本文介绍: 在《基于llama.cpp学习开源LLM本地部署》这篇中介绍了基于llama.cpp学习开源LLM本地部署。在最后简单介绍了API 的调用方式。不习惯命令行的同鞋,也可以试试 llama.cpp 界面的交互方式,本章就详细介绍一下server。llama.cpp 的 server 服务是基于 httplib 搭建的一个简单的HTTP API服务和与llama.cpp交互的简单web前端。-t N: 设置生成时要使用的线程数.: 设置批处理和提示处理期间使用的线程数。
目录
前言
一、llama.cpp 目录结构

二、llama.cpp 之 server 学习
1. 介绍
2. 编译部署
3. 启动服务

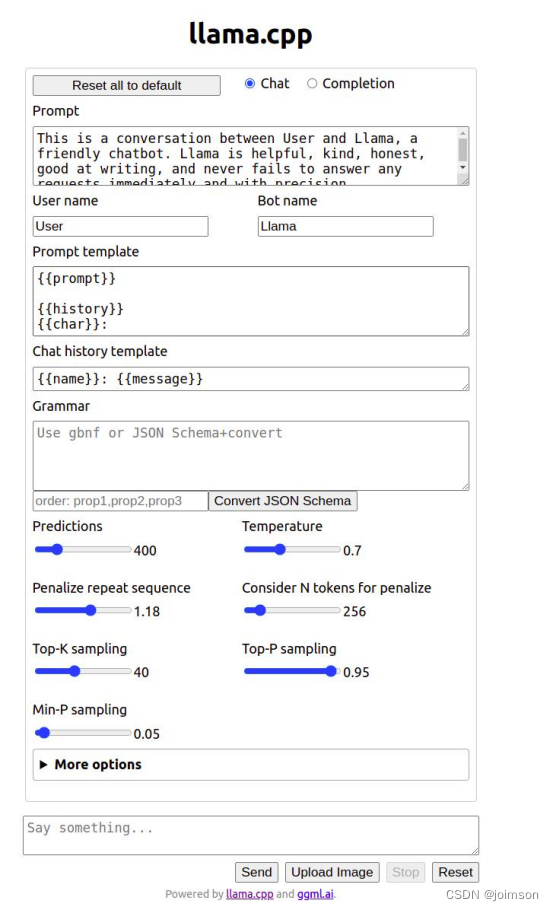
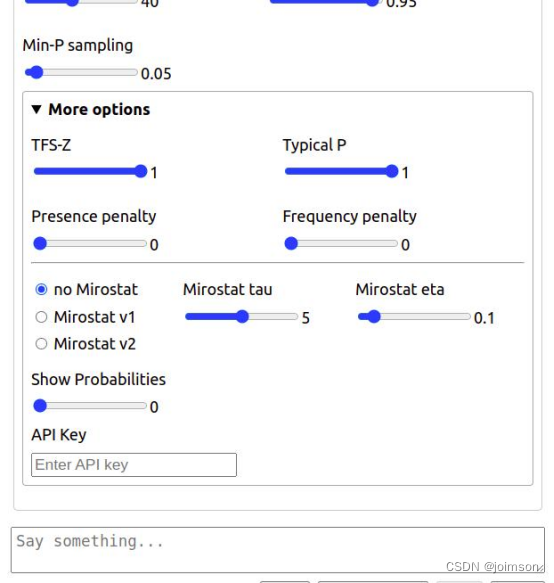
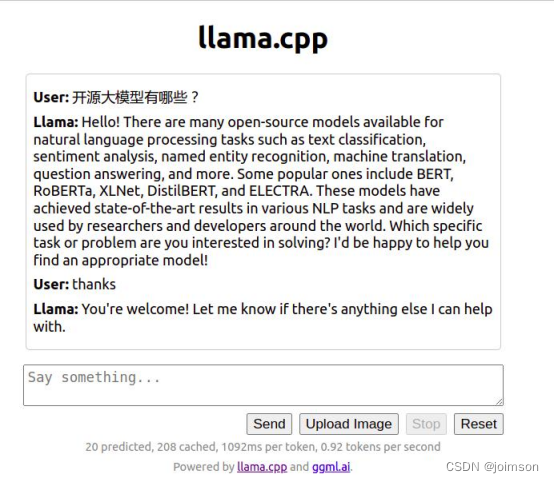
4、扩展或构建其他的 Web 前端
5、其他
声明:本站所有文章,如无特殊说明或标注,均为本站原创发布。任何个人或组织,在未征得本站同意时,禁止复制、盗用、采集、发布本站内容到任何网站、书籍等各类媒体平台。如若本站内容侵犯了原著者的合法权益,可联系我们进行处理。