本文介绍: Topic rack02的partition 0分区的副本为broker2(对应的rack为2)和broker1(对应的rack为0),其中broker2为leader(在⾮rack机制下仅能消费到leader中的数据)。在上述代码中,消费者配置中限制了rack为0,消费的分区为0,因此映射到broker1。验证二:客⼾端(消费者)验证:rack机制消费者可以消费到follower副本中的数据。验证一:机架感知特性将同一分区的副本分散到不同的机架上。(3)环境准备:kafka集群。
一、kafka生产者客户端
在kafka体系结构中有如下几个重要的概念:
- Producer:生产者,负责生产消息并投递到kafka broker的某个的分区中
- Consumer:消费者,负责消费kafka若干个分区中的消息
- Broker:kafka服务节点
1、整体架构:数据发送流程
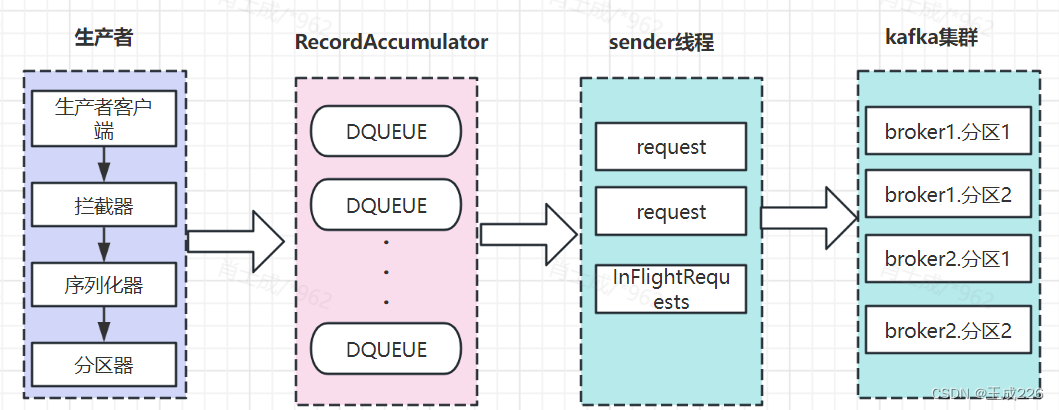
(1)生产者
- 拦截器
生产者的拦截器可以在消息发送前做一些拦截工作对数据进行相应的处理,比如:消息过滤、消息内容修改等。
package org.apache.kafka.clients.producer;
import org.apache.kafka.common.Configurable;
public interface ProducerInterceptor<K, V> extends Configurable {
//在将消息序列化和计算分区之前会调⽤该⽅法,⽤来对消息进⾏相应的定制化操作,如修改消息内容
public ProducerRecord<K, V> onSend(ProducerRecord<K, V> record);
//在消息被应答之前或者消息发送失败时调⽤该⽅法,优先于⽤⼾设定的Callback之前执⾏,如统计消息发送成功或失败的次数
public void onAcknowledgement(RecordMetadata metadata, Exception exception);
public void close();
}
- 序列化器
- 分区器
二、kafka数据可靠性保证
1、LEO和HW
2、工作流程
3、Leader Epoch
三、粘性分区策略
四、机架感知
1、概念
2、机架感知分区分配策略
3、验证
(1)验证目标
- 机架感知特性将同⼀分区的副本分散到不同的机架上
- rack机制消费者可以消费到follower副本中的数据
(2)参数配置
broker端配置:
- 配置名:broker.rack=my-rack-id
- 解释:broker属于的rack
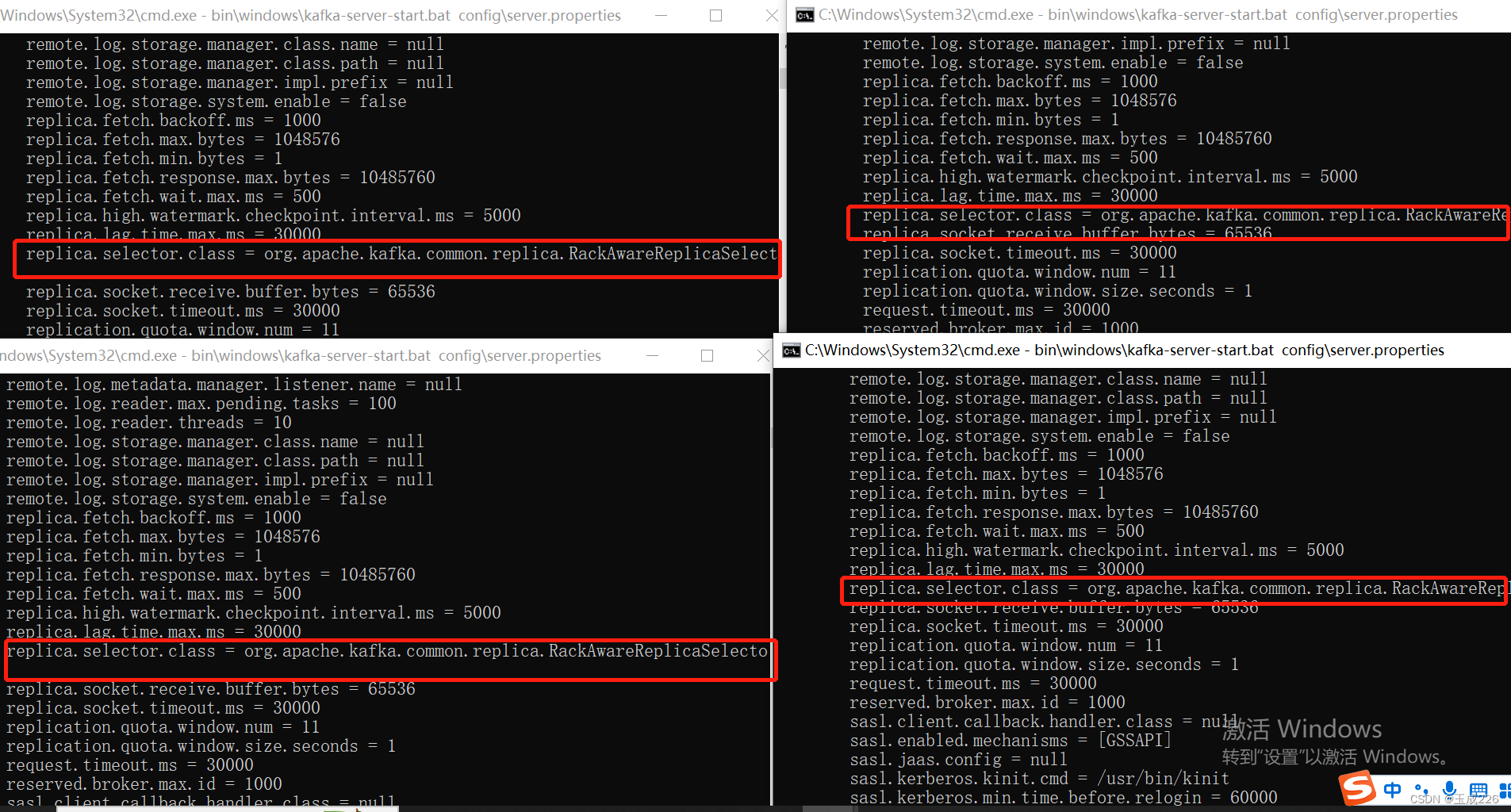
- 配置名:replica.selector.class
- 解释:ReplicaSelector实现类的全名,包括路径 (⽐如 RackAwareReplicaSelector 即按 rack id 指定消费)
Client端配置:
client.rack
- consumer端配置
- 配置名:client.rack
- 解释:这个参数需要和broker端指定的 broker.rack 相同,表⽰去哪个rack中获取数据。
- 默认:null
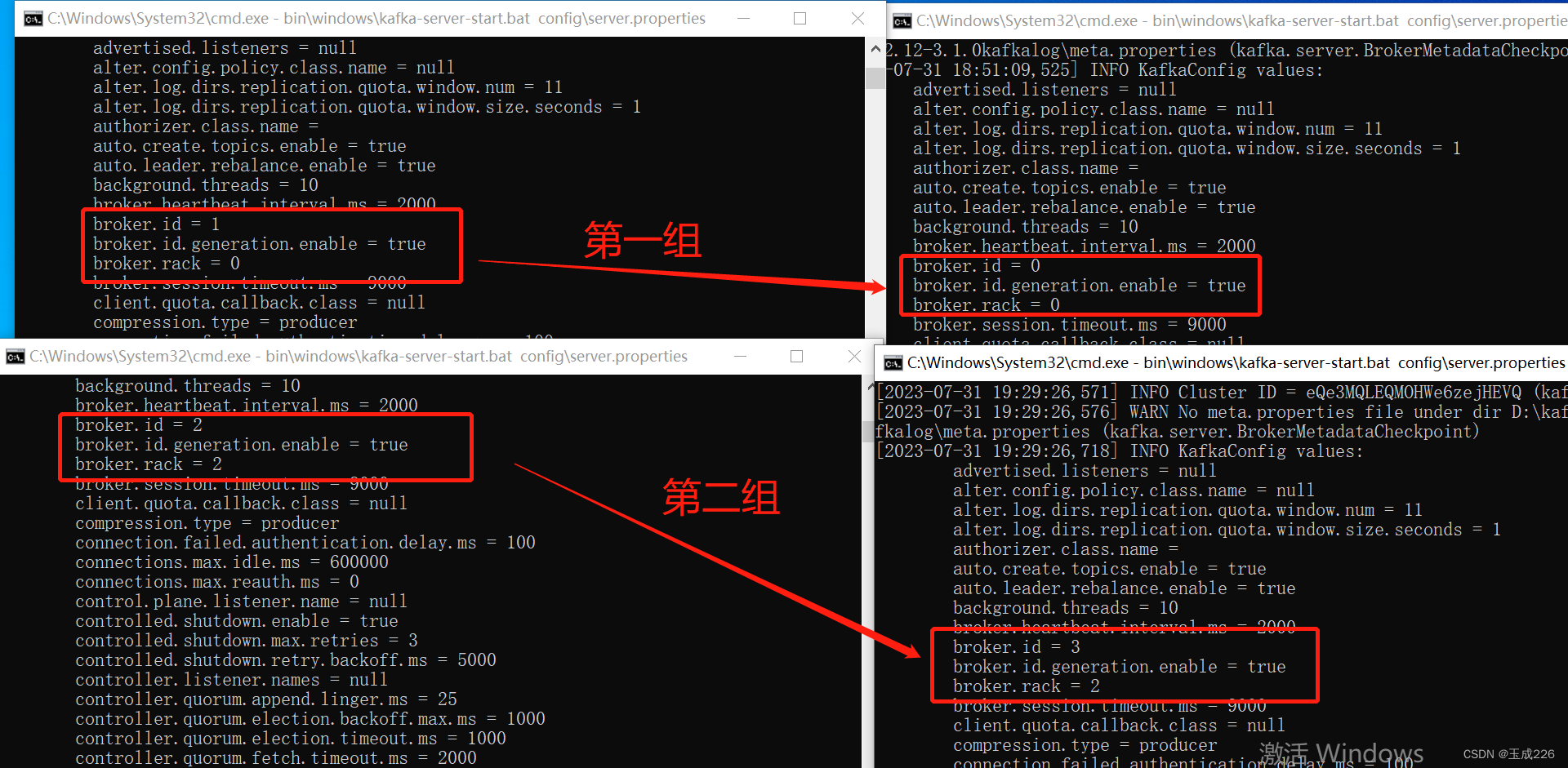
(3)环境准备:kafka集群
- kafka实例数: 4
- 两个kafka实例broker.rack配置为0,另外两个kafka实例broker.rack配置为了2,broker端配置如下:
server1:
broker.id=0
broker.rack=0
replica.selector.class=org.apache.kafka.common.replica.RackAwareReplicaSelector
server2:
broker.id=1
broker.rack=0
replica.selector.class=org.apache.kafka.common.replica.RackAwareReplicaSelector
server3
broker.id=2
broker.rack=2
replica.selector.class=org.apache.kafka.common.replica.RackAwareReplicaSelector
server4
broker.id=3
broker.rack=2
replica.selector.class=org.apache.kafka.common.replica.RackAwareReplicaSelector
启动kafka集群,服务端⽇志信息:
验证一:机架感知特性将同一分区的副本分散到不同的机架上
创建topic rack02,副本被分配到了broker1和2
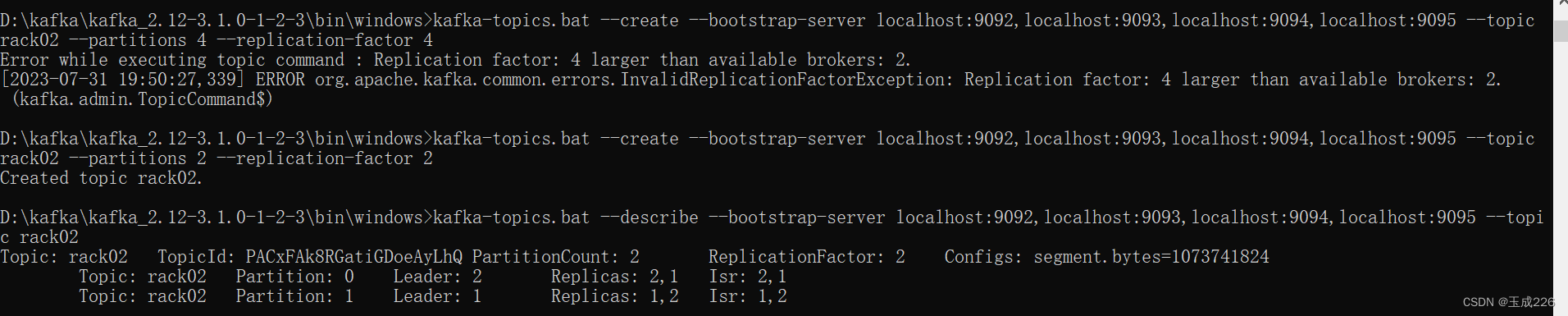
创建topic rack03 副本被分配到了0和3


验证二:客⼾端(消费者)验证:rack机制消费者可以消费到follower副本中的数据
验证代码如下:
package person.xsc.train.producer;
import org.apache.kafka.clients.consumer.ConsumerConfig;
import org.apache.kafka.clients.consumer.ConsumerRecord;
import org.apache.kafka.clients.consumer.ConsumerRecords;
import org.apache.kafka.clients.consumer.KafkaConsumer;
import org.apache.kafka.common.TopicPartition;
import org.apache.kafka.common.serialization.StringDeserializer;
import person.xsc.train.client.KafkaConsumerClient;
import person.xsc.train.constant.KafkaConstant;
import java.time.Duration;
import java.util.Arrays;
import java.util.Properties;
public class Demo {
public static KafkaConsumer<String, String> kafkaConsumer;
public static void main(String[] args) {
Properties properties = new Properties();
properties.put(KafkaConstant.BOOTSTRAP_SERVERS, "localhost:9093,localhos
properties.put(KafkaConstant.GROUP_ID, "test01");
properties.put(KafkaConstant.ENABLE_AUTO_COMMIT, "true");
properties.put(KafkaConstant.AUTO_COMMIT_INTERVAL_MS, "1000");
properties.put(KafkaConstant.KEY_DESERIALIZER, StringDeserializer.class.
properties.put(KafkaConstant.VALUE_DESERIALIZER, StringDeserializer.clas
properties.put(ConsumerConfig.MAX_POLL_RECORDS_CONFIG, "10");
properties.put(ConsumerConfig.CLIENT_RACK_CONFIG, "0");
properties.put(ConsumerConfig.AUTO_OFFSET_RESET_CONFIG, "earliest");
kafkaConsumer = KafkaConsumerClient.createKafkaClient(properties);
receiveMessage("rack02");
}
public static void receiveMessage(String topic) {
TopicPartition topicPartition0 = new TopicPartition(topic, 0);
kafkaConsumer.assign(Arrays.asList(topicPartition0));
while(true) {
// Kafka的消费者⼀次拉取⼀批的数据
ConsumerRecords<String, String> consumerRecords = kafkaConsumer.poll
//System.out.println("开始打印消息!");
// 5.将将记录(record)的offset、key、value都打印出来
for (ConsumerRecord<String, String> consumerRecord : consumerRecords) {
// 主题
String topicName = consumerRecord.topic();
int partition = consumerRecord.partition();
// offset:这条消息处于Kafka分区中的哪个位置
long offset = consumerRecord.offset();
// keyvalue
String key = consumerRecord.key();
String value = consumerRecord.value();
System.out.println(String.format("topic: %s, partition: %s, offs
}
}
}
}
前置背景:
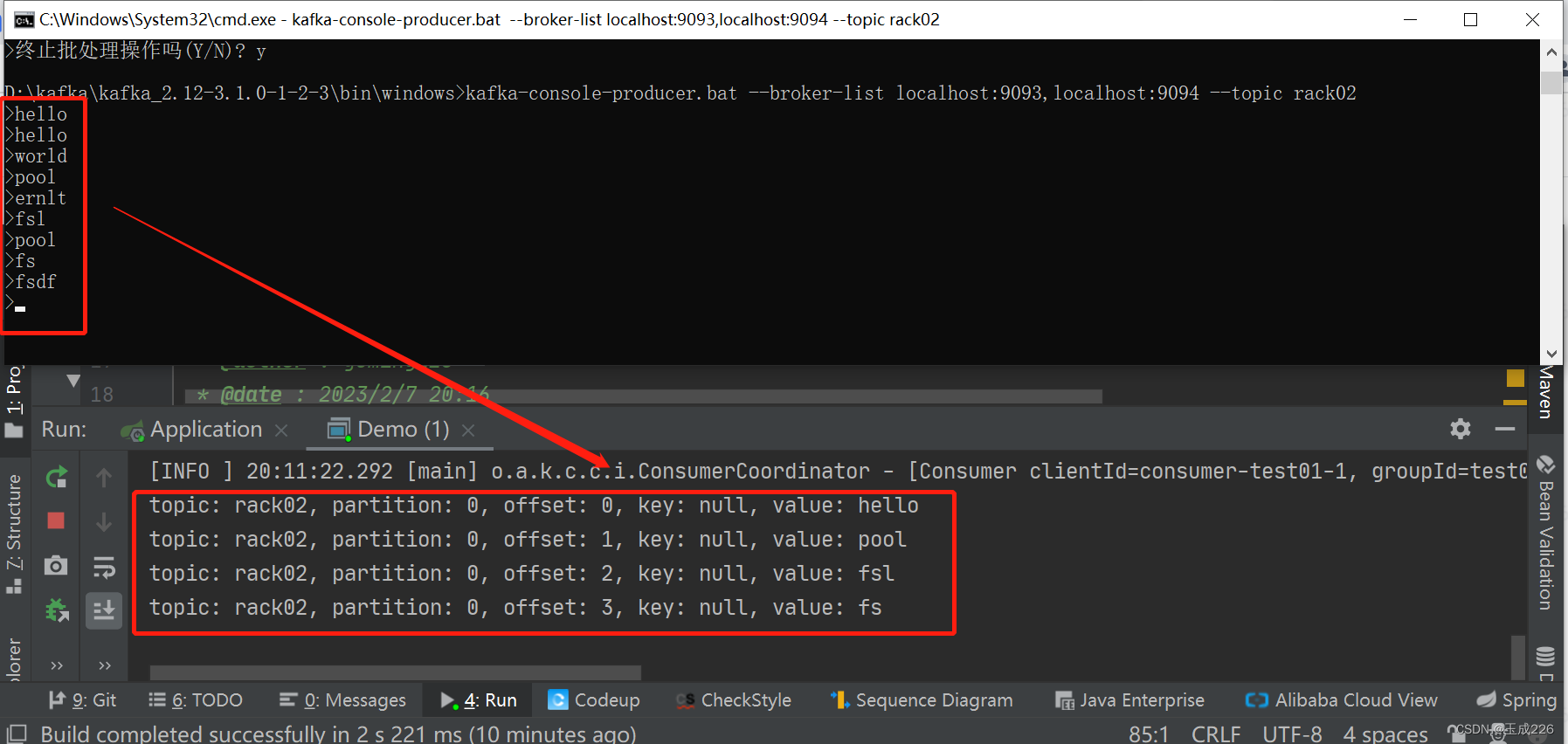
Topic rack02的partition 0分区的副本为broker2(对应的rack为2)和broker1(对应的rack为0),其中broker2为leader(在⾮rack机制下仅能消费到leader中的数据)。
在上述代码中,消费者配置中限制了rack为0,消费的分区为0,因此映射到broker1。通过测试可验证在rack机制下消费者可以消费到folloer副本中的数据,测试如下:
五、机架感知存在的问题
原文地址:https://blog.csdn.net/yuming226/article/details/135470788
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。
如若转载,请注明出处:http://www.7code.cn/show_54098.html
如若内容造成侵权/违法违规/事实不符,请联系代码007邮箱:suwngjj01@126.com进行投诉反馈,一经查实,立即删除!
声明:本站所有文章,如无特殊说明或标注,均为本站原创发布。任何个人或组织,在未征得本站同意时,禁止复制、盗用、采集、发布本站内容到任何网站、书籍等各类媒体平台。如若本站内容侵犯了原著者的合法权益,可联系我们进行处理。





