第五章:高档和低档的 TDD
原文:5: TDD in High Gear and Low Gear
译者:飞龙
我们引入了服务层来捕获我们从工作应用程序中需要的一些额外的编排责任。服务层帮助我们清晰地定义我们的用例以及每个用例的工作流程:我们需要从我们的存储库中获取什么,我们应该进行什么预检和当前状态验证,以及我们最终保存了什么。
但目前,我们的许多单元测试是在更低的级别上操作,直接作用于模型。在本章中,我们将讨论将这些测试提升到服务层级别涉及的权衡以及一些更一般的测试准则。
我们的测试金字塔看起来怎么样?
让我们看看将这一举措转向使用服务层及其自己的服务层测试对我们的测试金字塔有何影响:
测试类型计数
$ grep -c test_ test_*.py
tests/unit/test_allocate.py:4
tests/unit/test_batches.py:8
tests/unit/test_services.py:3
tests/integration/test_orm.py:6
tests/integration/test_repository.py:2
tests/e2e/test_api.py:2
不错!我们有 15 个单元测试,8 个集成测试,只有 2 个端到端测试。这已经是一个看起来很健康的测试金字塔了。
领域层测试应该移动到服务层吗?
让我们看看如果我们再进一步会发生什么。由于我们可以针对服务层测试我们的软件,我们实际上不再需要对领域模型进行测试。相反,我们可以将第一章中的所有领域级测试重写为服务层的术语:
在服务层重写领域测试(tests/unit/test_services.py)
# domain-layer test:
def test_prefers_current_stock_batches_to_shipments():
in_stock_batch = Batch("in-stock-batch", "RETRO-CLOCK", 100, eta=None)
shipment_batch = Batch("shipment-batch", "RETRO-CLOCK", 100, eta=tomorrow)
line = OrderLine("oref", "RETRO-CLOCK", 10)
allocate(line, [in_stock_batch, shipment_batch])
assert in_stock_batch.available_quantity == 90
assert shipment_batch.available_quantity == 100
# service-layer test:
def test_prefers_warehouse_batches_to_shipments():
in_stock_batch = Batch("in-stock-batch", "RETRO-CLOCK", 100, eta=None)
shipment_batch = Batch("shipment-batch", "RETRO-CLOCK", 100, eta=tomorrow)
repo = FakeRepository([in_stock_batch, shipment_batch])
session = FakeSession()
line = OrderLine('oref', "RETRO-CLOCK", 10)
services.allocate(line, repo, session)
assert in_stock_batch.available_quantity == 90
assert shipment_batch.available_quantity == 100
为什么我们要这样做呢?
测试应该帮助我们无畏地改变我们的系统,但通常我们看到团队对其领域模型编写了太多测试。当他们来改变他们的代码库时,这会导致问题,并发现他们需要更新数十甚至数百个单元测试。
如果停下来思考自动化测试的目的,这是有道理的。我们使用测试来强制系统的某个属性在我们工作时不会改变。我们使用测试来检查 API 是否继续返回 200,数据库会话是否继续提交,以及订单是否仍在分配。
如果我们意外更改了其中一个行为,我们的测试将会失败。另一方面,如果我们想要更改代码的设计,任何直接依赖于该代码的测试也将失败。
随着我们深入了解本书,您将看到服务层如何形成我们系统的 API,我们可以以多种方式驱动它。针对此 API 进行测试可以减少我们在重构领域模型时需要更改的代码量。如果我们限制自己只针对服务层进行测试,我们将没有任何直接与模型对象上的“私有”方法或属性交互的测试,这使我们更自由地对其进行重构。
提示
我们在测试中放入的每一行代码都像是一团胶水,将系统保持在特定的形状中。我们拥有的低级别测试越多,改变事物就会越困难。
关于决定编写何种测试
您可能会问自己,“那我应该重写所有的单元测试吗?针对领域模型编写测试是错误的吗?” 要回答这些问题,重要的是要理解耦合和设计反馈之间的权衡(见图 5-1)。

图 5-1:测试谱
[ditaa, apwp_0501]
| Low feedback High feedback |
| Low barrier to change High barrier to change |
| High system coverage Focused coverage |
| |
| <--------- ----------> |
| |
| API Tests Service-Layer Tests Domain Tests |
极限编程(XP)敦促我们“倾听代码”。当我们编写测试时,我们可能会发现代码很难使用或注意到代码味道。这是我们进行重构并重新考虑设计的触发器。
然而,只有当我们与目标代码密切合作时才能获得这种反馈。针对 HTTP API 的测试对我们的对象的细粒度设计毫无帮助,因为它处于更高的抽象级别。
另一方面,我们可以重写整个应用程序,只要我们不更改 URL 或请求格式,我们的 HTTP 测试就会继续通过。这使我们有信心进行大规模的更改,比如更改数据库架构,不会破坏我们的代码。
在另一端,我们在第一章中编写的测试帮助我们充分了解我们需要的对象。测试引导我们设计出一个合理的、符合领域语言的设计。当我们的测试以领域语言阅读时,我们感到我们的代码与我们对问题解决的直觉相匹配。
因为测试是用领域语言编写的,它们充当我们模型的活文档。新团队成员可以阅读这些测试,快速了解系统的工作原理以及核心概念的相互关系。
我们经常通过在这个级别编写测试来“勾勒”新的行为,以查看代码可能的外观。然而,当我们想要改进代码的设计时,我们将需要替换或删除这些测试,因为它们与特定实现紧密耦合。
高档和低档
大多数情况下,当我们添加新功能或修复错误时,我们不需要对领域模型进行广泛的更改。在这些情况下,我们更喜欢针对服务编写测试,因为耦合度较低,覆盖范围较高。
例如,当编写add_stock函数或cancel_order功能时,我们可以通过针对服务层编写测试来更快地进行工作,并减少耦合。
当开始一个新项目或遇到一个特别棘手的问题时,我们会回到对领域模型编写测试,这样我们就能更好地得到反馈和我们意图的可执行文档。
我们使用的比喻是换挡。在开始旅程时,自行车需要处于低档位,以克服惯性。一旦我们开始跑,我们可以通过换到高档位来更快、更有效地行驶;但如果我们突然遇到陡峭的山坡或被危险迫使减速,我们再次降到低档位,直到我们可以再次加速。
将服务层测试与领域完全解耦
我们在服务层测试中仍然直接依赖于领域,因为我们使用领域对象来设置我们的测试数据并调用我们的服务层函数。
为了使服务层与领域完全解耦,我们需要重写其 API,以基本类型的形式工作。
我们的服务层目前接受一个OrderLine领域对象:
之前:allocate 接受一个领域对象(service_layer/services.py)
def allocate(line: OrderLine, repo: AbstractRepository, session) -> str:
如果它的参数都是基本类型,它会是什么样子?
之后:allocate 接受字符串和整数(service_layer/services.py)
def allocate(
orderid: str, sku: str, qty: int, repo: AbstractRepository, session
) -> str:
我们也用这些术语重写了测试:
测试现在在函数调用中使用基本类型(tests/unit/test_services.py)
def test_returns_allocation():
batch = model.Batch("batch1", "COMPLICATED-LAMP", 100, eta=None)
repo = FakeRepository([batch])
result = services.allocate("o1", "COMPLICATED-LAMP", 10, repo, FakeSession())
assert result == "batch1"
但是我们的测试仍然依赖于领域,因为我们仍然手动实例化Batch对象。因此,如果有一天我们决定大规模重构我们的Batch模型的工作方式,我们将不得不更改一堆测试。
缓解:将所有领域依赖项保留在固定装置函数中
我们至少可以将其抽象为测试中的一个辅助函数或固定装置。以下是一种你可以做到这一点的方式,即在FakeRepository上添加一个工厂函数:
固定装置的工厂函数是一种可能性(tests/unit/test_services.py)
class FakeRepository(set):
@staticmethod
def for_batch(ref, sku, qty, eta=None):
return FakeRepository([
model.Batch(ref, sku, qty, eta),
])
...
def test_returns_allocation():
repo = FakeRepository.for_batch("batch1", "COMPLICATED-LAMP", 100, eta=None)
result = services.allocate("o1", "COMPLICATED-LAMP", 10, repo, FakeSession())
assert result == "batch1"
至少这将把我们所有测试对领域的依赖放在一个地方。
添加一个缺失的服务
不过,我们可以再进一步。如果我们有一个添加库存的服务,我们可以使用它,并使我们的服务层测试完全按照服务层的官方用例来表达,消除对领域的所有依赖:
测试新的 add_batch 服务(tests/unit/test_services.py)
def test_add_batch():
repo, session = FakeRepository([]), FakeSession()
services.add_batch("b1", "CRUNCHY-ARMCHAIR", 100, None, repo, session)
assert repo.get("b1") is not None
assert session.committed
提示
一般来说,如果你发现自己需要在服务层测试中直接进行领域层操作,这可能表明你的服务层是不完整的。
而实现只是两行代码:
为 add_batch 添加一个新服务(service_layer/services.py)
def add_batch(
ref: str, sku: str, qty: int, eta: Optional[date],
repo: AbstractRepository, session,
):
repo.add(model.Batch(ref, sku, qty, eta))
session.commit()
def allocate(
orderid: str, sku: str, qty: int, repo: AbstractRepository, session
) -> str:
...
注意
你应该仅仅因为它有助于从你的测试中移除依赖而写一个新的服务吗?可能不。但在这种情况下,我们几乎肯定会在某一天需要一个add_batch服务。
现在我们可以纯粹地用服务本身来重写所有我们的服务层测试,只使用原语,而不依赖于模型:
服务测试现在只使用服务(tests/unit/test_services.py)
def test_allocate_returns_allocation():
repo, session = FakeRepository([]), FakeSession()
services.add_batch("batch1", "COMPLICATED-LAMP", 100, None, repo, session)
result = services.allocate("o1", "COMPLICATED-LAMP", 10, repo, session)
assert result == "batch1"
def test_allocate_errors_for_invalid_sku():
repo, session = FakeRepository([]), FakeSession()
services.add_batch("b1", "AREALSKU", 100, None, repo, session)
with pytest.raises(services.InvalidSku, match="Invalid sku NONEXISTENTSKU"):
services.allocate("o1", "NONEXISTENTSKU", 10, repo, FakeSession())
这真是一个很好的地方。我们的服务层测试只依赖于服务层本身,让我们完全自由地根据需要重构模型。
将改进带入端到端测试
就像添加add_batch帮助我们将服务层测试与模型解耦一样,添加一个 API 端点来添加批次将消除对丑陋的add_stock装置的需求,我们的端到端测试可以摆脱那些硬编码的 SQL 查询和对数据库的直接依赖。
由于我们的服务函数,添加端点很容易,只需要一点 JSON 处理和一个函数调用:
用于添加批次的 API(entrypoints/flask_app.py)
@app.route("/add_batch", methods=['POST'])
def add_batch():
session = get_session()
repo = repository.SqlAlchemyRepository(session)
eta = request.json['eta']
if eta is not None:
eta = datetime.fromisoformat(eta).date()
services.add_batch(
request.json['ref'], request.json['sku'], request.json['qty'], eta,
repo, session
)
return 'OK', 201
注意
你是否在想,向*/add_batch发 POST 请求?这不太符合 RESTful!你是对的。我们很随意,但如果你想让它更符合 RESTful,也许是向/batches*发 POST 请求,那就尽管去做吧!因为 Flask 是一个薄适配器,所以很容易。参见下一个侧边栏。
而且我们在 conftest.py 中的硬编码 SQL 查询被一些 API 调用所取代,这意味着 API 测试除了 API 之外没有任何依赖,这也很好:
API 测试现在可以添加自己的批次(tests/e2e/test_api.py)
def post_to_add_batch(ref, sku, qty, eta):
url = config.get_api_url()
r = requests.post(
f'{url}/add_batch',
json={'ref': ref, 'sku': sku, 'qty': qty, 'eta': eta}
)
assert r.status_code == 201
@pytest.mark.usefixtures('postgres_db')
@pytest.mark.usefixtures('restart_api')
def test_happy_path_returns_201_and_allocated_batch():
sku, othersku = random_sku(), random_sku('other')
earlybatch = random_batchref(1)
laterbatch = random_batchref(2)
otherbatch = random_batchref(3)
post_to_add_batch(laterbatch, sku, 100, '2011-01-02')
post_to_add_batch(earlybatch, sku, 100, '2011-01-01')
post_to_add_batch(otherbatch, othersku, 100, None)
data = {'orderid': random_orderid(), 'sku': sku, 'qty': 3}
url = config.get_api_url()
r = requests.post(f'{url}/allocate', json=data)
assert r.status_code == 201
assert r.json()['batchref'] == earlybatch
总结
一旦你有了一个服务层,你真的可以将大部分的测试覆盖移到单元测试,并且建立一个健康的测试金字塔。
一些事情将会帮助你:
-
用原语而不是领域对象来表达你的服务层。
-
在理想的世界里,你将拥有所有你需要的服务,能够完全针对服务层进行测试,而不是通过存储库或数据库来修改状态。这在你的端到端测试中也会得到回报。
进入下一章!
¹ 关于在更高层编写测试的一个有效担忧是,对于更复杂的用例,可能会导致组合爆炸。在这些情况下,降级到各种协作领域对象的低级单元测试可能会有用。但也参见第八章和“可选:使用虚假消息总线单独测试事件处理程序”。
第六章:工作单元模式
译者:飞龙
在本章中,我们将介绍将存储库和服务层模式联系在一起的最后一块拼图:工作单元模式。
如果存储库模式是我们对持久存储概念的抽象,那么工作单元(UoW)模式就是我们对原子操作概念的抽象。它将允许我们最终完全将服务层与数据层解耦。
图 6-1 显示,目前我们的基础设施层之间存在大量的通信:API 直接与数据库层交互以启动会话,它与存储库层交互以初始化SQLAlchemyRepository,并且它与服务层交互以请求分配。
提示
本章的代码位于 GitHub 的 chapter_06_uow 分支中(https://oreil.ly/MoWdZ):
git clone https://github.com/cosmicpython/code.git
cd code
git checkout chapter_06_uow
# or to code along, checkout Chapter 4:
git checkout chapter_04_service_layer
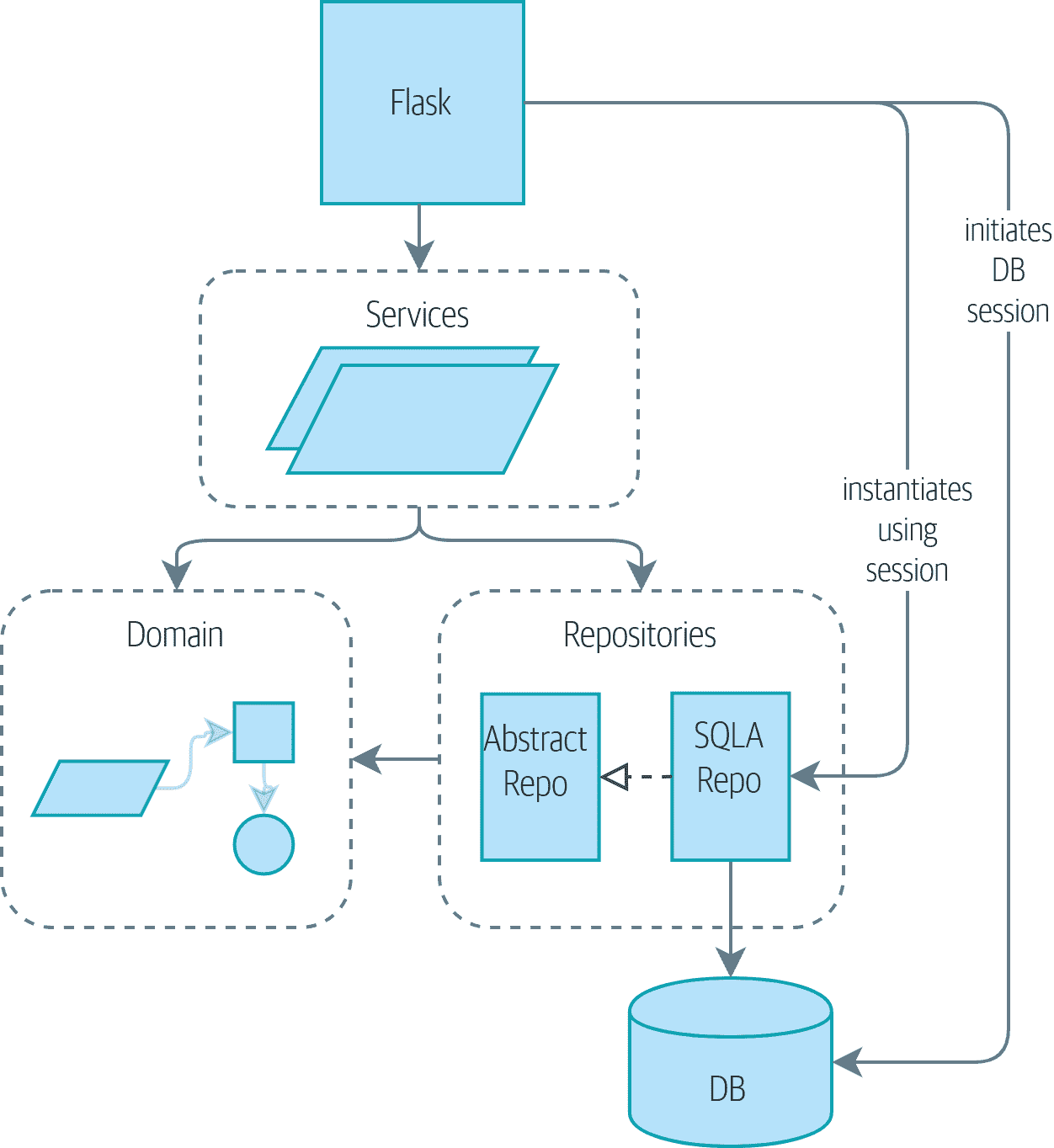
图 6-1:没有 UoW:API 直接与三层交互
图 6-2 显示了我们的目标状态。Flask API 现在只执行两件事:初始化工作单元,并调用服务。服务与 UoW 合作(我们喜欢认为 UoW 是服务层的一部分),但服务函数本身或 Flask 现在都不需要直接与数据库交互。
我们将使用 Python 语法的一个可爱的部分,即上下文管理器。
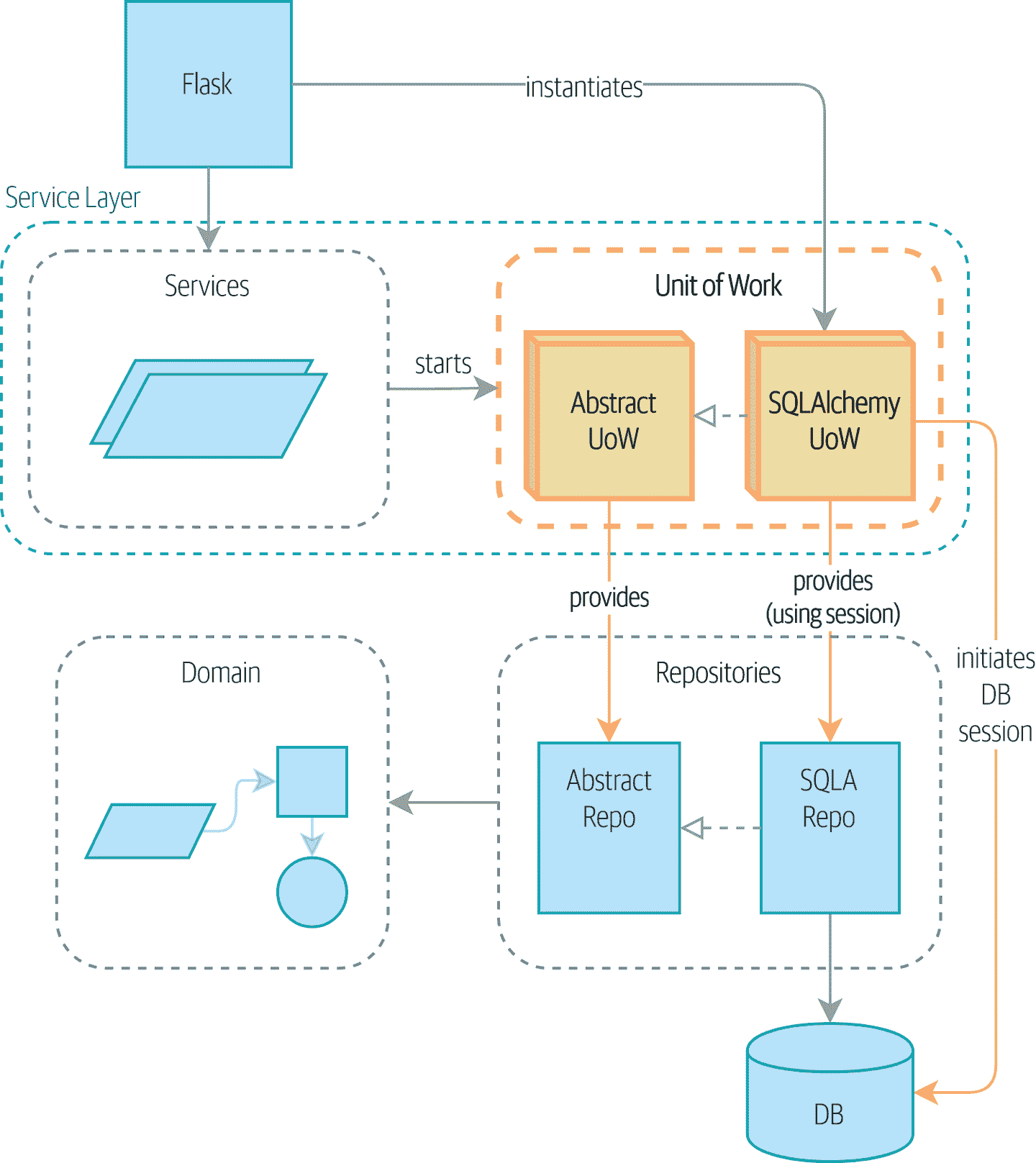
图 6-2:使用 UoW:UoW 现在管理数据库状态
工作单元与存储库合作
让我们看看工作单元(或 UoW,我们发音为“you-wow”)的实际操作。完成后,服务层将如何看起来:
工作单元在操作中的预览(src/allocation/service_layer/services.py)
def allocate(
orderid: str, sku: str, qty: int,
uow: unit_of_work.AbstractUnitOfWork,
) -> str:
line = OrderLine(orderid, sku, qty)
with uow: #(1)
batches = uow.batches.list() #(2)
...
batchref = model.allocate(line, batches)
uow.commit() #(3)
①
我们将启动 UoW 作为上下文管理器。
②
uow.batches是批处理存储库,因此 UoW 为我们提供了对永久存储的访问。
③
完成后,我们使用 UoW 提交或回滚我们的工作。
UoW 充当了我们持久存储的单一入口点,并跟踪了加载的对象和最新状态。¹
这给了我们三个有用的东西:
-
一个稳定的数据库快照,以便我们使用的对象在操作中途不会发生更改
-
一种一次性持久化所有更改的方法,因此如果出现问题,我们不会处于不一致的状态
-
对我们的持久化问题提供了一个简单的 API 和一个方便的获取存储库的地方
通过集成测试驱动 UoW
这是我们的 UOW 集成测试:
UoW 的基本“往返”测试(tests/integration/test_uow.py)
def test_uow_can_retrieve_a_batch_and_allocate_to_it(session_factory):
session = session_factory()
insert_batch(session, "batch1", "HIPSTER-WORKBENCH", 100, None)
session.commit()
uow = unit_of_work.SqlAlchemyUnitOfWork(session_factory) #(1)
with uow:
batch = uow.batches.get(reference="batch1") #(2)
line = model.OrderLine("o1", "HIPSTER-WORKBENCH", 10)
batch.allocate(line)
uow.commit() #(3)
batchref = get_allocated_batch_ref(session, "o1", "HIPSTER-WORKBENCH")
assert batchref == "batch1"
①
我们通过使用自定义会话工厂来初始化 UoW,并获得一个uow对象来在我们的with块中使用。
②
UoW 通过uow.batches为我们提供对批处理存储库的访问。
③
当完成时,我们调用commit()。
对于好奇的人,insert_batch和get_allocated_batch_ref辅助程序如下:
执行 SQL 操作的辅助程序(tests/integration/test_uow.py)
def insert_batch(session, ref, sku, qty, eta):
session.execute(
'INSERT INTO batches (reference, sku, _purchased_quantity, eta)'
' VALUES (:ref, :sku, :qty, :eta)',
dict(ref=ref, sku=sku, qty=qty, eta=eta)
)
def get_allocated_batch_ref(session, orderid, sku):
[[orderlineid]] = session.execute(
'SELECT id FROM order_lines WHERE orderid=:orderid AND sku=:sku',
dict(orderid=orderid, sku=sku)
)
[[batchref]] = session.execute(
'SELECT b.reference FROM allocations JOIN batches AS b ON batch_id = b.id'
' WHERE orderline_id=:orderlineid',
dict(orderlineid=orderlineid)
)
return batchref
工作单元及其上下文管理器
在我们的测试中,我们隐式地定义了 UoW 需要执行的接口。让我们通过使用抽象基类来明确定义:
抽象 UoW 上下文管理器(src/allocation/service_layer/unit_of_work.py)
lass AbstractUnitOfWork(abc.ABC):
batches: repository.AbstractRepository #(1)
def __exit__(self, *args): #(2)
self.rollback() #(4)
@abc.abstractmethod
def commit(self): #(3)
raise NotImplementedError
@abc.abstractmethod
def rollback(self): #(4)
raise NotImplementedError
①
UoW 提供了一个名为.batches的属性,它将为我们提供对批处理存储库的访问。
②
如果您从未见过上下文管理器,__enter__和__exit__是我们进入with块和退出with块时执行的两个魔术方法。它们是我们的设置和拆卸阶段。
③
当我们准备好时,我们将调用这个方法来显式提交我们的工作。
④
如果我们不提交,或者通过引发错误退出上下文管理器,我们将执行rollback。(如果调用了commit(),则rollback不起作用。继续阅读更多关于此的讨论。)
真正的工作单元使用 SQLAlchemy 会话
我们具体实现的主要内容是数据库会话:
真正的 SQLAlchemy UoW(src/allocation/service_layer/unit_of_work.py)
DEFAULT_SESSION_FACTORY = sessionmaker( #(1)
bind=create_engine(
config.get_postgres_uri(),
)
)
class SqlAlchemyUnitOfWork(AbstractUnitOfWork):
def __init__(self, session_factory=DEFAULT_SESSION_FACTORY):
self.session_factory = session_factory #(1)
def __enter__(self):
self.session = self.session_factory() # type: Session #(2)
self.batches = repository.SqlAlchemyRepository(self.session) #(2)
return super().__enter__()
def __exit__(self, *args):
super().__exit__(*args)
self.session.close() #(3)
def commit(self): #(4)
self.session.commit()
def rollback(self): #(4)
self.session.rollback()
①
该模块定义了一个默认的会话工厂,将连接到 Postgres,但我们允许在集成测试中进行覆盖,以便我们可以改用 SQLite。
②
__enter__方法负责启动数据库会话并实例化一个可以使用该会话的真实存储库。
③
我们在退出时关闭会话。
④
最后,我们提供使用我们的数据库会话的具体commit()和rollback()方法。
用于测试的假工作单元
这是我们在服务层测试中如何使用假 UoW 的方式:
假 UoW(tests/unit/test_services.py)
class FakeUnitOfWork(unit_of_work.AbstractUnitOfWork):
def __init__(self):
self.batches = FakeRepository([]) #(1)
self.committed = False #(2)
def commit(self):
self.committed = True #(2)
def rollback(self):
pass
def test_add_batch():
uow = FakeUnitOfWork() #(3)
services.add_batch("b1", "CRUNCHY-ARMCHAIR", 100, None, uow) #(3)
assert uow.batches.get("b1") is not None
assert uow.committed
def test_allocate_returns_allocation():
uow = FakeUnitOfWork() #(3)
services.add_batch("batch1", "COMPLICATED-LAMP", 100, None, uow) #(3)
result = services.allocate("o1", "COMPLICATED-LAMP", 10, uow) #(3)
assert result == "batch1"
①
FakeUnitOfWork和FakeRepository紧密耦合,就像真正的UnitofWork和Repository类一样。这没关系,因为我们认识到这些对象是协作者。
②
注意与FakeSession中的假commit()函数的相似性(现在我们可以摆脱它)。但这是一个重大的改进,因为我们现在是在模拟我们编写的代码,而不是第三方代码。有些人说,“不要模拟你不拥有的东西”。
③
在我们的测试中,我们可以实例化一个 UoW 并将其传递给我们的服务层,而不是传递存储库和会话。这要简单得多。
在服务层使用 UoW
我们的新服务层看起来是这样的:
使用 UoW 的服务层(src/allocation/service_layer/services.py)
def add_batch(
ref: str, sku: str, qty: int, eta: Optional[date],
uow: unit_of_work.AbstractUnitOfWork, #(1)
):
with uow:
uow.batches.add(model.Batch(ref, sku, qty, eta))
uow.commit()
def allocate(
orderid: str, sku: str, qty: int,
uow: unit_of_work.AbstractUnitOfWork, #(1)
) -> str:
line = OrderLine(orderid, sku, qty)
with uow:
batches = uow.batches.list()
if not is_valid_sku(line.sku, batches):
raise InvalidSku(f"Invalid sku {line.sku}")
batchref = model.allocate(line, batches)
uow.commit()
return batchref
①
我们的服务层现在只有一个依赖,再次依赖于抽象 UoW。
显式测试提交/回滚行为
为了确信提交/回滚行为有效,我们编写了一些测试:
回滚行为的集成测试(tests/integration/test_uow.py)
def test_rolls_back_uncommitted_work_by_default(session_factory):
uow = unit_of_work.SqlAlchemyUnitOfWork(session_factory)
with uow:
insert_batch(uow.session, 'batch1', 'MEDIUM-PLINTH', 100, None)
new_session = session_factory()
rows = list(new_session.execute('SELECT * FROM "batches"'))
assert rows == []
def test_rolls_back_on_error(session_factory):
class MyException(Exception):
pass
uow = unit_of_work.SqlAlchemyUnitOfWork(session_factory)
with pytest.raises(MyException):
with uow:
insert_batch(uow.session, 'batch1', 'LARGE-FORK', 100, None)
raise MyException()
new_session = session_factory()
rows = list(new_session.execute('SELECT * FROM "batches"'))
assert rows == []
提示
我们没有在这里展示它,但值得测试一些更“晦涩”的数据库行为,比如事务,针对“真实”的数据库,也就是相同的引擎。目前,我们使用 SQLite 代替 Postgres,但在第七章中,我们将一些测试切换到使用真实数据库。我们的 UoW 类使这变得很方便!
显式提交与隐式提交
现在我们简要地偏离一下实现 UoW 模式的不同方式。
我们可以想象 UoW 的一个稍微不同的版本,默认情况下进行提交,只有在发现异常时才进行回滚:
具有隐式提交的 UoW…(src/allocation/unit_of_work.py)
class AbstractUnitOfWork(abc.ABC):
def __enter__(self):
return self
def __exit__(self, exn_type, exn_value, traceback):
if exn_type is None:
self.commit() #(1)
else:
self.rollback() #(2)
①
在正常情况下,我们应该有一个隐式提交吗?
②
并且只在异常时回滚?
这将允许我们节省一行代码,并从客户端代码中删除显式提交:
…将为我们节省一行代码(src/allocation/service_layer/services.py)
def add_batch(ref: str, sku: str, qty: int, eta: Optional[date], uow):
with uow:
uow.batches.add(model.Batch(ref, sku, qty, eta))
# uow.commit()
这是一个判断调用,但我们倾向于要求显式提交,这样我们就必须选择何时刷新状态。
虽然我们使用了额外的一行代码,但这使得软件默认情况下是安全的。默认行为是不改变任何东西。反过来,这使得我们的代码更容易推理,因为只有一条代码路径会导致系统的更改:完全成功和显式提交。任何其他代码路径,任何异常,任何从 UoW 范围的早期退出都会导致安全状态。
同样,我们更喜欢默认情况下回滚,因为这样更容易理解;这将回滚到上次提交,所以要么用户进行了提交,要么我们取消他们的更改。严厉但简单。
示例:使用 UoW 将多个操作分组为一个原子单元
以下是一些示例,展示了 UoW 模式的使用。您可以看到它如何导致对代码块何时发生在一起的简单推理。
示例 1:重新分配
假设我们想要能够取消分配然后重新分配订单:
重新分配服务功能
def reallocate(
line: OrderLine,
uow: AbstractUnitOfWork,
) -> str:
with uow:
batch = uow.batches.get(sku=line.sku)
if batch is None:
raise InvalidSku(f'Invalid sku {line.sku}')
batch.deallocate(line) #(1)
allocate(line) #(2)
uow.commit()
①
如果deallocate()失败,显然我们不想调用allocate()。
②
如果allocate()失败,我们可能不想实际提交deallocate()。
示例 2:更改批量数量
我们的航运公司给我们打电话说,一个集装箱门打开了,我们的沙发有一半掉进了印度洋。糟糕!
更改数量
def change_batch_quantity(
batchref: str, new_qty: int,
uow: AbstractUnitOfWork,
):
with uow:
batch = uow.batches.get(reference=batchref)
batch.change_purchased_quantity(new_qty)
while batch.available_quantity < 0:
line = batch.deallocate_one() #(1)
uow.commit()
①
在这里,我们可能需要取消分配任意数量的行。如果在任何阶段出现故障,我们可能不想提交任何更改。
整理集成测试
现在我们有三组测试,基本上都指向数据库:test_orm.py、test_repository.py和test_uow.py。我们应该放弃其中的任何一个吗?
└── tests
├── conftest.py
├── e2e
│ └── test_api.py
├── integration
│ ├── test_orm.py
│ ├── test_repository.py
│ └── test_uow.py
├── pytest.ini
└── unit
├── test_allocate.py
├── test_batches.py
└── test_services.py
如果您认为测试长期内不会增加价值,那么您应该随时放弃测试。我们会说 test_orm.py 主要是帮助我们学习 SQLAlchemy 的工具,所以我们长期不需要它,特别是如果它正在做的主要事情已经在 test_repository.py 中涵盖了。最后一个测试,您可能会保留,但我们当然可以看到只保持在最高可能的抽象级别上的论点(就像我们为单元测试所做的那样)。
提示
这是来自第五章的另一个教训的例子:随着我们构建更好的抽象,我们可以将我们的测试运行到它们所针对的抽象,这样我们就可以自由地更改底层细节。* *# 总结
希望我们已经说服了您,单位工作模式是有用的,并且上下文管理器是一种非常好的 Pythonic 方式,可以将代码可视化地分组到我们希望以原子方式发生的块中。
这种模式非常有用,事实上,SQLAlchemy 已经使用了 UoW,形式为Session对象。SQLAlchemy 中的Session对象是您的应用程序从数据库加载数据的方式。
每次从数据库加载新实体时,会话开始跟踪对实体的更改,当会话刷新时,所有更改都会一起持久化。如果 SQLAlchemy 已经实现了我们想要的模式,为什么我们要努力抽象出 SQLAlchemy 会话呢?
Table 6-1 讨论了一些权衡。
表 6-1. 单元工作模式:权衡
| 优点 | 缺点 |
|---|---|
| 我们对原子操作的概念有一个很好的抽象,上下文管理器使得很容易直观地看到哪些代码块被原子地分组在一起。 | 您的 ORM 可能已经围绕原子性有一些完全合适的抽象。SQLAlchemy 甚至有上下文管理器。只需传递一个会话就可以走得很远。 |
| 我们可以明确控制事务何时开始和结束,我们的应用程序默认以一种安全的方式失败。我们永远不必担心某个操作部分提交。 | 我们让它看起来很容易,但您必须仔细考虑回滚、多线程和嵌套事务等问题。也许只需坚持 Django 或 Flask-SQLAlchemy 给您的东西,就可以让您的生活更简单。 |
| 这是一个很好的地方,可以将所有的存储库放在一起,这样客户端代码就可以访问它们。 | |
| 正如您将在后面的章节中看到的那样,原子性不仅仅是关于事务;它可以帮助我们处理事件和消息总线。 |
首先,会话 API 非常丰富,支持我们在领域中不需要或不需要的操作。我们的UnitOfWork简化了会话到其基本核心:它可以启动、提交或丢弃。
另外,我们使用UnitOfWork来访问我们的Repository对象。这是一个很好的开发人员可用性的技巧,我们无法使用普通的 SQLAlchemySession来实现。
最后,我们再次受到依赖反转原则的激励:我们的服务层依赖于一个薄抽象,并且我们在系统的外围附加一个具体的实现。这与 SQLAlchemy 自己的建议非常契合:
保持会话的生命周期(通常也是事务)分离和外部化。最全面的方法,建议用于更实质性的应用程序,将尽可能将会话、事务和异常管理的细节与执行其工作的程序的细节分开。
——SQLALchemy“会话基础”文档
¹ 您可能已经遇到过使用“合作者”一词来描述一起实现目标的对象。工作单元和存储库是对象建模意义上的合作者的绝佳示例。在责任驱动设计中,以其角色协作的对象群集被称为“对象邻域”,在我们的专业意见中,这是非常可爱的。
第七章:聚合和一致性边界
原文:7: Aggregates and Consistency Boundaries
译者:飞龙
在本章中,我们想重新审视我们的领域模型,讨论不变量和约束,并看看我们的领域对象如何在概念上和持久存储中保持自己的内部一致性。我们将讨论一致性边界的概念,并展示如何明确地做出这一点可以帮助我们构建高性能软件,而不会影响可维护性。
图 7-1 显示了我们的目标:我们将引入一个名为Product的新模型对象来包装多个批次,并且我们将使旧的allocate()领域服务作为Product的方法可用。
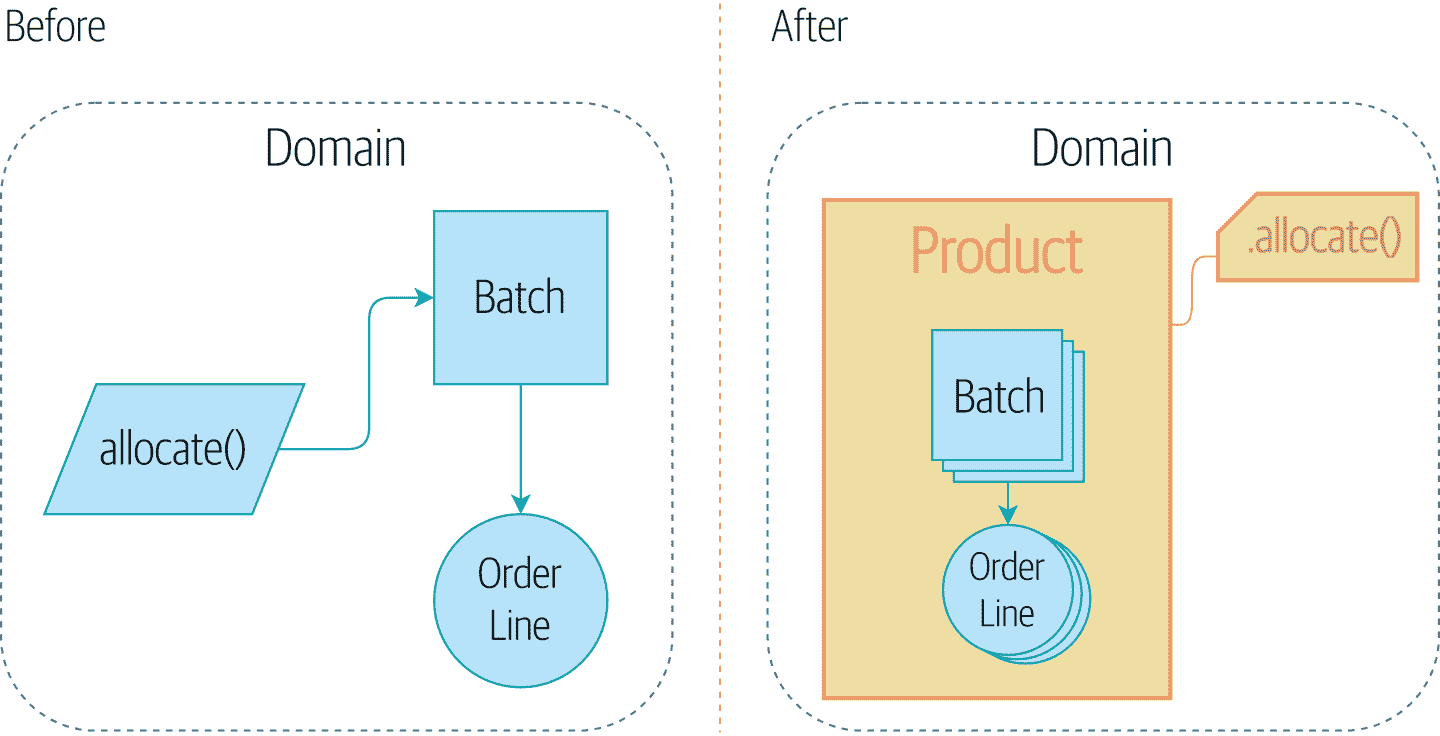
图 7-1. 添加产品聚合
为什么?让我们找出原因。
提示
本章的代码在GitHub的 appendix_csvs 分支中:
git clone https://github.com/cosmicpython/code.git
cd code
git checkout appendix_csvs
# or to code along, checkout the previous chapter:
git checkout chapter_06_uow
为什么不只在电子表格中运行所有东西?
领域模型的意义是什么?我们试图解决的根本问题是什么?
我们难道不能只在电子表格中运行所有东西吗?我们的许多用户会对此感到高兴。业务用户喜欢电子表格,因为它们简单、熟悉,但又非常强大。
事实上,大量的业务流程确实是通过手动在电子邮件中来回发送电子表格来操作的。这种“CSV 通过 SMTP”架构具有较低的初始复杂性,但往往不容易扩展,因为很难应用逻辑和保持一致性。
谁有权查看特定字段?谁有权更新它?当我们尝试订购-350 把椅子或者 1000 万张桌子时会发生什么?员工可以有负薪水吗?
这些是系统的约束条件。我们编写的许多领域逻辑存在的目的是为了强制执行这些约束条件,以维护系统的不变量。不变量是每当我们完成一个操作时必须为真的事物。
不变量、约束和一致性
这两个词在某种程度上是可以互换的,但约束是限制我们的模型可能进入的可能状态的规则,而不变量更精确地定义为始终为真的条件。
如果我们正在编写酒店预订系统,我们可能会有一个约束,即不允许双重预订。这支持了一个不变量,即一个房间在同一天晚上不能有多个预订。
当然,有时我们可能需要暂时违反规则。也许我们需要因为贵宾预订而重新安排房间。当我们在内存中移动预订时,我们可能会被双重预订,但我们的领域模型应该确保,当我们完成时,我们最终处于一个一致的状态,其中不变量得到满足。如果我们找不到一种方法来容纳所有客人,我们应该引发错误并拒绝完成操作。
让我们从我们的业务需求中看一些具体的例子;我们将从这个开始:
订单行一次只能分配给一个批次。
——业务
这是一个强加不变量的业务规则。不变量是订单行必须分配给零个或一个批次,但绝不能超过一个。我们需要确保我们的代码永远不会意外地对同一行调用Batch.allocate()两个不同的批次,并且目前没有任何东西明确阻止我们这样做。
不变量、并发和锁
让我们再看看我们的另一个业务规则:
如果可用数量小于订单行的数量,我们就不能分配给批次。
——业务
这里的约束是我们不能分配超过批次可用数量的库存,因此我们永远不会通过将两个客户分配给同一个实际垫子而超卖库存。每当我们更新系统的状态时,我们的代码需要确保我们不会破坏不变量,即可用数量必须大于或等于零。
在单线程、单用户的应用程序中,我们相对容易地维护这个不变量。我们可以一次分配一行库存,并在没有库存可用时引发错误。
当我们引入并发的概念时,这就变得更加困难。突然间,我们可能同时为多个订单行分配库存。甚至可能在处理对批次本身的更改的同时分配订单行。
通常,我们通过在数据库表上应用锁来解决这个问题。这可以防止在同一行或同一表上同时发生两个操作。
当我们开始考虑扩展我们的应用程序时,我们意识到我们针对所有可用批次分配行的模型可能无法扩展。如果我们每小时处理数万个订单,以及数十万个订单行,我们无法为每一个订单行在整个batches表上持有锁定——至少会出现死锁或性能问题。
什么是聚合?
好吧,如果我们每次想要分配一个订单行都不能锁定整个数据库,那我们应该做什么呢?我们希望保护系统的不变量,但又允许最大程度的并发。维护我们的不变量不可避免地意味着防止并发写入;如果多个用户可以同时分配DEADLY-SPOON,我们就有可能过度分配。
另一方面,我们可以同时分配DEADLY-SPOON和FLIMSY-DESK。同时分配两种产品是安全的,因为它们没有共同的不变量。我们不需要它们彼此一致。
聚合模式是来自 DDD 社区的设计模式,它帮助我们解决这种紧张关系。聚合只是一个包含其他领域对象的领域对象,它让我们将整个集合视为一个单一单位。
修改聚合内部对象的唯一方法是加载整个对象,并在聚合本身上调用方法。
随着模型变得更加复杂,实体和值对象之间相互引用,形成了一个纠缠的图形,很难跟踪谁可以修改什么。特别是当我们在模型中有集合(我们的批次是一个集合)时,提名一些实体作为修改其相关对象的唯一入口是一个好主意。如果您提名一些对象负责其他对象的一致性,系统在概念上会更简单,更容易理解。
例如,如果我们正在构建一个购物网站,购物车可能是一个很好的聚合:它是一组商品,我们可以将其视为一个单一单位。重要的是,我们希望从数据存储中以单个块加载整个购物篮。我们不希望两个请求同时修改购物篮,否则我们就有可能出现奇怪的并发错误。相反,我们希望每次对购物篮的更改都在单个数据库事务中运行。
我们不希望在一个事务中修改多个购物篮,因为没有用例需要同时更改几个客户的购物篮。每个购物篮都是一个单一的一致性边界,负责维护自己的不变量。
聚合是一组相关对象的集合,我们将其视为数据更改的单元。
——埃里克·埃文斯,《领域驱动设计》蓝皮书
根据埃里克·埃文斯(Eric Evans)的说法,我们的聚合有一个根实体(购物车),它封装了对商品的访问。每个商品都有自己的身份,但系统的其他部分将始终将购物车视为一个不可分割的整体。
提示
就像我们有时使用*_leading_underscores*来标记方法或函数为“私有”一样,您可以将聚合视为我们模型的“公共”类,而其他实体和值对象则为“私有”。
选择聚合
我们的系统应该使用哪个聚合?选择有点随意,但很重要。聚合将是我们确保每个操作都以一致状态结束的边界。这有助于我们推理我们的软件并防止奇怪的竞争问题。我们希望在一小部分对象周围划定边界——越小越好,以提高性能——这些对象必须彼此保持一致,并且我们需要给这个边界一个好名字。
我们在幕后操作的对象是Batch。我们如何称呼一组批次?我们应该如何将系统中的所有批次划分为一致性的离散岛屿?
我们可以使用Shipment作为我们的边界。每个发货包含多个批次,它们同时运送到我们的仓库。或者我们可以使用Warehouse作为我们的边界:每个仓库包含许多批次,同时对所有库存进行计数可能是有意义的。
然而,这两个概念都不能满足我们。即使它们在同一个仓库或同一批次中,我们也应该能够同时分配DEADLY-SPOONs和FLIMSY-DESKs。这些概念的粒度不对。
当我们分配订单行时,我们只对具有与订单行相同 SKU 的批次感兴趣。类似GlobalSkuStock的概念可能有效:给定 SKU 的所有批次的集合。
然而,这是一个笨重的名称,所以在通过SkuStock、Stock、ProductStock等进行一些讨论后,我们决定简单地称其为Product——毕竟,这是我们在第一章中探索领域语言时遇到的第一个概念。
因此,计划是这样的:当我们想要分配订单行时,我们不再使用图 7-2,在那里我们查找世界上所有的Batch对象并将它们传递给allocate()领域服务…

图 7-2.之前:使用领域服务对所有批次进行分配
[plantuml, apwp_0702, config=plantuml.cfg]
@startuml
hide empty members
package "Service Layer" as services {
class "allocate()" as allocate {
}
hide allocate circle
hide allocate members
}
package "Domain Model" as domain_model {
class Batch {
}
class "allocate()" as allocate_domain_service {
}
hide allocate_domain_service circle
hide allocate_domain_service members
}
package repositories {
class BatchRepository {
list()
}
}
allocate -> BatchRepository: list all batches
allocate --> allocate_domain_service: allocate(orderline, batches)
@enduml
…我们将转向图 7-3 的世界,在那里有一个特定 SKU 的新Product对象,它将负责所有该 SKU的批次,并且我们可以在其上调用.allocate()方法。
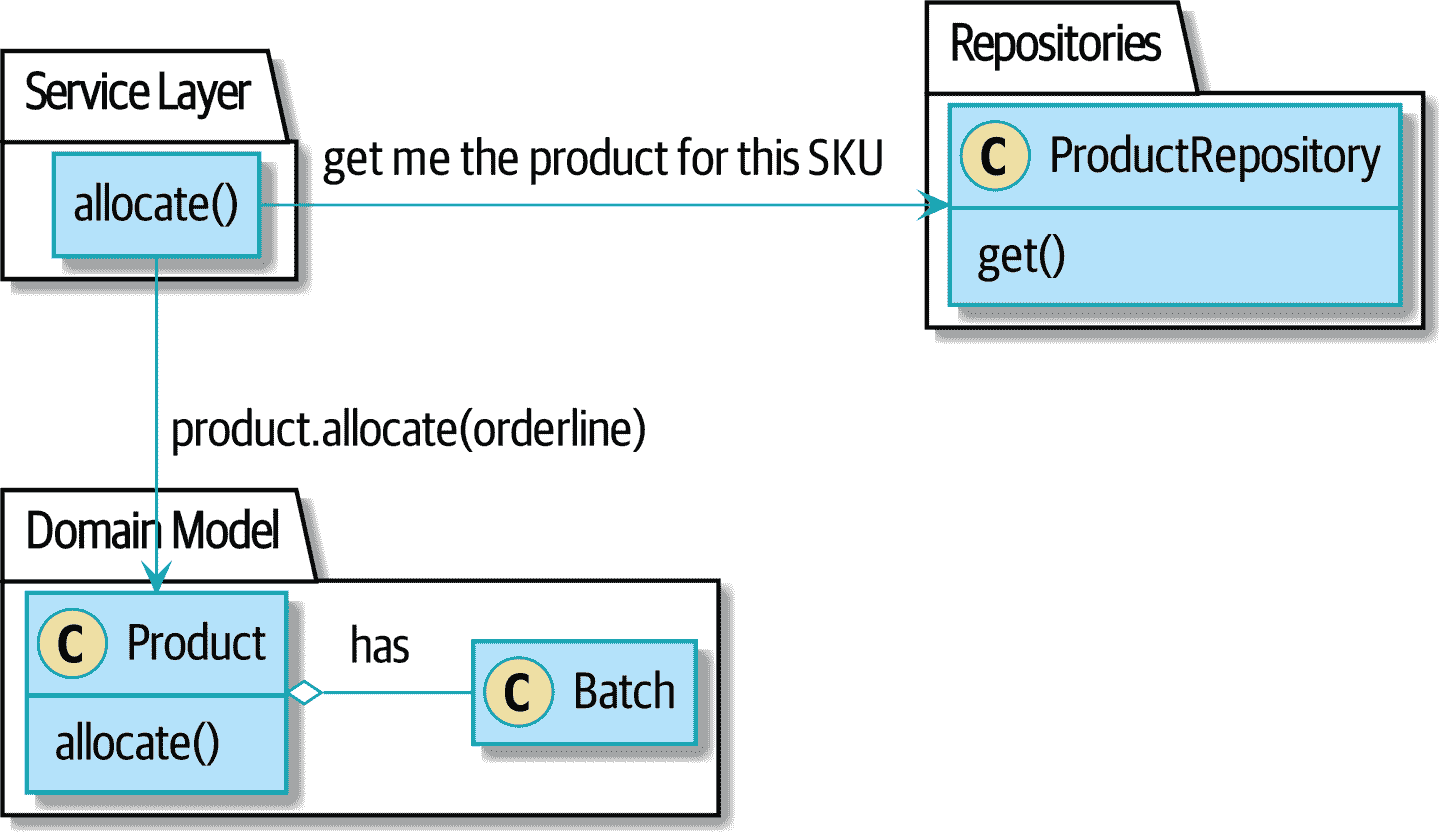
图 7-3.之后:要求 Product 根据其批次进行分配
[plantuml, apwp_0703, config=plantuml.cfg]
@startuml
hide empty members
package "Service Layer" as services {
class "allocate()" as allocate {
}
}
hide allocate circle
hide allocate members
package "Domain Model" as domain_model {
class Product {
allocate()
}
class Batch {
}
}
package repositories {
class ProductRepository {
get()
}
}
allocate -> ProductRepository: get me the product for this sku
allocate --> Product: product.allocate(orderline)
Product o- Batch: has
@enduml
让我们看看代码形式是什么样子的:
我们选择的聚合,Product (src/allocation/domain/model.py)
class Product:
def __init__(self, sku: str, batches: List[Batch]):
self.sku = sku #(1)
self.batches = batches #(2)
def allocate(self, line: OrderLine) -> str: #(3)
try:
batch = next(b for b in sorted(self.batches) if b.can_allocate(line))
batch.allocate(line)
return batch.reference
except StopIteration:
raise OutOfStock(f"Out of stock for sku {line.sku}")
①
Product的主要标识符是sku。
②
我们的Product类持有对该 SKU 的一组batches的引用。
③
最后,我们可以将allocate()领域服务移动到Product聚合的方法上。
注
这个Product看起来可能不像你期望的Product模型。没有价格,没有描述,没有尺寸。我们的分配服务不关心这些东西。这就是有界上下文的力量;一个应用中的产品概念可能与另一个应用中的产品概念非常不同。请参阅以下侧边栏以进行更多讨论。
一个聚合=一个存储库
一旦您定义了某些实体为聚合,我们需要应用一个规则,即它们是唯一对外界可访问的实体。换句话说,我们允许的唯一存储库应该是返回聚合的存储库。
注
存储库只返回聚合是我们强制执行聚合是进入我们领域模型的唯一方式的主要地方。要小心不要违反它!
在我们的案例中,我们将从BatchRepository切换到ProductRepository:
我们的新 UoW 和存储库(unit_of_work.py 和 repository.py)
class AbstractUnitOfWork(abc.ABC):
products: repository.AbstractProductRepository
...
class AbstractProductRepository(abc.ABC):
@abc.abstractmethod
def add(self, product):
...
@abc.abstractmethod
def get(self, sku) -> model.Product:
...
ORM 层将需要一些调整,以便正确的批次自动加载并与“Product”对象关联。好处是,存储库模式意味着我们不必担心这个问题。我们可以只使用我们的“FakeRepository”,然后将新模型传递到我们的服务层,看看它作为其主要入口点的“Product”是什么样子:
服务层(src/allocation/service_layer/services.py)
def add_batch(
ref: str, sku: str, qty: int, eta: Optional[date],
uow: unit_of_work.AbstractUnitOfWork
):
with uow:
product = uow.products.get(sku=sku)
if product is None:
product = model.Product(sku, batches=[])
uow.products.add(product)
product.batches.append(model.Batch(ref, sku, qty, eta))
uow.commit()
def allocate(
orderid: str, sku: str, qty: int,
uow: unit_of_work.AbstractUnitOfWork
) -> str:
line = OrderLine(orderid, sku, qty)
with uow:
product = uow.products.get(sku=line.sku)
if product is None:
raise InvalidSku(f'Invalid sku {line.sku}')
batchref = product.allocate(line)
uow.commit()
return batchref
性能如何?
我们已经多次提到,我们正在使用聚合进行建模,因为我们希望拥有高性能的软件,但是在这里,我们加载了所有批次,而我们只需要一个。你可能会认为这是低效的,但我们在这里感到舒适的原因有几个。
首先,我们有意地对我们的数据进行建模,以便我们可以对数据库进行单个查询来读取,并进行单个更新以保存我们的更改。这往往比发出许多临时查询的系统性能要好得多。在不以这种方式建模的系统中,我们经常发现随着软件的发展,事务变得越来越长,越来越复杂。
其次,我们的数据结构是最小的,每行包括一些字符串和整数。我们可以在几毫秒内轻松加载数十甚至数百个批次。
第三,我们预计每种产品一次只有大约 20 个批次左右。一旦批次用完,我们可以从我们的计算中剔除它。这意味着我们获取的数据量不应该随着时间的推移而失控。
如果我们确实预计某种产品会有成千上万个活跃的批次,我们将有几个选择。首先,我们可以对产品中的批次使用延迟加载。从我们代码的角度来看,没有任何变化,但在后台,SQLAlchemy 会为我们分页数据。这将导致更多的请求,每个请求获取更少的行。因为我们只需要找到一个足够容量的批次来满足我们的订单,这可能效果很好。
如果一切都失败了,我们只需寻找一个不同的聚合。也许我们可以按地区或仓库拆分批次。也许我们可以围绕装运概念重新设计我们的数据访问策略。聚合模式旨在帮助管理一些围绕一致性和性能的技术约束。并没有一个正确的聚合,如果发现我们的边界导致性能问题,我们应该放心改变我们的想法。
使用版本号进行乐观并发
我们有了我们的新聚合,所以我们解决了选择一个对象负责一致性边界的概念问题。现在让我们花点时间谈谈如何在数据库级别强制执行数据完整性。
注意
这一部分包含了许多实现细节;例如,其中一些是特定于 Postgres 的。但更一般地,我们展示了一种管理并发问题的方法,但这只是一种方法。这一领域的实际要求在项目之间变化很大。你不应该期望能够将代码从这里复制粘贴到生产环境中。
我们不想在整个“batches”表上持有锁,但是我们如何实现仅在特定 SKU 的行上持有锁?
一个解决方案是在“Product”模型上有一个单一属性,作为整个状态变化完成的标记,并将其用作并发工作者可以争夺的单一资源。如果两个事务同时读取“batches”的世界状态,并且都想要更新“allocations”表,我们强制两者也尝试更新“products”表中的“version_number”,以便只有一个可以获胜,世界保持一致。
图 7-4 说明了两个并发事务同时进行读取操作,因此它们看到的是一个具有,例如,version=3的Product。它们都调用Product.allocate()来修改状态。但我们设置了数据库完整性规则,只允许其中一个使用commit提交带有version=4的新Product,而另一个更新将被拒绝。
提示
版本号只是实现乐观锁定的一种方式。你可以通过将 Postgres 事务隔离级别设置为SERIALIZABLE来实现相同的效果,但这通常会带来严重的性能成本。版本号还可以使隐含的概念变得明确。
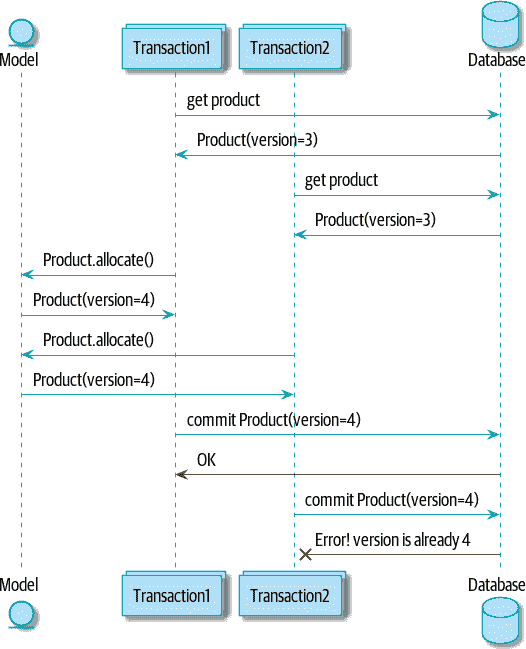
图 7-4:序列图:两个事务尝试并发更新“Product”
[plantuml, apwp_0704, config=plantuml.cfg]
@startuml
entity Model
collections Transaction1
collections Transaction2
database Database
Transaction1 -> Database: get product
Database -> Transaction1: Product(version=3)
Transaction2 -> Database: get product
Database -> Transaction2: Product(version=3)
Transaction1 -> Model: Product.allocate()
Model -> Transaction1: Product(version=4)
Transaction2 -> Model: Product.allocate()
Model -> Transaction2: Product(version=4)
Transaction1 -> Database: commit Product(version=4)
Database -[#green]> Transaction1: OK
Transaction2 -> Database: commit Product(version=4)
Database -[#red]>x Transaction2: Error! version is already 4
@enduml
版本号的实现选项
基本上有三种实现版本号的选项:
-
version_number存在于领域中;我们将其添加到Product构造函数中,Product.allocate()负责递增它。 -
服务层可以做到!版本号并不严格是一个领域问题,所以我们的服务层可以假设当前版本号是由存储库附加到
Product上的,并且服务层在执行commit()之前会递增它。 -
由于这可以说是一个基础设施问题,UoW 和存储库可以通过魔法来做到这一点。存储库可以访问它检索的任何产品的版本号,当 UoW 提交时,它可以递增它所知道的任何产品的版本号,假设它们已经更改。
选项 3 并不理想,因为没有真正的方法可以做到这一点,而不必假设所有产品都已更改,所以我们将在不必要的时候递增版本号。¹
选项 2 涉及在服务层和领域层之间混合变更状态的责任,因此也有点混乱。
因此,最终,即使版本号不一定是一个领域关注的问题,你可能会决定最干净的权衡是将它们放在领域中:
我们选择的聚合,Product(src/allocation/domain/model.py)
class Product:
def __init__(self, sku: str, batches: List[Batch], version_number: int = 0): #(1)
self.sku = sku
self.batches = batches
self.version_number = version_number #(1)
def allocate(self, line: OrderLine) -> str:
try:
batch = next(b for b in sorted(self.batches) if b.can_allocate(line))
batch.allocate(line)
self.version_number += 1 #(1)
return batch.reference
except StopIteration:
raise OutOfStock(f"Out of stock for sku {line.sku}")
①
就是这样!
提示
如果你对版本号这个业务感到困惑,也许记住号码并不重要会有所帮助。重要的是,每当我们对“Product”聚合进行更改时,“Product”数据库行都会被修改。版本号是一种简单的、人类可理解的方式来模拟每次写入时都会发生变化的事物,但它也可以是每次都是一个随机 UUID。
测试我们的数据完整性规则
现在要确保我们可以得到我们想要的行为:如果我们有两个并发尝试针对同一个Product进行分配,其中一个应该失败,因为它们不能同时更新版本号。
首先,让我们使用一个执行分配然后显式休眠的函数来模拟“慢”事务:²
time.sleep 可以复制并发行为(tests/integration/test_uow.py)
def try_to_allocate(orderid, sku, exceptions):
line = model.OrderLine(orderid, sku, 10)
try:
with unit_of_work.SqlAlchemyUnitOfWork() as uow:
product = uow.products.get(sku=sku)
product.allocate(line)
time.sleep(0.2)
uow.commit()
except Exception as e:
print(traceback.format_exc())
exceptions.append(e)
然后我们的测试使用线程并发两次调用这个慢分配:
并发行为的集成测试(tests/integration/test_uow.py)
def test_concurrent_updates_to_version_are_not_allowed(postgres_session_factory):
sku, batch = random_sku(), random_batchref()
session = postgres_session_factory()
insert_batch(session, batch, sku, 100, eta=None, product_version=1)
session.commit()
order1, order2 = random_orderid(1), random_orderid(2)
exceptions = [] # type: List[Exception]
try_to_allocate_order1 = lambda: try_to_allocate(order1, sku, exceptions)
try_to_allocate_order2 = lambda: try_to_allocate(order2, sku, exceptions)
thread1 = threading.Thread(target=try_to_allocate_order1) #(1)
thread2 = threading.Thread(target=try_to_allocate_order2) #(1)
thread1.start()
thread2.start()
thread1.join()
thread2.join()
[[version]] = session.execute(
"SELECT version_number FROM products WHERE sku=:sku",
dict(sku=sku),
)
assert version == 2 #(2)
[exception] = exceptions
assert "could not serialize access due to concurrent update" in str(exception) #(3)
orders = session.execute(
"SELECT orderid FROM allocations"
" JOIN batches ON allocations.batch_id = batches.id"
" JOIN order_lines ON allocations.orderline_id = order_lines.id"
" WHERE order_lines.sku=:sku",
dict(sku=sku),
)
assert orders.rowcount == 1 #(4)
with unit_of_work.SqlAlchemyUnitOfWork() as uow:
uow.session.execute("select 1")
①
我们启动两个线程,它们将可靠地产生我们想要的并发行为:read1, read2, write1, write2。
②
我们断言版本号只被递增了一次。
③
我们也可以检查特定的异常,如果我们愿意的话。
④
然后我们再次检查,只有一个分配已经完成。
通过使用数据库事务隔离级别来强制执行并发规则
为了使测试通过,我们可以在会话中设置事务隔离级别:
为会话设置隔离级别 (src/allocation/service_layer/unit_of_work.py)
DEFAULT_SESSION_FACTORY = sessionmaker(bind=create_engine(
config.get_postgres_uri(),
isolation_level="REPEATABLE READ",
))
提示
事务隔离级别是棘手的东西,所以值得花时间了解Postgres 文档。³
悲观并发控制示例:SELECT FOR UPDATE
有多种方法可以解决这个问题,但我们将展示一种方法。SELECT FOR UPDATE会产生不同的行为;两个并发事务将不被允许同时对相同的行进行读取。
SELECT FOR UPDATE是一种选择行作为锁定的方法(尽管这些行不一定是你要更新的行)。如果两个事务同时尝试SELECT FOR UPDATE一行,一个会获胜,另一个会等待直到锁定被释放。因此,这是一种悲观并发控制的例子。
以下是您可以使用 SQLAlchemy DSL 在查询时指定FOR UPDATE的方法:
SQLAlchemy with_for_update (src/allocation/adapters/repository.py)
def get(self, sku):
return self.session.query(model.Product)
.filter_by(sku=sku)
.with_for_update()
.first()
这将改变并发模式
read1, read2, write1, write2(fail)
到
read1, write1, read2, write2(succeed)
有些人将这称为“读取-修改-写入”故障模式。阅读“PostgreSQL 反模式:读取-修改-写入周期”以获得一个很好的概述。
我们真的没有时间讨论“REPEATABLE READ”和“SELECT FOR UPDATE”之间的所有权衡,或者乐观与悲观锁定。但是,如果你有一个像我们展示的那样的测试,你可以指定你想要的行为并查看它是如何改变的。你也可以使用测试作为执行一些性能实验的基础。
总结
围绕并发控制的具体选择根据业务情况和存储技术选择而有很大的不同,但我们想把这一章重新带回到聚合的概念上:我们明确地将一个对象建模为我们模型的某个子集的主要入口点,并负责强制执行适用于所有这些对象的不变量和业务规则。
选择正确的聚合是关键,这是一个你可能随时间重新考虑的决定。你可以在多本 DDD 书籍中了解更多。我们还推荐 Vaughn Vernon(“红皮书”作者)的这三篇关于有效聚合设计的在线论文。
表 7-1 对实现聚合模式的权衡有一些想法。
表 7-1. 聚合:权衡
| 优点 | 缺点 |
|---|---|
| Python 可能没有“官方”的公共和私有方法,但我们有下划线约定,因为通常有用的是尝试指示什么是“内部”使用和什么是“外部代码”使用。选择聚合只是更高一级的:它让你决定你的领域模型类中哪些是公共的,哪些不是。 | 对于新开发人员来说,又是一个新概念。解释实体与值对象已经是一种心理负担;现在又出现了第三种领域模型对象? |
| 围绕显式一致性边界建模我们的操作有助于避免 ORM 的性能问题。 | 严格遵守我们一次只修改一个聚合的规则是一个很大的心理转变。 |
| 将聚合单独负责对其子模型的状态更改使系统更容易理解,并使其更容易控制不变量。 | 处理聚合之间的最终一致性可能会很复杂。 |
第一部分总结
你还记得图 7-5 吗?这是我们在第一部分开始时展示的图表,预览我们的方向的。
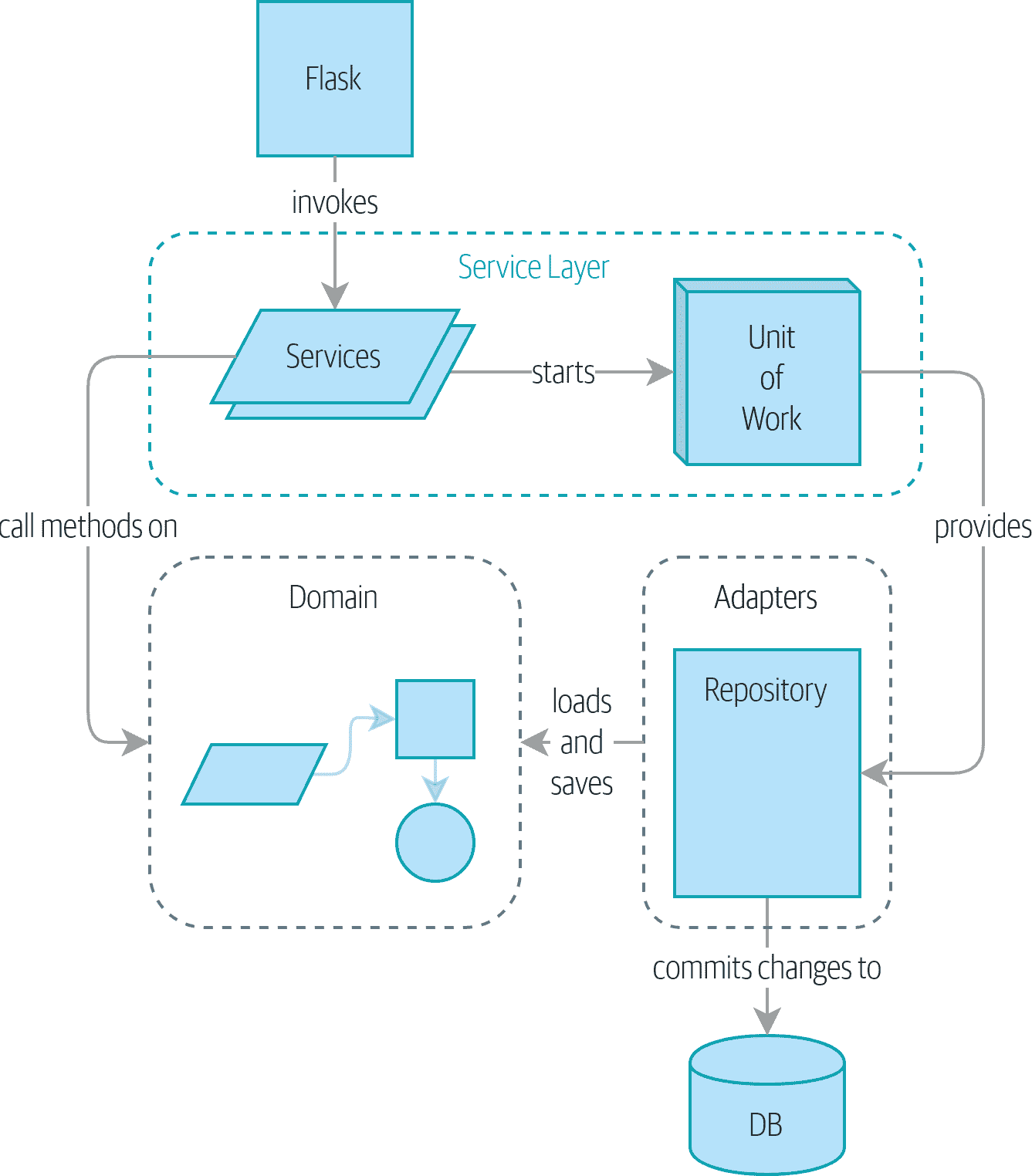
图 7-5:第一部分结束时我们应用的组件图
这就是我们在第一部分结束时所处的位置。我们取得了什么成就?我们看到了如何构建一个领域模型,通过一组高级单元测试来验证。我们的测试是活的文档:它们描述了我们系统的行为——我们与业务利益相关者达成一致的规则——以易于阅读的代码形式。当我们的业务需求发生变化时,我们有信心我们的测试将帮助我们证明新功能,当新的开发人员加入项目时,他们可以阅读我们的测试来理解事物是如何工作的。
我们已经解耦了系统的基础部分,如数据库和 API 处理程序,以便我们可以将它们插入到我们应用程序的外部。这有助于我们保持我们的代码库组织良好,并阻止我们构建一个大泥球。
通过应用依赖反转原则,并使用端口和适配器启发的模式,如存储库和工作单元,我们已经使得在高档和低档都可以进行 TDD,并保持一个健康的测试金字塔。我们可以对我们的系统进行端到端的测试,对集成和端到端测试的需求保持最低限度。
最后,我们谈到了一致性边界的概念。我们不希望在进行更改时锁定整个系统,因此我们必须选择哪些部分彼此一致。
对于一个小系统来说,这就是你需要去尝试领域驱动设计理念的一切。现在你有了工具来构建与数据库无关的领域模型,代表了你的业务专家的共享语言。万岁!
注意
冒着重复的风险,我们一再强调每个模式都有成本。每一层间接性都会在我们的代码中产生复杂性和重复,并且对于从未见过这些模式的程序员来说会很困惑。如果你的应用本质上只是一个简单的 CRUD 包装器,围绕数据库,未来也不太可能成为其他东西,你不需要这些模式。继续使用 Django,省去很多麻烦。
在第二部分中,我们将放大并讨论一个更大的话题:如果聚合是我们的边界,我们只能一次更新一个,那么我们如何建模跨一致性边界的过程呢?
¹也许我们可以通过 ORM/SQLAlchemy 魔术告诉我们对象何时是脏的,但在通用情况下,这将如何工作——例如对于CsvRepository?
²time.sleep()在我们的用例中效果很好,但它并不是再现并发错误最可靠或高效的方式。考虑使用信号量或类似的同步原语,在线程之间共享,以获得更好的行为保证。
³如果你没有使用 Postgres,你需要阅读不同的文档。令人恼火的是,不同的数据库都有相当不同的定义。例如,Oracle 的SERIALIZABLE等同于 Postgres 的REPEATABLE READ。
第二部分:事件驱动架构
原文:Part 2: Event-Driven Architecture
译者:飞龙
很抱歉我很久以前为这个主题创造了“对象”这个术语,因为它让很多人关注了次要的想法。
重要的想法是“消息传递”……设计出伟大且可扩展的系统的关键更多地在于设计其模块之间的通信方式,而不是它们的内部属性和行为应该是什么。
——艾伦·凯
能够编写一个领域模型来管理一个业务流程的一小部分是非常好的,但当我们需要编写许多模型时会发生什么?在现实世界中,我们的应用程序位于一个组织中,并且需要与系统的其他部分交换信息。您可能还记得我们在图 II-1 中显示的上下文图。
面对这个要求,许多团队会选择通过 HTTP API 集成的微服务。但如果他们不小心,最终会产生最混乱的分布式大泥球。
在第二部分中,我们将展示如何将第一部分的技术扩展到分布式系统。我们将放大看看如何通过异步消息传递来组合一个系统的许多小组件之间的交互。
我们将看到我们的服务层和工作单元模式如何允许我们重新配置我们的应用程序以作为异步消息处理器运行,以及事件驱动系统如何帮助我们将聚合和应用程序相互解耦。
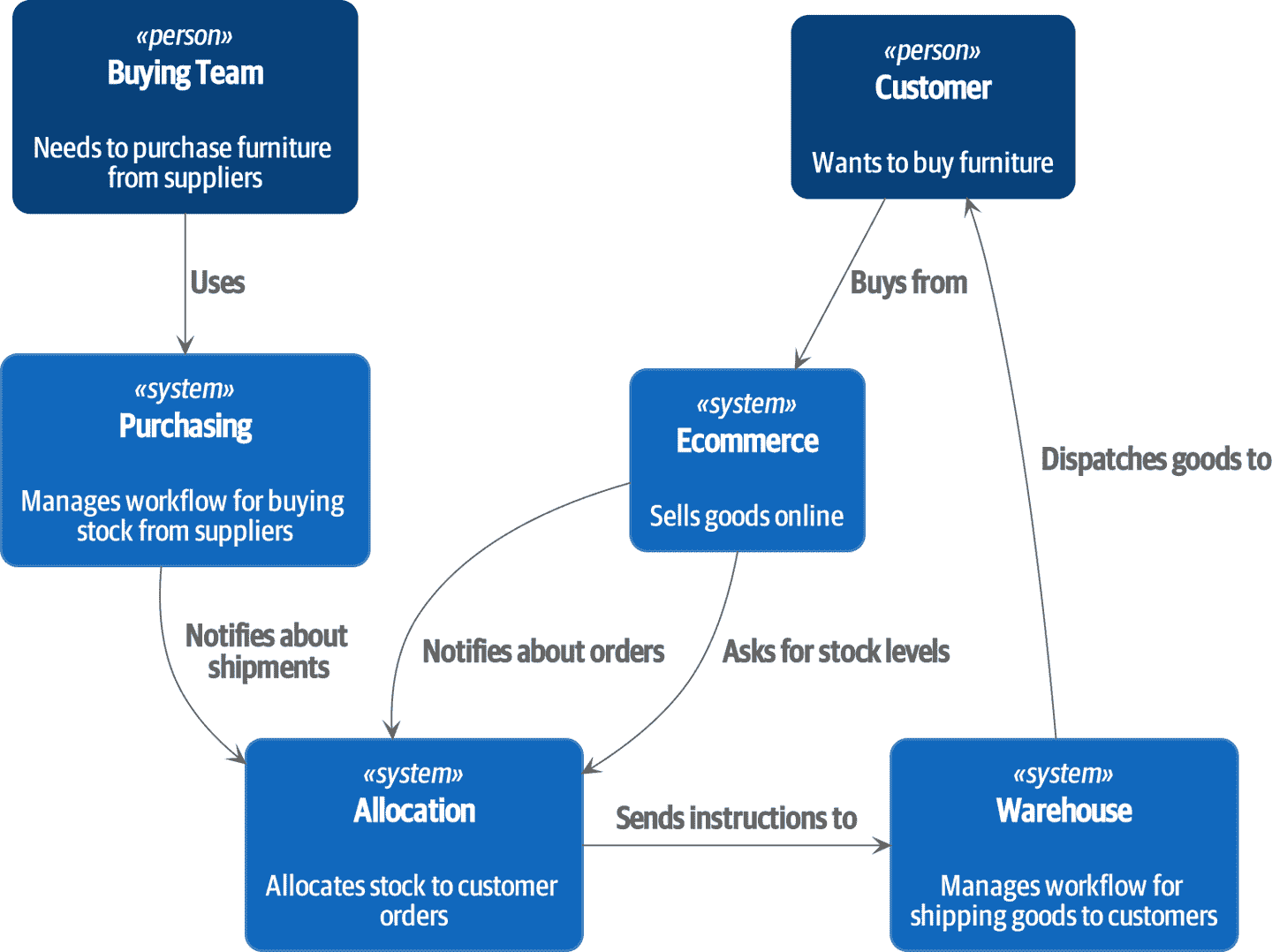
图 II-1:但所有这些系统究竟如何相互通信呢?
我们将研究以下模式和技术:
领域事件
触发跨一致性边界的工作流。
消息总线
提供了一个统一的方式从任何端点调用用例。
CQRS
分离读和写避免了事件驱动架构中的尴尬妥协,并实现了性能和可扩展性的改进。
此外,我们将添加一个依赖注入框架。这与事件驱动架构本身无关,但它整理了许多松散的尾巴。
第八章:事件和消息总线
原文:8: Events and the Message Bus
译者:飞龙
到目前为止,我们已经花了很多时间和精力解决一个我们本可以很容易用 Django 解决的简单问题。你可能会问,增加的可测试性和表现力是否真的值得所有的努力。
然而,在实践中,我们发现搞乱我们代码库的并不是明显的功能,而是边缘的混乱。它是报告、权限和涉及无数对象的工作流。
我们的例子将是一个典型的通知要求:当我们因为库存不足而无法分配订单时,我们应该通知采购团队。他们会去解决问题,购买更多的库存,一切都会好起来。
对于第一个版本,我们的产品所有者说我们可以通过电子邮件发送警报。
让我们看看当我们需要插入一些构成我们系统很大一部分的平凡事物时,我们的架构是如何保持的。
我们将首先做最简单、最迅速的事情,并讨论为什么正是这种决定导致了我们的大泥球。
然后我们将展示如何使用领域事件模式将副作用与我们的用例分离,并如何使用简单的消息总线模式来触发基于这些事件的行为。我们将展示一些创建这些事件的选项以及如何将它们传递给消息总线,最后我们将展示如何修改工作单元模式以优雅地将这两者连接在一起,正如图 8-1 中预览的那样。
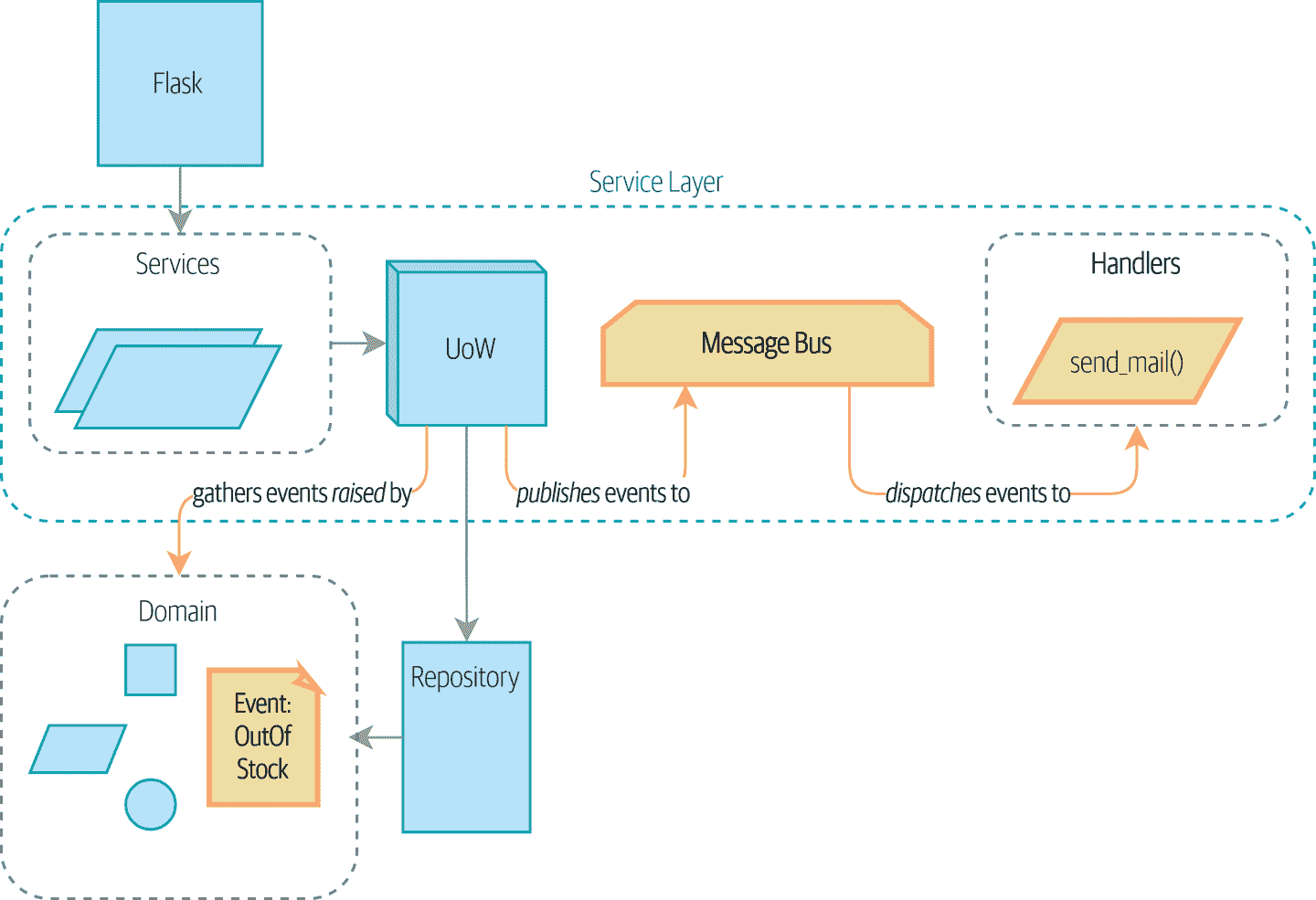
图 8-1:事件在系统中流动
提示
本章的代码在 GitHub 的 chapter_08_events_and_message_bus 分支中(https://oreil.ly/M-JuL):
git clone https://github.com/cosmicpython/code.git
cd code
git checkout chapter_08_events_and_message_bus
# or to code along, checkout the previous chapter:
git checkout chapter_07_aggregate
避免搞乱
所以。当我们库存不足时发送电子邮件提醒。当我们有新的要求,比如真的与核心领域无关的要求时,很容易开始将这些东西倒入我们的网络控制器中。
首先,让我们避免把我们的网络控制器搞乱
作为一次性的黑客,这可能还可以:
只是把它放在端点上——会有什么问题吗?(src/allocation/entrypoints/flask_app.py)
@app.route("/allocate", methods=['POST'])
def allocate_endpoint():
line = model.OrderLine(
request.json['orderid'],
request.json['sku'],
request.json['qty'],
)
try:
uow = unit_of_work.SqlAlchemyUnitOfWork()
batchref = services.allocate(line, uow)
except (model.OutOfStock, services.InvalidSku) as e:
send_mail(
'out of stock',
'stock_admin@made.com',
f'{line.orderid} - {line.sku}'
)
return jsonify({'message': str(e)}), 400
return jsonify({'batchref': batchref}), 201
…但很容易看出,我们很快就会因为这样修补东西而陷入混乱。发送电子邮件不是我们的 HTTP 层的工作,我们希望能够对这个新功能进行单元测试。
还有,让我们不要搞乱我们的模型
假设我们不想把这段代码放到我们的网络控制器中,因为我们希望它们尽可能薄,我们可以考虑把它放在源头,即模型中:
我们模型中的发送电子邮件代码也不够好(src/allocation/domain/model.py)
def allocate(self, line: OrderLine) -> str:
try:
batch = next(
b for b in sorted(self.batches) if b.can_allocate(line)
)
#...
except StopIteration:
email.send_mail('stock@made.com', f'Out of stock for {line.sku}')
raise OutOfStock(f'Out of stock for sku {line.sku}')
但这甚至更糟!我们不希望我们的模型对email.send_mail这样的基础设施问题有任何依赖。
这个发送电子邮件的东西是不受欢迎的混乱,破坏了我们系统的干净流程。我们希望的是保持我们的领域模型专注于规则“你不能分配比实际可用的东西更多”。
领域模型的工作是知道我们的库存不足,但发送警报的责任属于其他地方。我们应该能够打开或关闭此功能,或者切换到短信通知,而无需更改我们领域模型的规则。
或者服务层!
要求“尝试分配一些库存,并在失败时发送电子邮件”是工作流编排的一个例子:这是系统必须遵循的一组步骤,以实现一个目标。
我们编写了一个服务层来为我们管理编排,但即使在这里,这个功能也感觉不合适:
而在服务层,它是不合适的(src/allocation/service_layer/services.py)
def allocate(
orderid: str, sku: str, qty: int,
uow: unit_of_work.AbstractUnitOfWork
) -> str:
line = OrderLine(orderid, sku, qty)
with uow:
product = uow.products.get(sku=line.sku)
if product is None:
raise InvalidSku(f'Invalid sku {line.sku}')
try:
batchref = product.allocate(line)
uow.commit()
return batchref
except model.OutOfStock:
email.send_mail('stock@made.com', f'Out of stock for {line.sku}')
raise
捕获异常并重新引发它?这可能更糟,但肯定会让我们不开心。为什么这么难找到一个合适的家来放置这段代码呢?
单一责任原则
实际上,这是单一责任原则(SRP)的违反。¹我们的用例是分配。我们的端点、服务函数和领域方法都称为allocate,而不是allocate_and_send_mail_if_out_of_stock。
提示
经验法则:如果你不能在不使用“然后”或“和”这样的词语描述你的函数做什么,你可能会违反 SRP。
SRP 的一个表述是每个类只应该有一个改变的原因。当我们从电子邮件切换到短信时,我们不应该更新我们的allocate()函数,因为这显然是一个单独的责任。
为了解决这个问题,我们将把编排分成单独的步骤,这样不同的关注点就不会纠缠在一起。²领域模型的工作是知道我们的库存不足,但发送警报的责任属于其他地方。我们应该能够随时打开或关闭此功能,或者切换到短信通知,而无需更改我们领域模型的规则。
我们也希望保持服务层不受实现细节的影响。我们希望将依赖倒置原则应用于通知,使我们的服务层依赖于一个抽象,就像我们通过使用工作单元来避免依赖于数据库一样。
全体乘客上车!
我们要介绍的模式是领域事件和消息总线。我们可以以几种方式实现它们,所以我们将展示一些方式,然后选择我们最喜欢的方式。
模型记录事件
首先,我们的模型不再关心电子邮件,而是负责记录事件——关于已发生事情的事实。我们将使用消息总线来响应事件并调用新的操作。
事件是简单的数据类
事件是一种值对象。事件没有任何行为,因为它们是纯数据结构。我们总是用领域的语言命名事件,并将其视为我们领域模型的一部分。
我们可以将它们存储在model.py中,但我们可能会将它们保留在它们自己的文件中(现在可能是考虑重构出一个名为domain的目录的好时机,这样我们就有domain/model.py和domain/events.py):
事件类(src/allocation/domain/events.py)
from dataclasses import dataclass
class Event: #(1)
pass
@dataclass
class OutOfStock(Event): #(2)
sku: str
①
一旦我们有了一些事件,我们会发现有一个可以存储共同属性的父类很有用。它对于我们消息总线中的类型提示也很有用,您很快就会看到。
②
dataclasses对于领域事件也很好。
模型引发事件
当我们的领域模型记录发生的事实时,我们说它引发了一个事件。
从外部看,它将是这样的;如果我们要求Product分配但无法分配,它应该引发一个事件:
测试我们的聚合以引发事件(tests/unit/test_product.py)
def test_records_out_of_stock_event_if_cannot_allocate():
batch = Batch("batch1", "SMALL-FORK", 10, eta=today)
product = Product(sku="SMALL-FORK", batches=[batch])
product.allocate(OrderLine("order1", "SMALL-FORK", 10))
allocation = product.allocate(OrderLine("order2", "SMALL-FORK", 1))
assert product.events[-1] == events.OutOfStock(sku="SMALL-FORK") #(1)
assert allocation is None
①
我们的聚合将公开一个名为.events的新属性,其中包含关于发生了什么事情的事实列表,以Event对象的形式。
模型在内部的样子如下:
模型引发领域事件(src/allocation/domain/model.py)
class Product:
def __init__(self, sku: str, batches: List[Batch], version_number: int = 0):
self.sku = sku
self.batches = batches
self.version_number = version_number
self.events = [] # type: List[events.Event] #(1)
def allocate(self, line: OrderLine) -> str:
try:
#...
except StopIteration:
self.events.append(events.OutOfStock(line.sku)) #(2)
# raise OutOfStock(f"Out of stock for sku {line.sku}") #(3)
return None
①
这是我们新的.events属性的用法。
②
我们不是直接调用一些发送电子邮件的代码,而是在事件发生的地方记录这些事件,只使用领域的语言。
③
我们还将停止为缺货情况引发异常。事件将执行异常的工作。
注意
实际上,我们正在解决到目前为止我们一直存在的代码异味,即我们一直在使用异常进行控制流。一般来说,如果你正在实现领域事件,不要引发异常来描述相同的领域概念。正如你将在稍后处理工作单元模式中处理事件时所看到的,必须同时考虑事件和异常是令人困惑的。
消息总线将事件映射到处理程序
消息总线基本上是说:“当我看到这个事件时,我应该调用以下处理程序函数。”换句话说,这是一个简单的发布-订阅系统。处理程序订阅接收事件,我们将其发布到总线上。听起来比实际困难,我们通常用字典来实现它:
简单消息总线(src/allocation/service_layer/messagebus.py)
def handle(event: events.Event):
for handler in HANDLERS[type(event)]:
handler(event)
def send_out_of_stock_notification(event: events.OutOfStock):
email.send_mail(
'stock@made.com',
f'Out of stock for {event.sku}',
)
HANDLERS = {
events.OutOfStock: [send_out_of_stock_notification],
} # type: Dict[Type[events.Event], List[Callable]]
注意
请注意,实现的消息总线并不会给我们并发性,因为一次只有一个处理程序会运行。我们的目标不是支持并行线程,而是在概念上分离任务,并尽可能使每个 UoW 尽可能小。这有助于我们理解代码库,因为每个用例的运行“配方”都写在一个地方。请参阅以下侧边栏。
选项 1:服务层从模型中获取事件并将其放在消息总线上
我们的领域模型会触发事件,我们的消息总线会在事件发生时调用正确的处理程序。现在我们需要的是连接这两者。我们需要某种方式来捕捉模型中的事件并将它们传递给消息总线——发布步骤。
最简单的方法是在我们的服务层中添加一些代码:
具有显式消息总线的服务层(src/allocation/service_layer/services.py)
from . import messagebus
...
def allocate(
orderid: str, sku: str, qty: int,
uow: unit_of_work.AbstractUnitOfWork,
) -> str:
line = OrderLine(orderid, sku, qty)
with uow:
product = uow.products.get(sku=line.sku)
if product is None:
raise InvalidSku(f"Invalid sku {line.sku}")
try: #(1)
batchref = product.allocate(line)
uow.commit()
return batchref
finally: #(1)
messagebus.handle(product.events) #(2)
①
我们保留了我们丑陋的早期实现中的try/finally(我们还没有摆脱所有异常,只是OutOfStock)。
②
但现在,服务层不再直接依赖于电子邮件基础设施,而是负责将模型中的事件传递到消息总线。
这已经避免了我们在天真的实现中遇到的一些丑陋,我们有几个系统都是这样工作的,其中服务层明确地从聚合中收集事件并将其传递给消息总线。
选项 2:服务层引发自己的事件
我们使用的另一种变体是让服务层负责直接创建和触发事件,而不是由领域模型触发:
服务层直接调用 messagebus.handle(src/allocation/service_layer/services.py)
def allocate(
orderid: str, sku: str, qty: int,
uow: unit_of_work.AbstractUnitOfWork,
) -> str:
line = OrderLine(orderid, sku, qty)
with uow:
product = uow.products.get(sku=line.sku)
if product is None:
raise InvalidSku(f"Invalid sku {line.sku}")
batchref = product.allocate(line)
uow.commit() #(1)
if batchref is None:
messagebus.handle(events.OutOfStock(line.sku))
return batchref
①
与以前一样,即使我们无法分配,我们也会提交,因为这样代码更简单,更容易理解:除非出现问题,我们总是提交。在我们没有做任何更改时提交是安全的,并且保持代码整洁。
同样,我们的生产应用程序以这种方式实现了该模式。对你来说,适合你的方式将取决于你面临的特定权衡,但我们想向你展示我们认为最优雅的解决方案,即让工作单元负责收集和引发事件。
选项 3:UoW 将事件发布到消息总线
UoW 已经有了try/finally,并且它知道当前正在使用的所有聚合,因为它提供对存储库的访问。因此,这是一个很好的地方来发现事件并将它们传递给消息总线:
UoW 遇到消息总线(src/allocation/service_layer/unit_of_work.py)
class AbstractUnitOfWork(abc.ABC):
...
def commit(self):
self._commit() #(1)
self.publish_events() #(2)
def publish_events(self): #(2)
for product in self.products.seen: #(3)
while product.events:
event = product.events.pop(0)
messagebus.handle(event)
@abc.abstractmethod
def _commit(self):
raise NotImplementedError
...
class SqlAlchemyUnitOfWork(AbstractUnitOfWork):
...
def _commit(self): #(1)
self.session.commit()
①
我们将更改我们的提交方法,要求子类需要一个私有的._commit()方法。
②
提交后,我们遍历存储库所见的所有对象,并将它们的事件传递给消息总线。
③
这依赖于存储库跟踪已使用新属性.seen加载的聚合,正如您将在下一个清单中看到的那样。
注意
您是否想知道如果其中一个处理程序失败会发生什么?我们将在第十章中详细讨论错误处理。
存储库跟踪通过它的聚合(src/allocation/adapters/repository.py)
class AbstractRepository(abc.ABC):
def __init__(self):
self.seen = set() # type: Set[model.Product] #(1)
def add(self, product: model.Product): #(2)
self._add(product)
self.seen.add(product)
def get(self, sku) -> model.Product: #(3)
product = self._get(sku)
if product:
self.seen.add(product)
return product
@abc.abstractmethod
def _add(self, product: model.Product): #(2)
raise NotImplementedError
@abc.abstractmethod #(3)
def _get(self, sku) -> model.Product:
raise NotImplementedError
class SqlAlchemyRepository(AbstractRepository):
def __init__(self, session):
super().__init__()
self.session = session
def _add(self, product): #(2)
self.session.add(product)
def _get(self, sku): #(3)
return self.session.query(model.Product).filter_by(sku=sku).first()
①
为了使 UoW 能够发布新事件,它需要能够询问存储库在此会话期间使用了哪些Product对象。我们使用一个名为.seen的set来存储它们。这意味着我们的实现需要调用super().__init__()。
②
父add()方法将事物添加到.seen,现在需要子类实现._add()。
③
同样,.get()委托给一个._get()函数,由子类实现,以捕获已看到的对象。
注意
使用*._underscorey()*方法和子类化绝对不是您可以实现这些模式的唯一方式。在本章中尝试一下读者练习,并尝试一些替代方法。
在这种方式下,UoW 和存储库协作,自动跟踪实时对象并处理它们的事件后,服务层可以完全摆脱事件处理方面的问题:
服务层再次清洁(src/allocation/service_layer/services.py)
def allocate(
orderid: str, sku: str, qty: int,
uow: unit_of_work.AbstractUnitOfWork
) -> str:
line = OrderLine(orderid, sku, qty)
with uow:
product = uow.products.get(sku=line.sku)
if product is None:
raise InvalidSku(f'Invalid sku {line.sku}')
batchref = product.allocate(line)
uow.commit()
return batchref
我们还必须记住在服务层更改伪造品并在正确的位置调用super(),并实现下划线方法,但更改是最小的:
需要调整服务层伪造(tests/unit/test_services.py)
class FakeRepository(repository.AbstractRepository):
def __init__(self, products):
super().__init__()
self._products = set(products)
def _add(self, product):
self._products.add(product)
def _get(self, sku):
return next((p for p in self._products if p.sku == sku), None)
...
class FakeUnitOfWork(unit_of_work.AbstractUnitOfWork):
...
def _commit(self):
self.committed = True
您可能开始担心维护这些伪造品将成为一项维护负担。毫无疑问,这是一项工作,但根据我们的经验,这并不是很多工作。一旦您的项目启动并运行,存储库和 UoW 抽象的接口实际上并不会有太大变化。如果您使用 ABCs,它们将在事情变得不同步时提醒您。
总结
领域事件为我们提供了一种处理系统中工作流程的方式。我们经常发现,听取我们的领域专家的意见,他们以因果或时间方式表达需求,例如,“当我们尝试分配库存但没有可用时,我们应该向采购团队发送电子邮件。”
“当 X 时,然后 Y”这几个神奇的词经常告诉我们关于我们可以在系统中具体化的事件。在我们的模型中将事件作为第一类事物对我们有助于使我们的代码更具可测试性和可观察性,并有助于隔离关注点。
和表 8-1 显示了我们认为的权衡。
表 8-1. 领域事件:权衡
| 优点 | 缺点 |
|---|---|
| 当我们必须对请求做出多个动作的响应时,消息总线为我们提供了一种很好的分离责任的方式。 | 消息总线是一个额外的需要理解的东西;我们的实现中,工作单元为我们引发事件是巧妙但也是神奇的。当我们调用commit时,我们并不明显地知道我们还将去发送电子邮件给人们。 |
| 事件处理程序与“核心”应用程序逻辑很好地解耦,这样以后更改它们的实现就变得很容易。 | 更重要的是,隐藏的事件处理代码执行同步,这意味着直到所有事件的处理程序完成为止,您的服务层函数才能完成。这可能会在您的 Web 端点中引起意外的性能问题(添加异步处理是可能的,但会使事情变得更加混乱)。 |
| 领域事件是模拟现实世界的一种好方法,我们可以在与利益相关者建模时将其作为我们的业务语言的一部分使用。 | 更一般地说,基于事件驱动的工作流可能会令人困惑,因为在事物被分割到多个处理程序链之后,系统中就没有一个单一的地方可以理解请求将如何被满足。 |
| 你还会面临事件处理程序之间的循环依赖和无限循环的可能性。 |
事件不仅仅用于发送电子邮件。在第七章中,我们花了很多时间说服你应该定义聚合,或者我们保证一致性的边界。人们经常问,“如果我需要在一个请求的过程中更改多个聚合,我该怎么办?”现在我们有了回答这个问题所需的工具。
如果我们有两个可以在事务上隔离的事物(例如,订单和产品),那么我们可以通过使用事件使它们最终一致。当订单被取消时,我们应该找到为其分配的产品并移除这些分配。
在第九章中,我们将更详细地研究这个想法,因为我们将使用我们的新消息总线构建一个更复杂的工作流。
¹这个原则是SOLID中的S。
²我们的技术审阅员 Ed Jung 喜欢说,从命令式到基于事件的流程控制的转变将以前的编排变成了编舞。
第九章:深入研究消息总线
原文:9: Going to Town on the Message Bus
译者:飞龙
在本章中,我们将开始使事件对我们应用程序的内部结构更加重要。我们将从图 9-1 中的当前状态开始,其中事件是一个可选的副作用…
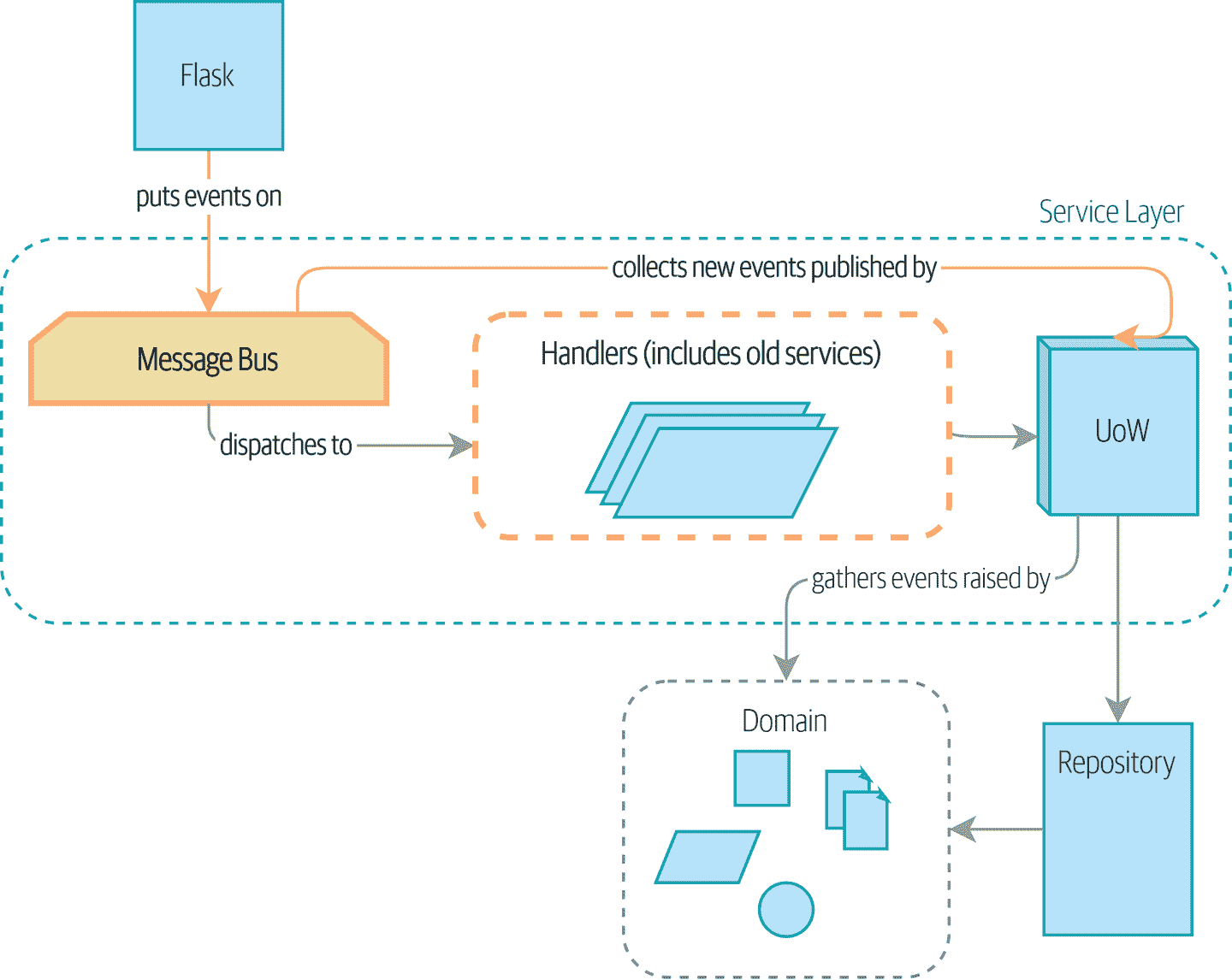
图 9-1:之前:消息总线是一个可选的附加组件
…到图 9-2 中的情况,所有内容都通过消息总线进行,我们的应用程序已经从根本上转变为消息处理器。
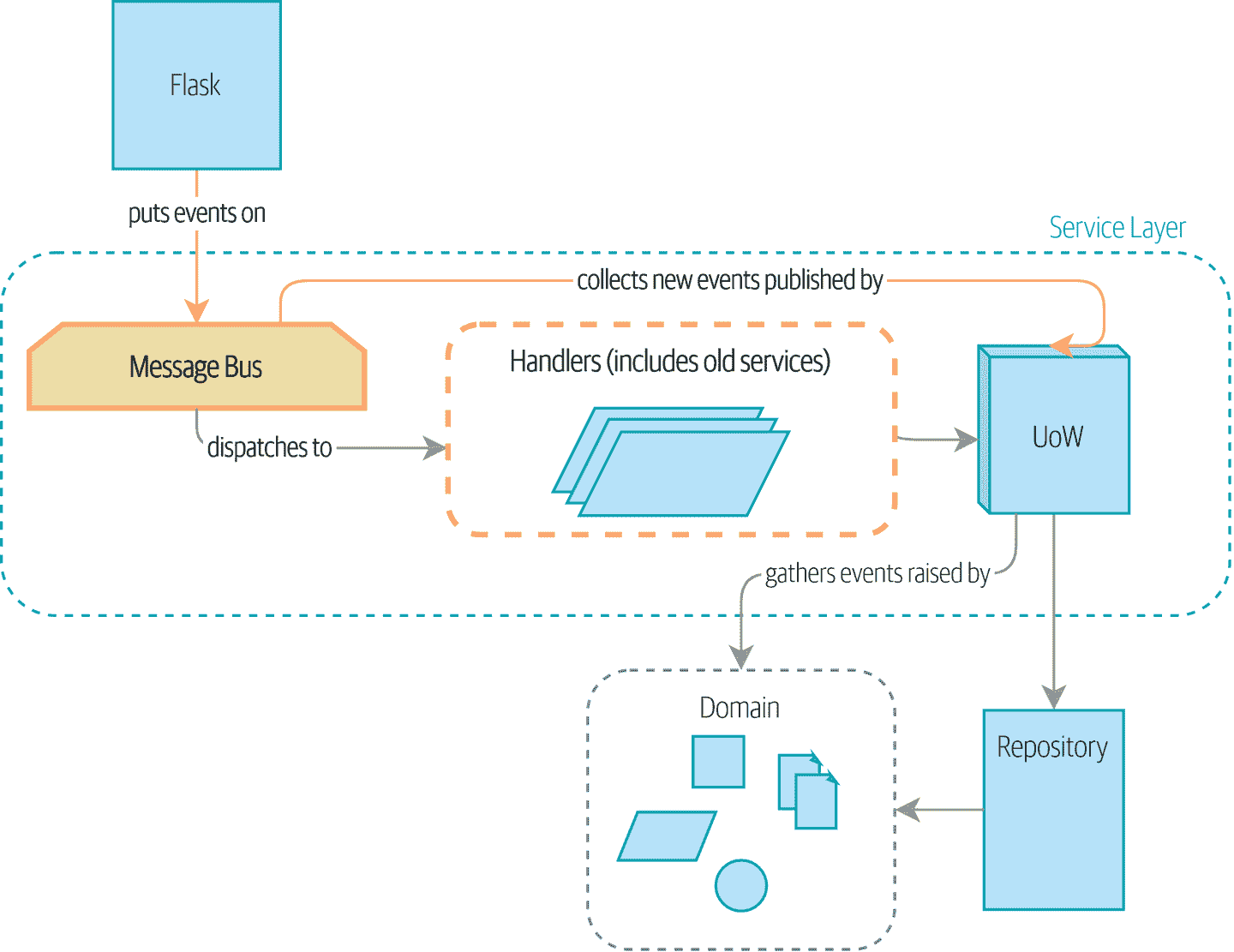
图 9-2:消息总线现在是服务层的主要入口点
提示
本章的代码在 GitHub 的 chapter_09_all_messagebus 分支中查看:
git clone https://github.com/cosmicpython/code.git
cd code
git checkout chapter_09_all_messagebus
# or to code along, checkout the previous chapter:
git checkout chapter_08_events_and_message_bus
一个新需求引领我们走向新的架构
Rich Hickey 谈到了定位软件,指的是长时间运行,管理真实世界流程的软件。例子包括仓库管理系统、物流调度器和工资系统。
这个软件很难编写,因为在现实世界的物理对象和不可靠的人类中经常发生意外。例如:
-
在盘点期间,我们发现三个
SPRINGY-MATTRESS被漏水的屋顶水损坏了。 -
一批
RELIABLE-FORK缺少所需的文件,并被海关扣押了几周。随后有三个RELIABLE-FORK未能通过安全测试并被销毁。 -
全球缎带短缺意味着我们无法制造下一批
SPARKLY-BOOKCASE。
在这些情况下,我们了解到当批次已经在系统中时需要更改批次数量。也许有人在清单中弄错了数字,或者也许有些沙发从卡车上掉下来。在与业务的对话后,¹我们将情况建模为图 9-3 中的情况。

图 9-3:批次数量更改意味着取消分配和重新分配
[ditaa, apwp_0903]
+----------+ /---- +------------+ +--------------------+
| Batch |--> |RULE| --> | Deallocate | ----> | AllocationRequired |
| Quantity | ----/ +------------+-+ +--------------------+-+
| Changed | | Deallocate | ----> | AllocationRequired |
+----------+ +------------+-+ +--------------------+-+
| Deallocate | ----> | AllocationRequired |
+------------+ +--------------------+
我们将称之为BatchQuantityChanged的事件应该导致我们改变批次的数量,是的,但也要应用业务规则:如果新数量降到已分配的总数以下,我们需要从该批次取消分配这些订单。然后每个订单将需要新的分配,我们可以将其捕获为AllocationRequired事件。
也许你已经预料到我们的内部消息总线和事件可以帮助实现这一要求。我们可以定义一个名为change_batch_quantity的服务,它知道如何调整批次数量,还知道如何取消分配任何多余的订单行,然后每个取消分配可以发出一个AllocationRequired事件,可以在单独的事务中转发给现有的allocate服务。再一次,我们的消息总线帮助我们执行单一责任原则,并且它允许我们对事务和数据完整性做出选择。
想象一种架构变化:一切都将成为事件处理程序
但在我们着手之前,想想我们要走向何方。我们的系统有两种流程:
-
由服务层函数处理的 API 调用
-
内部事件(可能作为服务层函数的副作用引发)及其处理程序(反过来调用服务层函数)
如果一切都是事件处理程序,会不会更容易?如果我们重新思考我们的 API 调用作为捕获事件,服务层函数也可以成为事件处理程序,我们不再需要区分内部和外部事件处理程序:
-
services.allocate()可能是AllocationRequired事件的处理程序,并且可以发出Allocated事件作为其输出。 -
services.add_batch()可能是BatchCreated事件的处理程序。²
我们的新需求将符合相同的模式:
-
名为
BatchQuantityChanged的事件可以调用名为change_batch_quantity()的处理程序。 -
它可能引发的新
AllocationRequired事件也可以传递给services.allocate(),因此从 API 中产生的全新分配和内部由取消分配触发的重新分配之间没有概念上的区别。
听起来有点多?让我们逐渐朝着这个方向努力。我们将遵循预备重构工作流程,又称“使变化变得容易;然后进行容易的变化”:
-
我们将我们的服务层重构为事件处理程序。我们可以习惯于事件是描述系统输入的方式。特别是,现有的
services.allocate()函数将成为名为AllocationRequired的事件的处理程序。 -
我们构建了一个端到端测试,将
BatchQuantityChanged事件放入系统,并查找输出的Allocated事件。 -
我们的实现在概念上将非常简单:
BatchQuantityChanged事件的新处理程序,其实现将发出AllocationRequired事件,然后将由 API 使用的分配的确切相同的处理程序处理。
在此过程中,我们将对消息总线和 UoW 进行小的调整,将将新事件放入消息总线的责任移到消息总线本身。
将服务函数重构为消息处理程序
我们首先定义了两个事件,捕捉我们当前的 API 输入——AllocationRequired和BatchCreated:
BatchCreated 和 AllocationRequired 事件(src/allocation/domain/events.py)
@dataclass
class BatchCreated(Event):
ref: str
sku: str
qty: int
eta: Optional[date] = None
...
@dataclass
class AllocationRequired(Event):
orderid: str
sku: str
qty: int
然后我们将services.py重命名为handlers.py;我们添加了send_out_of_stock_notification的现有消息处理程序;最重要的是,我们更改了所有处理程序,使它们具有相同的输入,即事件和 UoW:
处理程序和服务是相同的东西(src/allocation/service_layer/handlers.py)
def add_batch(
event: events.BatchCreated, uow: unit_of_work.AbstractUnitOfWork
):
with uow:
product = uow.products.get(sku=event.sku)
...
def allocate(
event: events.AllocationRequired, uow: unit_of_work.AbstractUnitOfWork
) -> str:
line = OrderLine(event.orderid, event.sku, event.qty)
...
def send_out_of_stock_notification(
event: events.OutOfStock, uow: unit_of_work.AbstractUnitOfWork,
):
email.send(
'stock@made.com',
f'Out of stock for {event.sku}',
)
这个变化可能更清晰地显示为一个差异:
从服务更改为处理程序(src/allocation/service_layer/handlers.py)
def add_batch(
- ref: str, sku: str, qty: int, eta: Optional[date],
- uow: unit_of_work.AbstractUnitOfWork
+ event: events.BatchCreated, uow: unit_of_work.AbstractUnitOfWork
):
with uow:
- product = uow.products.get(sku=sku)
+ product = uow.products.get(sku=event.sku)
...
def allocate(
- orderid: str, sku: str, qty: int,
- uow: unit_of_work.AbstractUnitOfWork
+ event: events.AllocationRequired, uow: unit_of_work.AbstractUnitOfWork
) -> str:
- line = OrderLine(orderid, sku, qty)
+ line = OrderLine(event.orderid, event.sku, event.qty)
...
+
+def send_out_of_stock_notification(
+ event: events.OutOfStock, uow: unit_of_work.AbstractUnitOfWork,
+):
+ email.send(
...
在此过程中,我们使我们的服务层 API 更加结构化和一致。它曾经是一堆原语,现在使用了定义明确的对象(见下面的侧边栏)。
消息总线现在从 UoW 收集事件
我们的事件处理程序现在需要一个 UoW。此外,随着我们的消息总线变得更加核心于我们的应用程序,明智的做法是明确地负责收集和处理新事件。到目前为止,UoW 和消息总线之间存在一种循环依赖,因此这将使其成为单向:
处理接受 UoW 并管理队列(src/allocation/service_layer/messagebus.py)
def handle(
event: events.Event,
uow: unit_of_work.AbstractUnitOfWork, #(1)
):
queue = [event] #(2)
while queue:
event = queue.pop(0) #(3)
for handler in HANDLERS[type(event)]: #(3)
handler(event, uow=uow) #(4)
queue.extend(uow.collect_new_events()) #(5)
①
每次启动时,消息总线现在都会传递 UoW。
②
当我们开始处理我们的第一个事件时,我们启动一个队列。
③
我们从队列的前面弹出事件并调用它们的处理程序(HANDLERS字典没有改变;它仍将事件类型映射到处理程序函数)。
④
消息总线将 UoW 传递给每个处理程序。
⑤
每个处理程序完成后,我们收集生成的任何新事件,并将它们添加到队列中。
在unit_of_work.py中,publish_events()变成了一个不太活跃的方法,collect_new_events():
UoW 不再直接将事件放入总线(src/allocation/service_layer/unit_of_work.py)
-from . import messagebus #(1)
class AbstractUnitOfWork(abc.ABC):
@@ -22,13 +21,11 @@ class AbstractUnitOfWork(abc.ABC):
def commit(self):
self._commit()
- self.publish_events() #(2)
- def publish_events(self):
+ def collect_new_events(self):
for product in self.products.seen:
while product.events:
- event = product.events.pop(0)
- messagebus.handle(event)
+ yield product.events.pop(0) #(3)
①
unit_of_work模块现在不再依赖于messagebus。
②
我们不再自动在提交时publish_events。消息总线现在跟踪事件队列。
③
而 UoW 不再主动将事件放在消息总线上;它只是使它们可用。
我们的测试也都是以事件为基础编写的
我们的测试现在通过创建事件并将它们放在消息总线上来操作,而不是直接调用服务层函数:
处理程序测试使用事件(tests/unit/test_handlers.py)
class TestAddBatch:
def test_for_new_product(self):
uow = FakeUnitOfWork()
- services.add_batch("b1", "CRUNCHY-ARMCHAIR", 100, None, uow)
+ messagebus.handle(
+ events.BatchCreated("b1", "CRUNCHY-ARMCHAIR", 100, None), uow
+ )
assert uow.products.get("CRUNCHY-ARMCHAIR") is not None
assert uow.committed
...
class TestAllocate:
def test_returns_allocation(self):
uow = FakeUnitOfWork()
- services.add_batch("batch1", "COMPLICATED-LAMP", 100, None, uow)
- result = services.allocate("o1", "COMPLICATED-LAMP", 10, uow)
+ messagebus.handle(
+ events.BatchCreated("batch1", "COMPLICATED-LAMP", 100, None), uow
+ )
+ result = messagebus.handle(
+ events.AllocationRequired("o1", "COMPLICATED-LAMP", 10), uow
+ )
assert result == "batch1"
临时丑陋的黑客:消息总线必须返回结果
我们的 API 和服务层目前希望在调用我们的allocate()处理程序时知道分配的批次参考。这意味着我们需要在我们的消息总线上进行临时修改,让它返回事件:
消息总线返回结果(src/allocation/service_layer/messagebus.py)
def handle(event: events.Event, uow: unit_of_work.AbstractUnitOfWork):
+ results = []
queue = [event]
while queue:
event = queue.pop(0)
for handler in HANDLERS[type(event)]:
- handler(event, uow=uow)
+ results.append(handler(event, uow=uow))
queue.extend(uow.collect_new_events())
+ return results
这是因为我们在系统中混合了读取和写入责任。我们将在第十二章中回来修复这个瑕疵。
修改我们的 API 以与事件配合使用
Flask 将消息总线更改为差异(src/allocation/entrypoints/flask_app.py)
@app.route("/allocate", methods=["POST"])
def allocate_endpoint():
try:
- batchref = services.allocate(
- request.json["orderid"], #(1)
- request.json["sku"],
- request.json["qty"],
- unit_of_work.SqlAlchemyUnitOfWork(),
+ event = events.AllocationRequired( #(2)
+ request.json["orderid"], request.json["sku"], request.json["qty"]
)
+ results = messagebus.handle(event, unit_of_work.SqlAlchemyUnitOfWork()) #(3)
+ batchref = results.pop(0)
except InvalidSku as e:
①
而不是使用从请求 JSON 中提取的一堆基元调用服务层…
②
我们实例化一个事件。
③
然后我们将其传递给消息总线。
我们应该回到一个完全功能的应用程序,但现在是完全事件驱动的:
-
曾经是服务层函数现在是事件处理程序。
-
这使它们与我们的领域模型引发的内部事件处理的函数相同。
-
我们使用事件作为捕获系统输入的数据结构,以及内部工作包的交接。
-
整个应用现在最好被描述为消息处理器,或者如果您愿意的话,是事件处理器。我们将在下一章中讨论区别。
实施我们的新需求
我们已经完成了重构阶段。让我们看看我们是否真的“使变化变得容易”。让我们实施我们的新需求,如图 9-4 所示:我们将接收一些新的BatchQuantityChanged事件作为我们的输入,并将它们传递给一个处理程序,然后该处理程序可能会发出一些AllocationRequired事件,然后这些事件将返回到我们现有的重新分配处理程序。
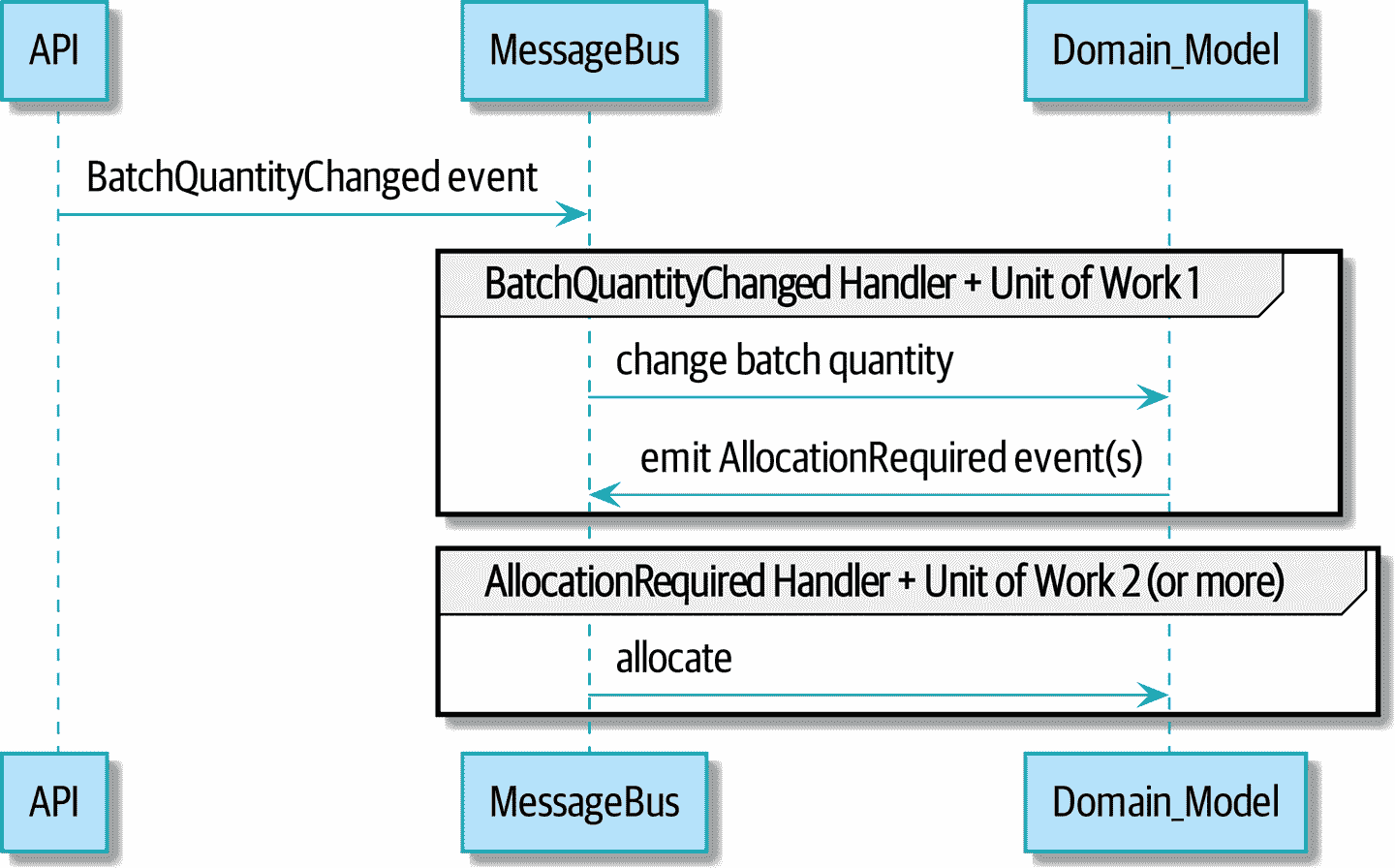
图 9-4:重新分配流程的序列图
[plantuml, apwp_0904, config=plantuml.cfg]
@startuml
API -> MessageBus : BatchQuantityChanged event
group BatchQuantityChanged Handler + Unit of Work 1
MessageBus -> Domain_Model : change batch quantity
Domain_Model -> MessageBus : emit AllocationRequired event(s)
end
group AllocationRequired Handler + Unit of Work 2 (or more)
MessageBus -> Domain_Model : allocate
end
@enduml
警告
当您将这些事情分开到两个工作单元时,您现在有两个数据库事务,因此您会面临完整性问题:可能会发生某些事情,导致第一个事务完成,但第二个事务没有完成。您需要考虑这是否可以接受,以及是否需要注意它何时发生并采取措施。有关更多讨论,请参见“Footguns”。
我们的新事件
告诉我们批次数量已更改的事件很简单;它只需要批次参考和新数量:
新事件(src/allocation/domain/events.py)
@dataclass
class BatchQuantityChanged(Event):
ref: str
qty: int
通过测试驱动新的处理程序
遵循第四章中学到的教训,我们可以以“高速”运行,并以事件为基础的最高抽象级别编写我们的单元测试。它们可能看起来像这样:
处理程序测试用于 change_batch_quantity(tests/unit/test_handlers.py)
class TestChangeBatchQuantity:
def test_changes_available_quantity(self):
uow = FakeUnitOfWork()
messagebus.handle(
events.BatchCreated("batch1", "ADORABLE-SETTEE", 100, None), uow
)
[batch] = uow.products.get(sku="ADORABLE-SETTEE").batches
assert batch.available_quantity == 100 #(1)
messagebus.handle(events.BatchQuantityChanged("batch1", 50), uow)
assert batch.available_quantity == 50 #(1)
def test_reallocates_if_necessary(self):
uow = FakeUnitOfWork()
event_history = [
events.BatchCreated("batch1", "INDIFFERENT-TABLE", 50, None),
events.BatchCreated("batch2", "INDIFFERENT-TABLE", 50, date.today()),
events.AllocationRequired("order1", "INDIFFERENT-TABLE", 20),
events.AllocationRequired("order2", "INDIFFERENT-TABLE", 20),
]
for e in event_history:
messagebus.handle(e, uow)
[batch1, batch2] = uow.products.get(sku="INDIFFERENT-TABLE").batches
assert batch1.available_quantity == 10
assert batch2.available_quantity == 50
messagebus.handle(events.BatchQuantityChanged("batch1", 25), uow)
# order1 or order2 will be deallocated, so we'll have 25 - 20
assert batch1.available_quantity == 5 #(2)
# and 20 will be reallocated to the next batch
assert batch2.available_quantity == 30 #(2)
①
简单情况将非常容易实现;我们只需修改数量。
②
但是,如果我们尝试将数量更改为少于已分配的数量,我们将需要至少取消分配一个订单,并且我们期望重新分配到一个新批次。
实施
我们的新处理程序非常简单:
处理程序委托给模型层(src/allocation/service_layer/handlers.py)
def change_batch_quantity(
event: events.BatchQuantityChanged, uow: unit_of_work.AbstractUnitOfWork
):
with uow:
product = uow.products.get_by_batchref(batchref=event.ref)
product.change_batch_quantity(ref=event.ref, qty=event.qty)
uow.commit()
我们意识到我们将需要在我们的存储库上有一个新的查询类型:
我们的存储库上有一个新的查询类型(src/allocation/adapters/repository.py)
class AbstractRepository(abc.ABC):
...
def get(self, sku) -> model.Product:
...
def get_by_batchref(self, batchref) -> model.Product:
product = self._get_by_batchref(batchref)
if product:
self.seen.add(product)
return product
@abc.abstractmethod
def _add(self, product: model.Product):
raise NotImplementedError
@abc.abstractmethod
def _get(self, sku) -> model.Product:
raise NotImplementedError
@abc.abstractmethod
def _get_by_batchref(self, batchref) -> model.Product:
raise NotImplementedError
...
class SqlAlchemyRepository(AbstractRepository):
...
def _get(self, sku):
return self.session.query(model.Product).filter_by(sku=sku).first()
def _get_by_batchref(self, batchref):
return self.session.query(model.Product).join(model.Batch).filter(
orm.batches.c.reference == batchref,
).first()
还有我们的FakeRepository:
也更新了虚假存储库(tests/unit/test_handlers.py)
class FakeRepository(repository.AbstractRepository):
...
def _get(self, sku):
return next((p for p in self._products if p.sku == sku), None)
def _get_by_batchref(self, batchref):
return next((
p for p in self._products for b in p.batches
if b.reference == batchref
), None)
注意
我们正在向我们的存储库添加一个查询,以使这个用例更容易实现。只要我们的查询返回单个聚合,我们就不会违反任何规则。如果你发现自己在存储库上编写复杂的查询,你可能需要考虑不同的设计。特别是像get_most_popular_products或find_products_by_order_id这样的方法肯定会触发我们的警觉。第十一章和结语中有一些关于管理复杂查询的提示。
领域模型上的新方法
我们向模型添加了新的方法,该方法在内部进行数量更改和取消分配,并发布新事件。我们还修改了现有的分配函数以发布事件:
我们的模型发展以满足新的需求(src/allocation/domain/model.py)
class Product:
...
def change_batch_quantity(self, ref: str, qty: int):
batch = next(b for b in self.batches if b.reference == ref)
batch._purchased_quantity = qty
while batch.available_quantity < 0:
line = batch.deallocate_one()
self.events.append(
events.AllocationRequired(line.orderid, line.sku, line.qty)
)
...
class Batch:
...
def deallocate_one(self) -> OrderLine:
return self._allocations.pop()
我们连接了我们的新处理程序:
消息总线增长(src/allocation/service_layer/messagebus.py)
HANDLERS = {
events.BatchCreated: [handlers.add_batch],
events.BatchQuantityChanged: [handlers.change_batch_quantity],
events.AllocationRequired: [handlers.allocate],
events.OutOfStock: [handlers.send_out_of_stock_notification],
} # type: Dict[Type[events.Event], List[Callable]]
而且我们的新需求已经完全实现了。
可选:使用虚假消息总线孤立地对事件处理程序进行单元测试
我们对重新分配工作流的主要测试是边缘到边缘(参见“测试驱动新处理程序”中的示例代码)。它使用真实的消息总线,并测试整个流程,其中BatchQuantityChanged事件处理程序触发取消分配,并发出新的AllocationRequired事件,然后由它们自己的处理程序处理。一个测试覆盖了一系列多个事件和处理程序。
根据您的事件链的复杂性,您可能会决定要对一些处理程序进行孤立测试。您可以使用“虚假”消息总线来实现这一点。
在我们的情况下,我们实际上通过修改FakeUnitOfWork上的publish_events()方法来进行干预,并将其与真实消息总线解耦,而是让它记录它看到的事件:
在 UoW 中实现的虚假消息总线(tests/unit/test_handlers.py)
class FakeUnitOfWorkWithFakeMessageBus(FakeUnitOfWork):
def __init__(self):
super().__init__()
self.events_published = [] # type: List[events.Event]
def publish_events(self):
for product in self.products.seen:
while product.events:
self.events_published.append(product.events.pop(0))
现在当我们使用FakeUnitOfWorkWithFakeMessageBus调用messagebus.handle()时,它只运行该事件的处理程序。因此,我们可以编写更加孤立的单元测试:不再检查所有的副作用,而是只检查BatchQuantityChanged是否导致已分配的总量下降到以下AllocationRequired:
在孤立环境中测试重新分配(tests/unit/test_handlers.py)
def test_reallocates_if_necessary_isolated():
uow = FakeUnitOfWorkWithFakeMessageBus()
# test setup as before
event_history = [
events.BatchCreated("batch1", "INDIFFERENT-TABLE", 50, None),
events.BatchCreated("batch2", "INDIFFERENT-TABLE", 50, date.today()),
events.AllocationRequired("order1", "INDIFFERENT-TABLE", 20),
events.AllocationRequired("order2", "INDIFFERENT-TABLE", 20),
]
for e in event_history:
messagebus.handle(e, uow)
[batch1, batch2] = uow.products.get(sku="INDIFFERENT-TABLE").batches
assert batch1.available_quantity == 10
assert batch2.available_quantity == 50
messagebus.handle(events.BatchQuantityChanged("batch1", 25), uow)
# assert on new events emitted rather than downstream side-effects
[reallocation_event] = uow.events_published
assert isinstance(reallocation_event, events.AllocationRequired)
assert reallocation_event.orderid in {'order1', 'order2'}
assert reallocation_event.sku == 'INDIFFERENT-TABLE'
是否要这样做取决于您的事件链的复杂性。我们建议,首先进行边缘到边缘的测试,只有在必要时才使用这种方法。
总结
让我们回顾一下我们取得了什么成就,并思考为什么我们这样做。
我们取得了什么成就?
事件是简单的数据类,定义了我们系统中的输入和内部消息的数据结构。从 DDD 的角度来看,这是非常强大的,因为事件通常在业务语言中表达得非常好(如果你还没有了解事件风暴,请查阅)。
处理程序是我们对事件做出反应的方式。它们可以调用我们的模型或调用外部服务。如果需要,我们可以为单个事件定义多个处理程序。处理程序还可以触发其他事件。这使我们可以非常细粒度地控制处理程序的操作,并真正遵守 SRP。
我们取得了什么成就?
我们使用这些架构模式的持续目标是尝试使我们应用程序的复杂性增长速度比其大小慢。当我们全力投入消息总线时,我们总是在架构复杂性方面付出代价(参见表 9-1),但我们为自己购买了一种可以处理几乎任意复杂需求的模式,而无需对我们做事情的方式进行任何进一步的概念或架构变化。
在这里,我们增加了一个相当复杂的用例(更改数量,取消分配,启动新事务,重新分配,发布外部通知),但在架构上,复杂性没有成本。我们增加了新的事件,新的处理程序和一个新的外部适配器(用于电子邮件),所有这些都是我们架构中现有的事物类别,我们知道如何理解和推理,并且很容易向新手解释。我们的各个部分各自有一个工作,它们以明确定义的方式相互连接,没有意外的副作用。
表 9-1. 整个应用程序是一个消息总线:权衡
| 优点 | 缺点 |
|---|---|
| 处理程序和服务是相同的,所以这更简单。 | 消息总线从 Web 的角度来看仍然是一种稍微不可预测的方式。您事先不知道什么时候会结束。 |
| 我们有一个很好的数据结构,用于系统的输入。 | 模型对象和事件之间将存在字段和结构的重复,这将产生维护成本。向一个对象添加字段通常意味着至少向另一个对象添加字段。 |
现在,您可能会想知道,那些BatchQuantityChanged事件将从哪里产生?答案将在几章后揭晓。但首先,让我们谈谈事件与命令。
¹ 基于事件的建模如此受欢迎,以至于出现了一种称为事件风暴的实践,用于促进基于事件的需求收集和领域模型阐述。
² 如果您对事件驱动架构有所了解,您可能会想,“其中一些事件听起来更像命令!” 请耐心等待!我们试图一次引入一个概念。在下一章中,我们将介绍命令和事件之间的区别。
³ 本章中的“简单”实现基本上使用messagebus.py模块本身来实现单例模式。
原文地址:https://blog.csdn.net/wizardforcel/article/details/135491176
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。
如若转载,请注明出处:http://www.7code.cn/show_53942.html
如若内容造成侵权/违法违规/事实不符,请联系代码007邮箱:suwngjj01@126.com进行投诉反馈,一经查实,立即删除!