本文介绍: 双向 编码器加上mask做完形填空超大模型无监督预训练 需要整个模型作为pretrain weight到下游任务做fintune总结个毛。
不会写的很详细,只是为了帮助我理解在CV领域transformer的拓展
1 摘要
1.1 BERT – 核心
双向 编码器 加上mask做完形填空超大模型无监督预训练 需要整个模型作为pretrain weight到下游任务做fintune
1.2 GPT – 核心
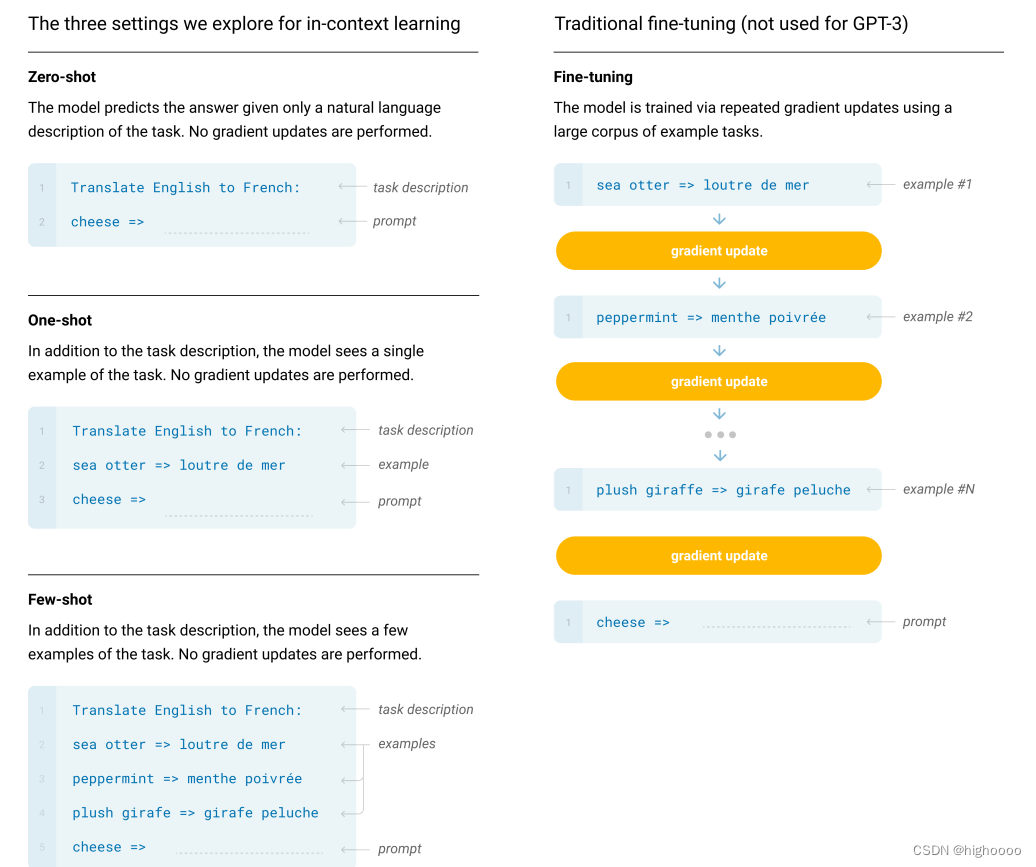
自回归 解码器 无需训练 只需Prompt
2 模型架构
2.1 概览
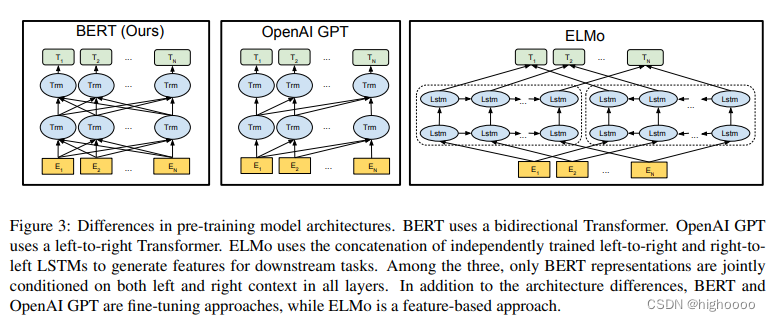
3 区别
3.1 finetune和prompt
BERT需要全部参数进行训练
GPT不需要训练即可完成下游任务
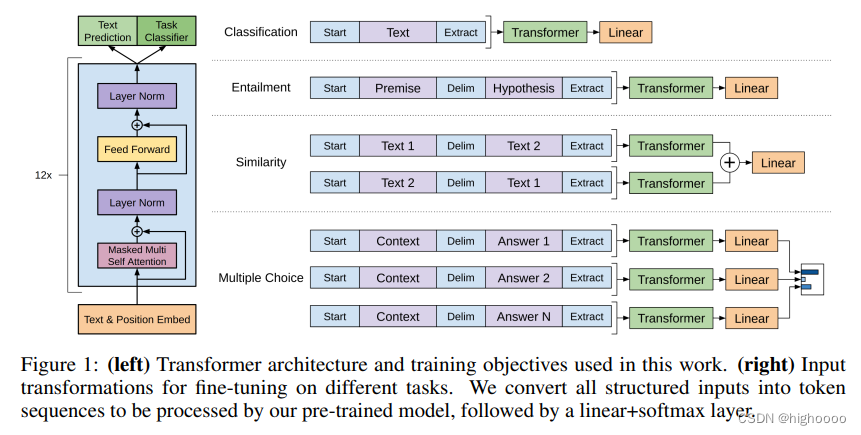
3.2 transformer及训练
BERT使用双向的编码器
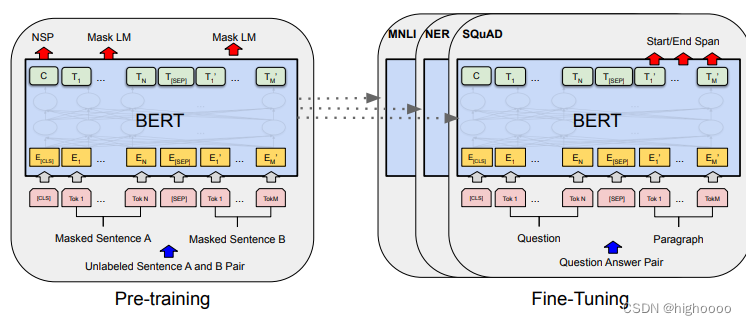

总结
声明:本站所有文章,如无特殊说明或标注,均为本站原创发布。任何个人或组织,在未征得本站同意时,禁止复制、盗用、采集、发布本站内容到任何网站、书籍等各类媒体平台。如若本站内容侵犯了原著者的合法权益,可联系我们进行处理。






