由于FileStore底层仍然通过操作系统自带的本地文件系统管理磁盘,所以为了能够使用本地文件系统,所有针对RADOS的操作都需要转换成POSIX语义。
所以引入了BlueStore直接管理文件。
1.设计原理
文件系统提供的核心操作就是读和写,BlueStore也是。
对于文件系统,读操作除非缓存命中,否则都是从磁盘读出数据;而对于写操作,一般都是写入内存即可应答,再由文件系统合适组织写入磁盘,以此达到加速写性能。
但由于内存掉电数据会丢失,为了保证可靠性,BlueStore采用日志、双写来加速写操作,也就是先写入缓存NVRAM或者SSD,再写入磁盘。
BlueStore引入日志后,接踵而来的问题是,NVRAM或者SSD可以充当缓存的原因是I/O时延非常低,但是对于海量数据的写入,时延已经不是瓶颈,数据传输的时间才是瓶颈,所以当有海量数据写操作时,写日志虽然写进缓存很快,但是仍有大部分时间消耗给数据传输,再由于双写,性能损失反而更加严重。
所以BlueStore的写操作采用首尾块非对齐部分采用写日志RMW策略,中间对齐的大部分数据采用重定向写COW策略
BlueStore提供的读写API的粒度是PG,读是并发的,写是排他的。也就是同一时间两个线程可以同步执行读同一个PG的数据,但是只能互斥写同一个PG。
读请求是同步的,但出于效率考虑,写请求是异步的,所以对每一个PG还有一个FIFO队列OpSequencer来给写请求保序。
同步异步的意思是线程没有读完会阻塞,没有写完不会阻塞。
2.磁盘数据结构
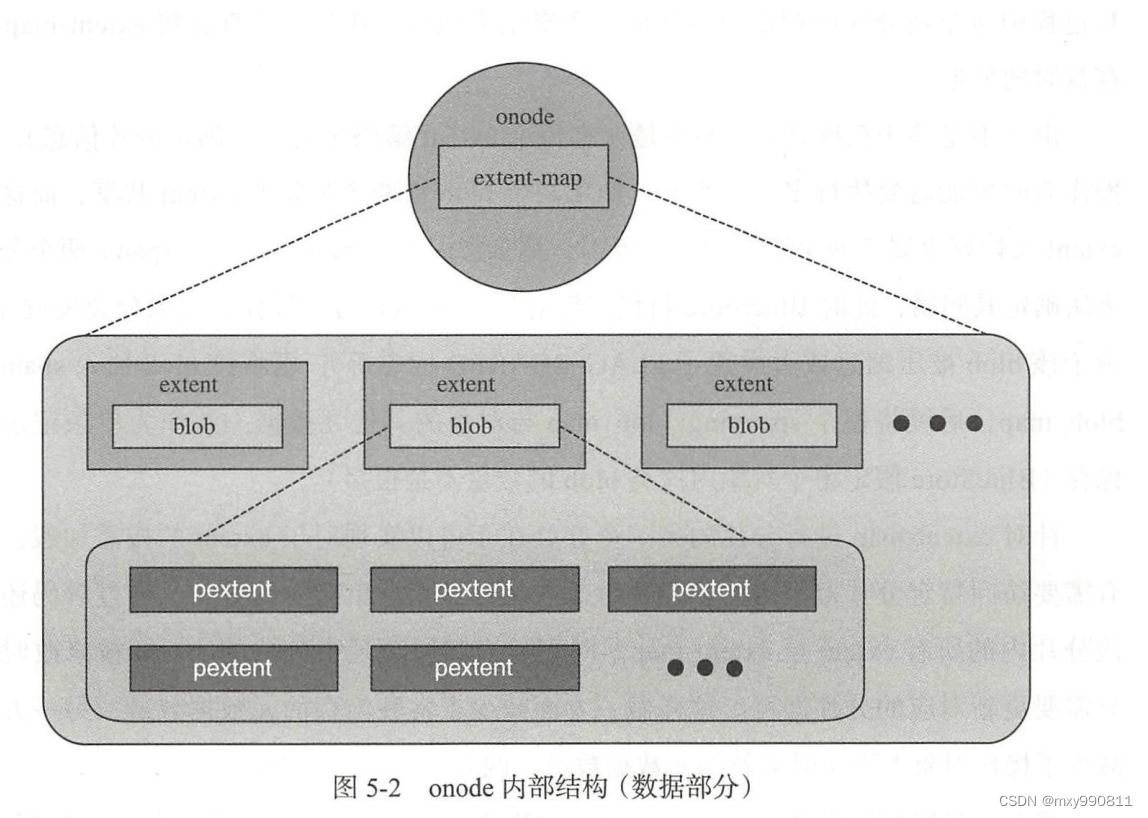
BlueStore的对象类似于文件,我们知道文件是依靠每个文件专属的元数据inode记录了本文件的大小、文件数据所在的扇区地址等信息。BlueStore的元数据结构叫onode,也是记录了对象大小和数据位置等信息,具体如下:

其中size是对象大小、而extent_map_shards则记录了extent-map在RocksDB数据库的索引,也就是说每个对象有一个onode,onode包含了一张extent-map,而extent-map很大所以存储在数据库中。
extent-map记录了对象数据在磁盘的地址。extent-map具体如下:

其中extent_map包含了对象的若干个逻辑数据段extent(每个逻辑段并不一定连续且与磁盘块对齐)。
extent具体如下:

其中blob记录了该逻辑段对应的磁盘物理段。
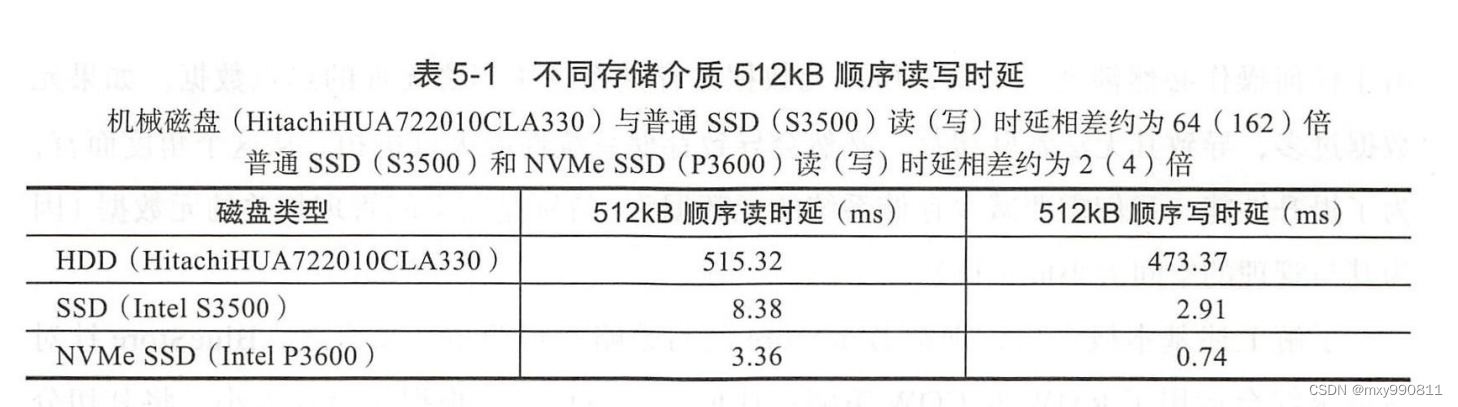
blob_offset用于逻辑段extent的强制对齐,从而方便了映射磁盘物理段:
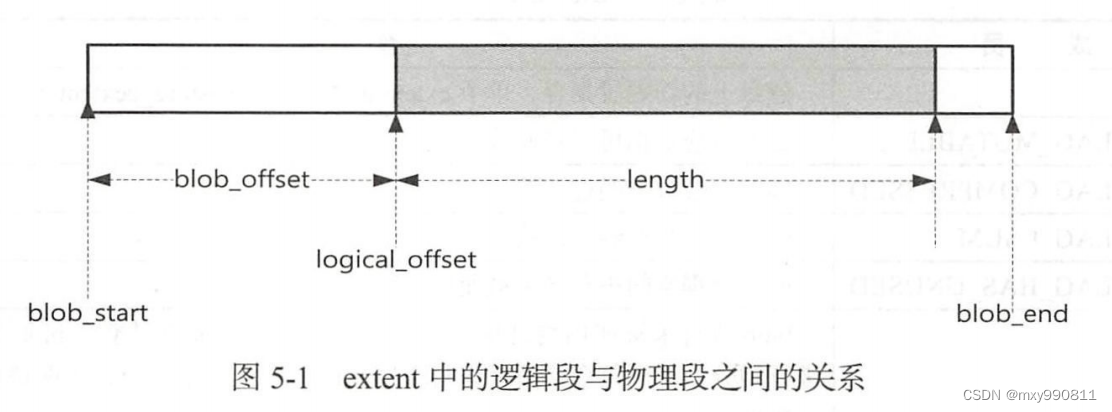
blob结构具体如下:
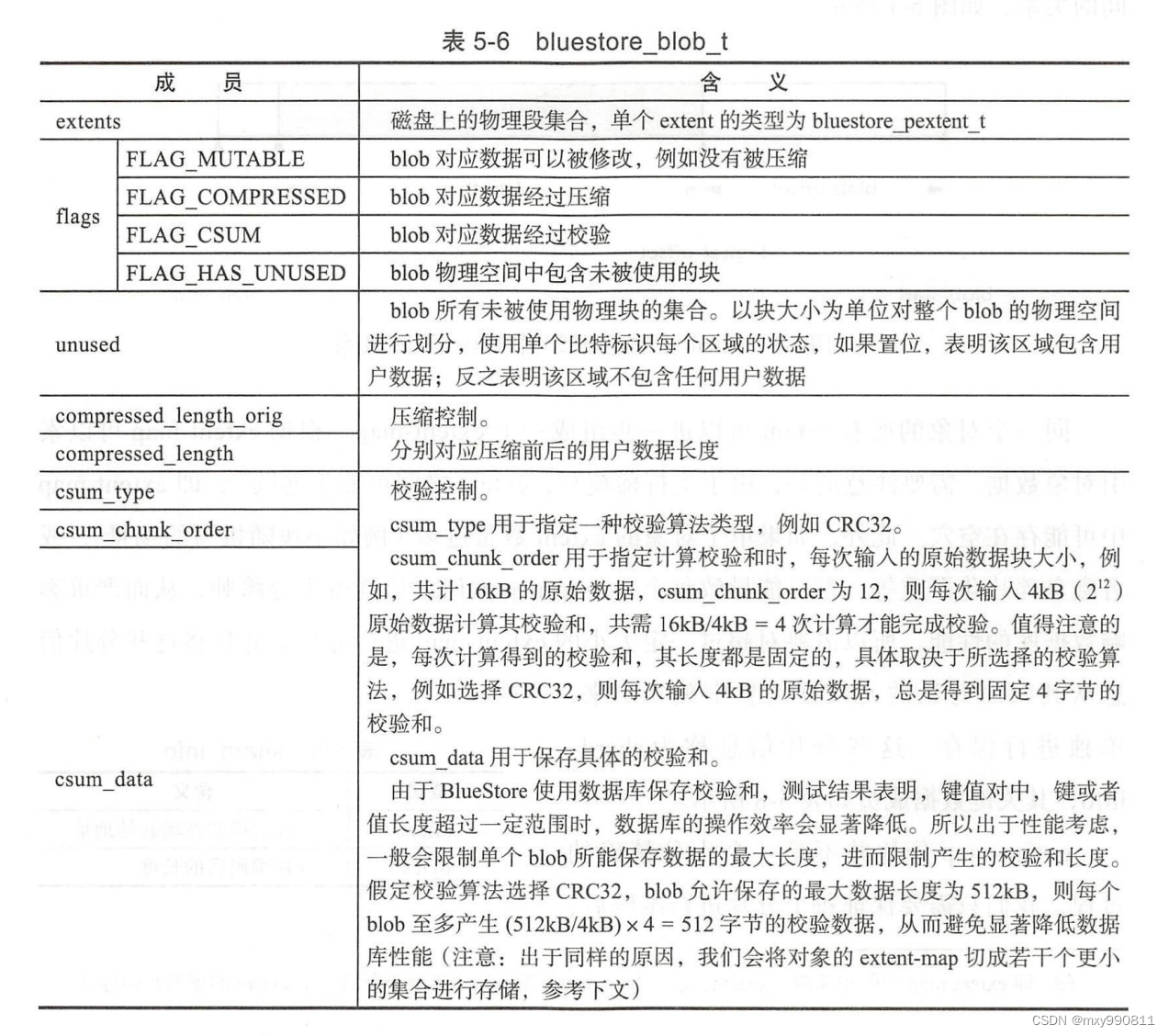
由于每个逻辑段extent在物理磁盘上并不一定连续,属于逻辑段和物理段是一对多的关系,所以表中extents记录了多个物理段pextent。
pextent结构具体如下:

上述的offset、length一定是块的整数倍。
整体结构图如下:
3.缓存机制
缓存替换算法本质是对于未来的读写请求序列,依靠时空局部性原理进行预测,因此如果请求序列完全随机,那么任何算法不可避免存在误淘汰的可能。
BlueStore需要缓存的元数据有两种,Collection和Onode,分别对应PG上下文与对象上下文内存管理结构。Collection小巧故常驻内存。
所以BlueStore需要缓存的数据只有Onode和用户数据。
BlueStore针对Onode采用LRU缓存替换算法、针对用户数据采用2Q。共四个队列。2Q有三个(A1in、Am、A1out)
4.BlueStore的磁盘空间管理
对于文件系统而言,除了元数据inode,还需要磁盘空间管理系统【位图】来管理磁盘的空闲块,比如每次追加写文件,文件需要扩容,那么就需要向位图申请磁盘块,再将磁盘块块号记录于该文件元数据inode中,再完成写入操作。
对于现代海量存储场景,一个bit表示一个扇区的做法,会导致位图过大,1.3PB的磁盘空间需要300GB内存,这使得位图无法常驻内存,不适用于集中式存储系统,因此有了段管理。一个段两个成员offset、length,128位就可以表示一大段磁盘空间。
由于Ceph是分布式的,并且Ceph的定位面向SSD,比HDD有更大的基本块,所以,BlueStore默认采用位图管理磁盘
对于文件系统,已分配磁盘块和空闲块是对立的,已知一种便可以恢复另一种。
由于已分配磁盘块在onode中已经详细记录,所以BlueStore将空闲块列表用数据库存盘,BlueStore上电后通过加载空闲块列表,最终还原出已分配空间列表。(虽然onode也在数据库,但是onode不仅仅记录了已分配块信息,非常庞大)。
上述空闲块列表即FreelistManager,还原出的已分配空间列表即Allocator(常驻内存用于分配空闲块,响应磁盘块请求)。
4.1 BitmapFreelistManager
BitmapFreelistManager将数量固定,物理上连续的磁盘块组成一个段,从而将磁盘空间划分为若干连续的段管理。每个段以磁盘起始地址为编号,故在BlueStore实例内为唯一索引,单个块用一个比特表示状态,所以每个段是一段比特流。
由于使用数据库存储段信息,段大小设置过大或者过小都不利于充分发挥数据库性能
4.2 BitmapAllocator
BitmapAllocator具体如下:
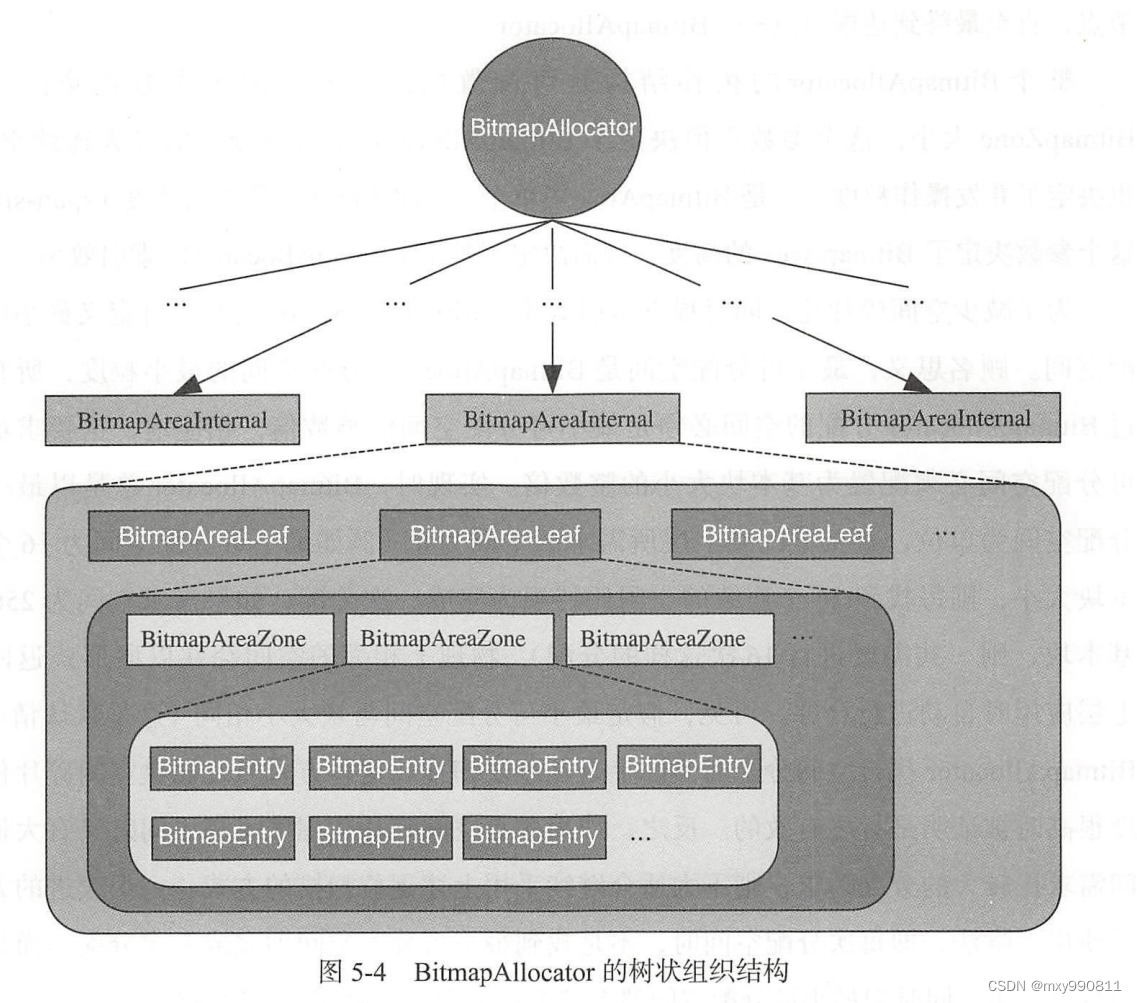
每一个BitmapEntry可以是64位位图,管理64个基本块。
BitmapAreaZone是BitmapAllocator单次最大可分配单位,大小可配置,所有API是原子的,因此不同的BitmapAreaZone之间可以并发操作。
BitmapAreaLeaf是叶子节点,包含固定数量的BitmapAreaZone,为了提升索引效率可以在往上组若干层BitmapAreaInternal。
整个BitmapAllocator的拓扑结构是可以配置的,主要受两个参数的约束:一是BitmapAreaZone的大小,决定了单次可分配最大连续空间,也决定了并发操作粒度;二是单个节点(中间或叶子)的跨度(span-size),这个参数决定了树的高度,从而决定了索引的效率。
为了减少空间碎片化,同时提升索引效率,BitmapAllocator还可以自定义配置最小可分配空间,所有BitmapAllocator分配的空间必须是最小可分配空间整数倍。
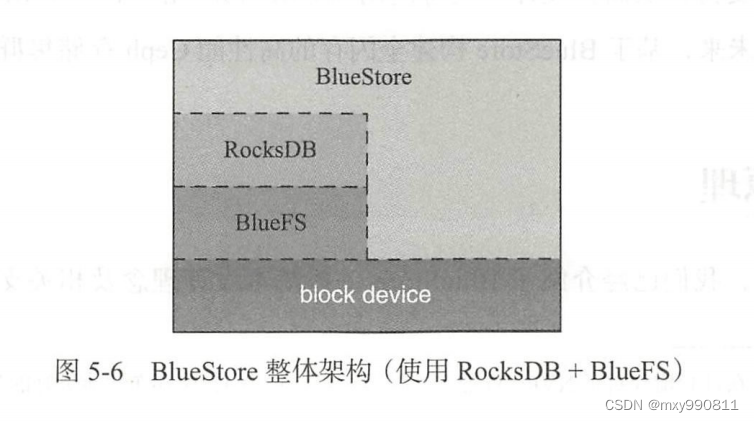
5.BlueFS
RocksDB具有以下特点:
1)专为使用本地SSD设备作为存储后端且存储容量不超过几个TB的应用程序设计,是一种内嵌式的非分布式数据库。
2)适合于存储小型或者中型键值对;性能随键值对长度上升下降很快。
3)性能随CPU核数以及后端存储设备的I/O能力呈线性扩展
由于RocksDB设计理念与BlueStore高度一致,所以BlueStore默认使用RocksDB作为元数据存储引擎。
但是由于操作系统自带的本地文件系统(例如XFS、ext3、ext4、ZFS等)对RocksDB而言很多不是必须,所以需要对本地文件系统进行剪裁,所以BlueFS应运而生。
BlueFS是一个简易的用户态日志型文件系统,将BlueStore分成了三个层次:
1)慢速(Slow)空间:这类空间主要用于存储对象数据,可有普通大容量机械磁盘提供,由BlueStore自行管理。
2)高速(DB)空间:这类空间主要用于存储BlueStore内部产生的元数据(如onode、双写的日志(这个我猜的))由RocksDB最终通过BlueFS直接管理。
3)超高速(WAL)空间:这类空间主要用于存储RocksDB内部产生的.log文件。可由NVMe SSD或NVRAM等时延相较普通SSD更小的设备充当,容量需求和2)相当(实际上还取决于RocksDB相关参数设置)。超高速空间也有BlueFS直接管理
整个Ceph有四个Allocator,一个是BlueStore管理慢速空间的Allocator,剩下三个是BlueFS管理慢速(当做高速、超高速)、高速、超高速空间的Allocator
BlueFS也允许慢速空间当做高速、超高速空间。具体策略为:BlueStore通过自身周期性被唤醒的同步线程实时查询BlueFS的可用空间,如果BlueFS可用空间占比过小,则分配一些慢速空间,反之的回收一部分慢速空间。成功分配给BlueFS的空间段单独写入bluefs_extents的集合,并从自身的Allocator扣除。每次更新bluefs_extents后,BlueStore都会将其作为元数据存盘,后续BlueFS上电时,通过BlueStore传递预先从数据库加载的bluefs_extents,即可正确初始化BlueFS的高速、超高速空间的Allocator。
6.BlueFS的磁盘数据结构
BlueFS也采用层级结构,但是由于只用于存储BlueStore的元数据,所以只有扁平的两层,第一层目录绝对路径,第二层文件,结构如下:
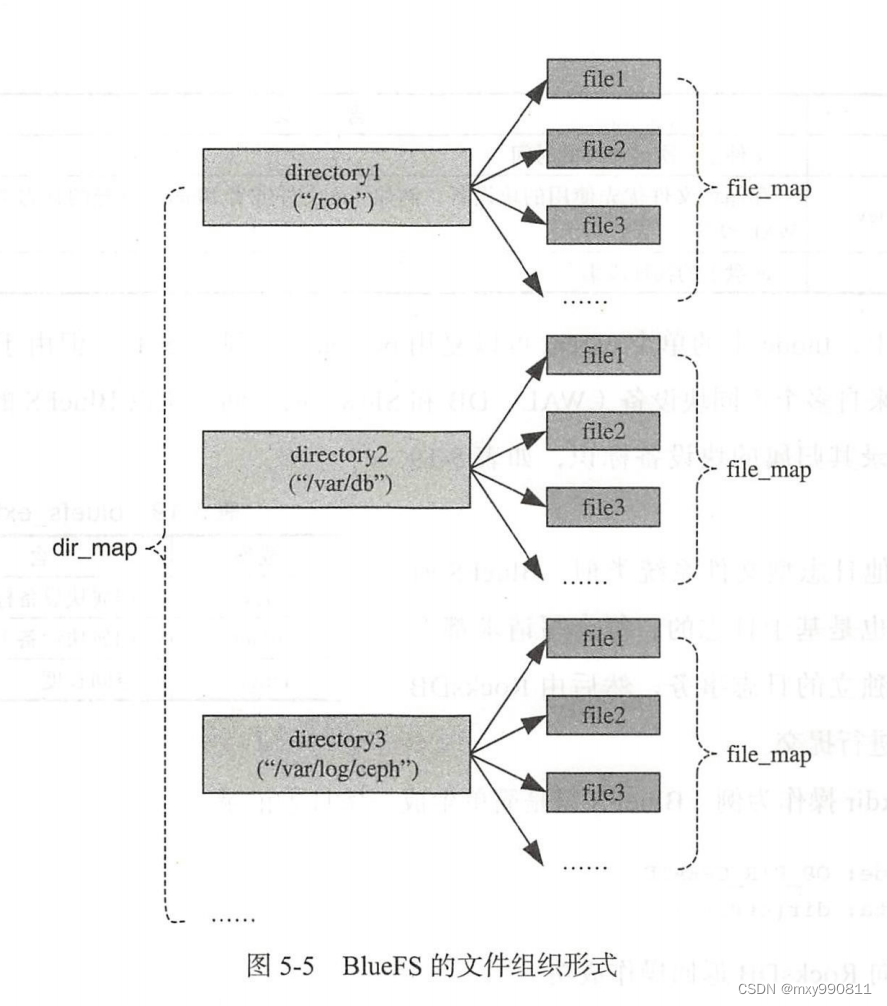
BlueFS的文件也采用类似inode的结构来管理,叫做bluefs_fnode_t简称fnode,file_map是文件名和fnode的映射。fnode结构如下:


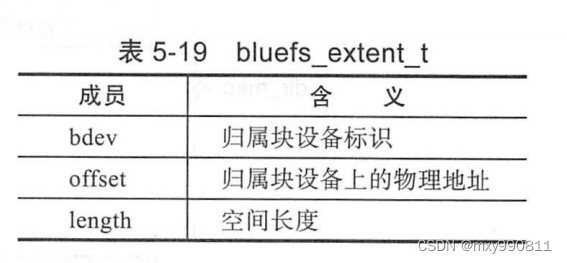
每个文件可能来自多个不同的块空间(WAL、DB、Slow),所以extent还需要额外记录归属块设备标识。
BlueFS是日志型文件系统,每次操作只会记录一个简单的日志即向RocksDB返回操作成功。BlueFS采用增量日志模式,随着时间增加,隔一段时间需要将日志压缩成一个独立的日志事务,来节省WAL设备空间,日志事务结构如下:

所以每隔一段时间,BlueFS会将增量日志进行合并化简,然后将剩余的多条日志编码成op_bl作为一个日志事务,BlueFS下次上电,重放这个日志事务,就可以还原出完整最新的dir_map和file_map。
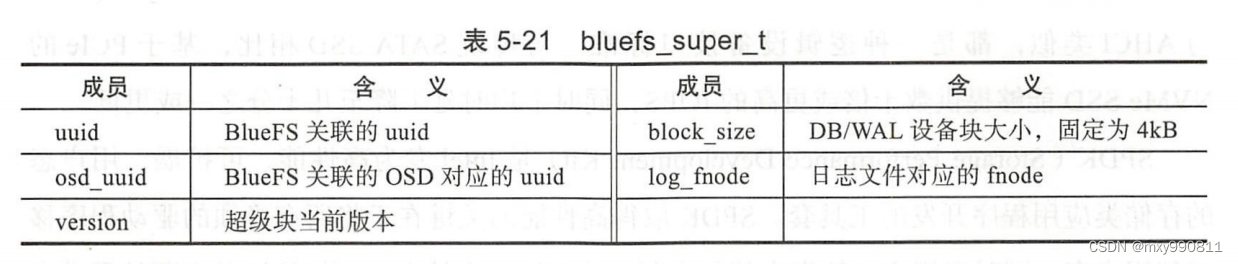
由于日志事务也是一个文件,所以需要一个超级块来记录日志文件位置,这样挂载BlueFS即读入超级块后,就可以恢复BlueFS的dir_map和file_map以供用户查看。超级块结构如下:
BlueFS整体架构如下:
原文地址:https://blog.csdn.net/mxy990811/article/details/135391397
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。
如若转载,请注明出处:http://www.7code.cn/show_53886.html
如若内容造成侵权/违法违规/事实不符,请联系代码007邮箱:suwngjj01@126.com进行投诉反馈,一经查实,立即删除!




