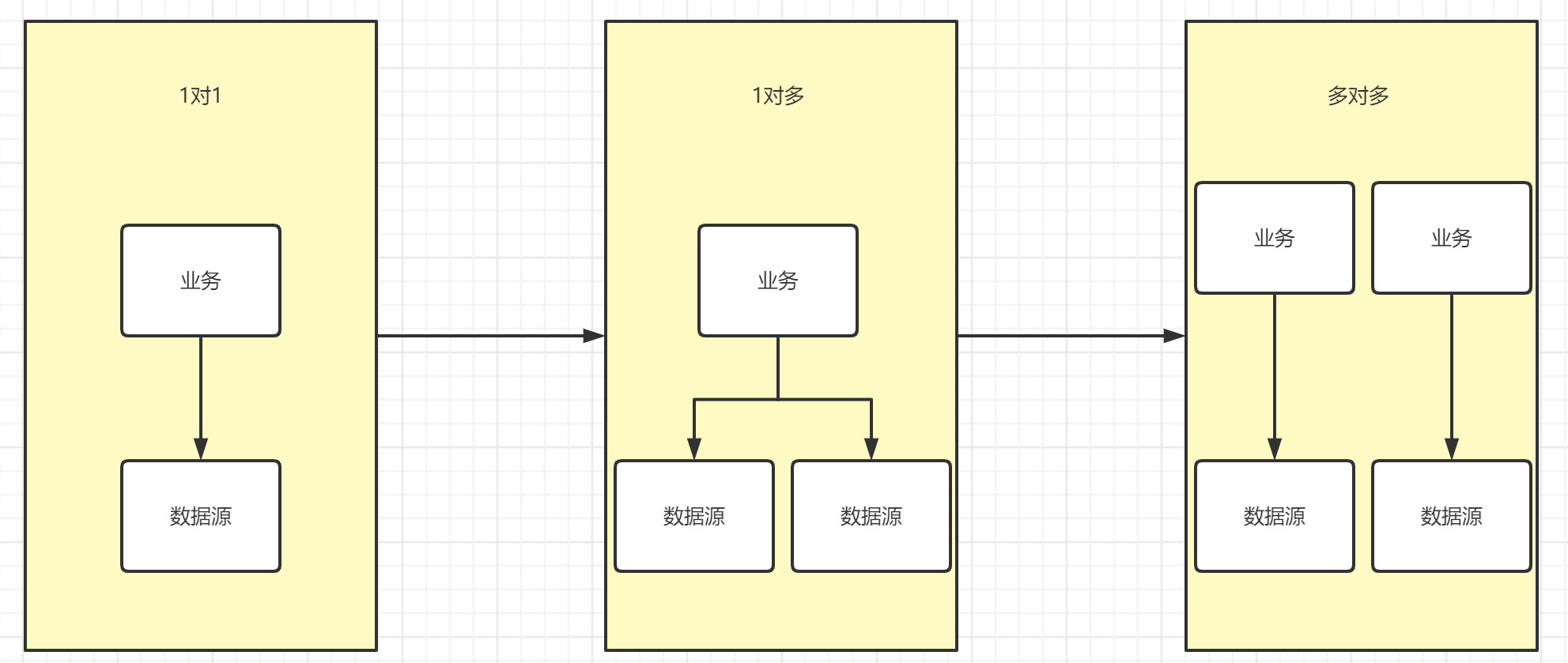
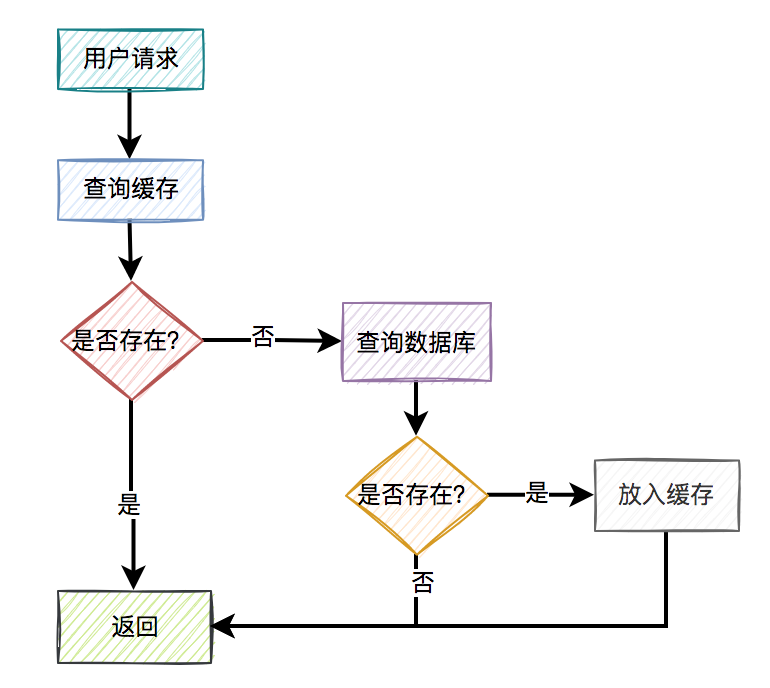
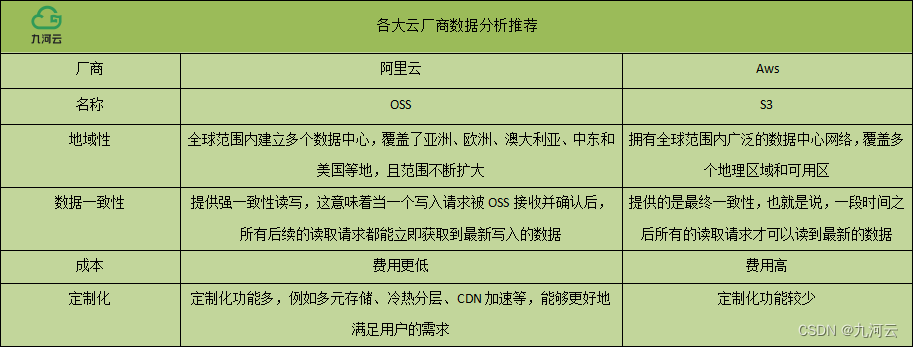
数据一致性问题是如何产生的?
数据一致性问题通常产生于数据在不同的时间点、地点或系统中存在多个副本的情况,
系统只存在一个副本的情况下也完全可能会产生。
设想一下,你在一家连锁咖啡店有一张会员卡这张会员卡可以绑定两个账号(假设是微信号),这张卡记录了你的积分。
你在北京的分店购买了一杯拿铁,积分增加了5分。就是这么巧,同一时间,你的好朋友在上海的分店也买了一杯拿铁,积分也增加了5分。
按理来说用这张卡买了两杯咖啡,系统上应该给你增加10分,但是,如果北京分店的系统更新到中央数据库的操作延迟了,
上海分店的系统可能还没有得到最新的积分信息。
这时,上海分店计算总积分的方式就是:原来的总积分 + 5分,北京的分店的计算方式也是:原来的总积分 + 5分,这张卡总的就加了5分,这就是一种数据一致性问题。
即使在单个系统内部,也可能存在类似的问题。
假设咖啡店的积分记录系统在进行维护,而你在这个时间点进行了消费。
如果维护操作和积分更新操作没有被正确的协调,可能会导致你的消费没有被记录到积分中,引发数据一致性问题。
在上面这个例子中,数据一致性问题是由于信息更新在不同地点之间同步不及时造成的,而在单个系统中,
可能是因为操作的顺序和同步机制没有设计得当导致一致性问题。
解决这类问题通常需要引入事务管理、分布式锁、队列、事件驱动的更新机制等策略来确保数据的准确性和实时性。
迪米特法则
在软件架构设计中,遵循的原则是尽量保持简洁和避免不必要的复杂性,
这个原则被称作 “最少知识原则” (Principle of Least Knowledge),也被称为 “迪米特法则” (Law of Demeter)。
当它和架构设计中的简约原则联系起来时,你可能指的是 “简单性原则” 或 “奥卡姆剃刀”(Occam’s Razor) 原则。
奥卡姆剃刀原则通常被解释为在没有明显差别的情况下,应该选择假设较少、假设简单的理论。