目录
- Kafka消费者
- 1 配置消费者
-
- bootstrap.servers
- group.id
- key.deserializer
- value.deserializer
- group.instance.id
- fetch.min.bytes=1
- fetch.max.wait.ms
- fetch.max.bytes=57671680 (55 mebibytes)
- max.poll.record=500
- max.partition.fetch.bytes
- session.timeout.ms=45000 (45 seconds)
- heartbeat.interval.ms=3000 (3 seconds)
- max.poll.interval.ms=300000 (5 minutes)
- default.api.timeout.ms=60000 (1 minute)
- request.timeout.ms=40000 (40 seconds)
- auto.offset.reset=latest
- enable.auto.commit=true
- auto.commit.interval.ms=5000 (5 seconds)
- partition.assignment.strategy=class org.apache.kafka.clients.consumer.RangeAssignor,class org.apache.kafka.clients.consumer.CooperativeStickyAssignor
- client.id
- client.rack
- receive.buffer.bytes=65536 (64 KB)
- send.buffer.bytes=131072 (128 KB)
- offsets.retention.minutes=10080(7 days)
- 2 分区再均衡
- 3 固定群组成员
- 4 创建消费者
- 5 轮询
- 6 提交和偏移量
- 7 再均衡监听器
- 8 从特定偏移量位置读取记录
- 9 消费者程序如何退出
- 10 反序列化器
- 11 独立消费者
Kafka消费者
Kafka消费者是指使用Apache Kafka消息系统的客户端应用程序,用于从Kafka集群中读取消息并进行处理。Kafka消费者可以订阅一个或多个主题,并实时地从主题中消费新的消息。消费者可以以不同的方式处理消息,例如将其存储到数据库中、进行实时分析或者将其传递给其他系统。
Kafka消费者通常是分布式的,可以部署在多个节点上以实现高可用性和扩展性。消费者使用Kafka提供的消费者API来管理消息的订阅和消费,以及处理消息的偏移量(offset)等问题。
Kafka消费者的设计使得它们能够处理高吞吐量和大规模的消息流,同时保持低延迟和高可靠性。这使得Kafka成为许多大型互联网公司和数据密集型应用程序的首选消息系统。
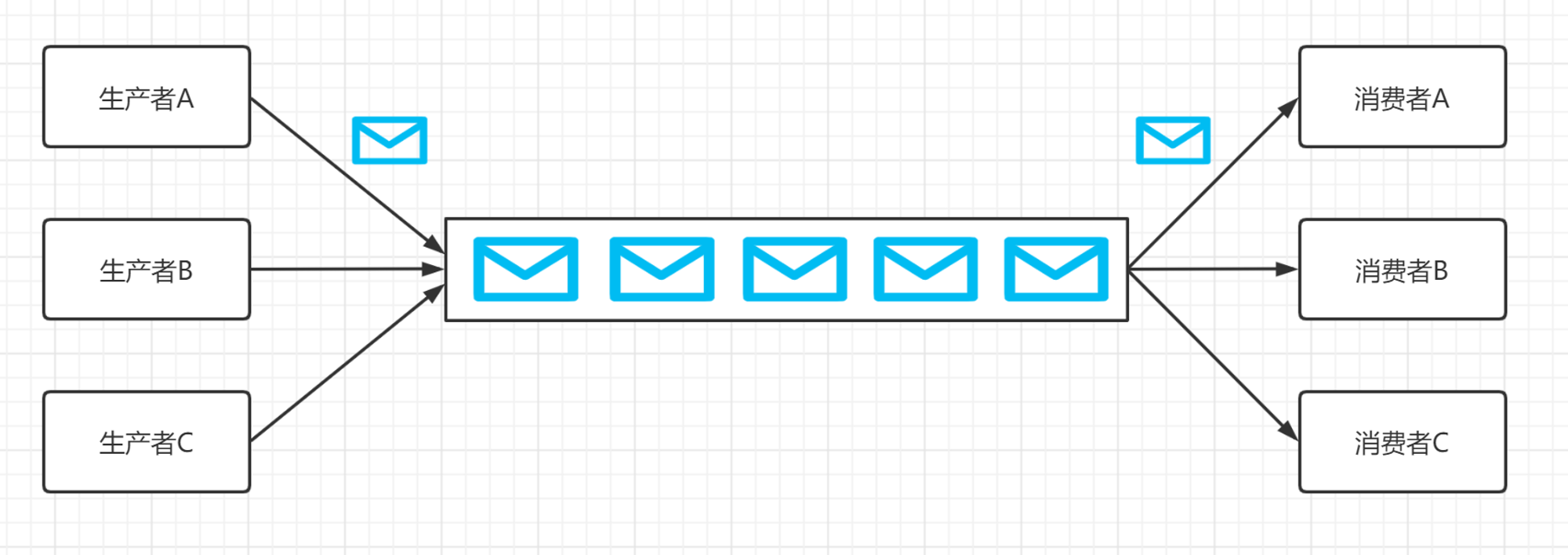
应用程序使用KafkaConsumer向Kafka订阅主图,并从订阅的主题中接收消息。Kafka的消费者从属于消费者群组,一个群组里的消费者订阅的是同一个主题,每个消费者负责读取这个主题的部分消息。

I will add comments for this diagram later …
1 配置消费者
bootstrap.servers
这个参数是常用的KafkaProducer和KafkaConsumer用来连接Kafka集群的入口参数,这个参数对应的值通常是Kafka集群中部分broker的地址,比如:host1:9092,host2:9092,不同的broker地址之间用逗号隔开。
group.id
消费者所属的群组id。非必须,如果未指定,则消费者不属于任何一个群组。
key.deserializer
键的反序列化器,需实现接口org.apache.kafka.common.serialization.Deserializer。
value.deserializer
值的反序列化器,需实现接口org.apache.kafka.common.serialization.Deserializer。
group.instance.id
由最终用户提供的消费者实例的唯一标识符。只允许使用非空字符串。如果设置了,使用者将被视为静态成员,这意味着在使用者组中任何时候都只允许有一个具有此ID的实例。这可以与更大的会话超时结合使用,以避免由于暂时不可用(例如进程重新启动)而导致的组重新平衡。如果未设置,则消费者将作为动态成员加入组,这是传统行为。
fetch.min.bytes=1
服务器应为获取请求返回的最小数据量。如果可用数据不足,则请求将在回答请求之前等待积累那么多数据。1字节的默认设置意味着,只要有那么多字节的数据可用,或者提取请求在等待数据到达时超时,就会立即响应提取请求。将其设置为更大的值将导致服务器等待更大量的数据积累,这可以以一些额外的延迟为代价稍微提高服务器吞吐量。
fetch.max.wait.ms
如果没有足够的数据立即满足fetch.min.bytes给出的要求,则服务器在回答提取请求之前将等待的最长时间。
fetch.max.bytes=57671680 (55 mebibytes)
为每一个请求返回的最大字节数。必须至少为1024。
max.poll.record=500
在对poll()的单个调用中返回的最大记录数。请注意,max.poll.records不会影响底层的获取行为。使用者将缓存每个提取请求中的记录,并从每次轮询中递增地返回这些记录。
max.partition.fetch.bytes
服务器将返回的每个分区的最大数据量。记录由消费者分批提取。如果提取的第一个非空分区中的第一个记录批次大于此限制,则仍将返回该批,以确保使用者能够进行处理。代理接受的最大记录批处理大小是通过message.max.bytes(代理配置)或max.message.bytes(主题配置)定义的。有关限制使用者请求大小的信息,请参阅fetch.max.bytes。
session.timeout.ms=45000 (45 seconds)
使用Kafka的组管理功能时用于检测客户端故障的超时。客户端向代理发送周期性心跳以指示其活跃度。如果代理在此会话超时到期之前没有接收到检测信号,则协调器将从组中删除此客户端并启动重新平衡。请注意,该值必须在代理配置中由group.min.session.timeout.ms和group.max.session.timeout.ms配置的允许范围内。
heartbeat.interval.ms=3000 (3 seconds)
当使用Kafka的组管理功能时,消费者协调员的心跳检测之间的预期时间。心跳用于确保消费者的会话保持活动状态,并在新消费者加入或离开该组时促进重新平衡。该值必须设置为低于session.timeout.ms,但通常应设置为不高于该值的1/3。它可以调整得更低,以控制正常再平衡的预期时间。
max.poll.interval.ms=300000 (5 minutes)
使用使用者组管理时调用poll()之间的最大延迟。这为消费者在获取更多记录之前可以空闲的时间设置了上限。如果在该超时到期之前未调用poll(),则认为使用者失败,并且组将重新平衡,以便将分区重新分配给另一个成员。对于使用非null group.instance.id的使用者,如果达到此超时,则不会立即重新分配分区。相反,使用者将停止发送检测信号,并且在session.timeout.ms到期后将重新分配分区。这反映了已关闭的静态使用者的行为。
因为心跳检测是由消费者的后台线程发送的,有可能消费者主线程发生死锁,但是心跳线程可能正常运行,这样分区的消息永远不能被消费,所以引入了这个超时。
default.api.timeout.ms=60000 (1 minute)
指定客户端API的超时(以毫秒为单位)。此配置用作所有未指定超时参数的客户端API的默认超时。poll()属于显式指定了超时时间。
request.timeout.ms=40000 (40 seconds)
配置控制客户端等待请求响应的最长时间。如果在超时之前没有收到响应,客户端将在必要时重新发送请求,或者在重试次数用完时使请求失败。不建议配置小于默认时间,这样会进一步增加broker的负载。
auto.offset.reset=latest
当Kafka中没有初始偏移量时,或者如果服务器上不再存在当前偏移量(例如,因为该数据已被删除),该怎么办
- earlist:自动将偏移重置为最早偏移
- latest:自动将偏移重置为最新偏移
- none:如果没有为消费者的组找到以前的偏移量,则向消费者抛出异常
- 其他任何配置:向消费者抛出异常。
请注意,将此配置设置为latest时更改分区编号可能会导致消息传递丢失,因为生产者可能会在消费者重置其偏移量之前开始向新添加的分区发送消息(即,还不存在初始偏移量)。
enable.auto.commit=true
如果为true,则消费者的偏移将定期在后台提交。
auto.commit.interval.ms=5000 (5 seconds)
如果enable.auto.commit设置为true,则消费者偏移自动提交到Kafka的频率(以毫秒为单位)。
partition.assignment.strategy=class org.apache.kafka.clients.consumer.RangeAssignor,class org.apache.kafka.clients.consumer.CooperativeStickyAssignor
支持的分区分配策略的类名或类列表,按首选项排序,当使用组管理时,客户端将使用这些策略在消费者实例之间分配分区所有权。可用选项包括:
- 区间:
org.apache.kafka.clients.comer.RangeAssignor:基于主题分配,将同一个主题的若干个连续分区分给同一个消费者。 - 轮询
org.apache.kafka.clients.consumer.RoundRobinAssignor:在所有订阅主题之间以依次循环方式将分区分配给消费者。 - 粘性
org.apache.kafka.clients.csumer.StickyAssigner:保证最大限度地平衡分配,同时再均衡时保留尽可能多的现有分区分配。 - 协作粘性
org.apache.kafka.clients.csumer.CooperativeStickyAssigner:遵循相同的StickyAassigner逻辑,但允许协作再均衡。
默认的分配器是[RangeAssignor,CooperativeStickyAssignor],默认情况下它将使用RangeAssignor,但允许升级到CooperativeStickeyAssigner,只需一次滚动反弹(single rolling bounce)即可从列表中删除RangeAssigner。
通过实现org.apache.kafka.clients.csumer.ConsumerPartitionAssignor接口,可以插入自定义分配策略。
client.id
发出请求时要传递给服务器的id字符串。这样做的目的是通过允许在服务器端请求日志中包含逻辑应用程序名称,能够跟踪ip/端口以外的请求源。
client.rack
此客户端的机架标识符。这可以是指示该客户端物理位置的任何字符串值。它对应于broker配置“broker.rack”。
receive.buffer.bytes=65536 (64 KB)
读取数据时要使用的TCP接收缓冲区(SO_RCVBUF)的大小。如果该值为-1,则将使用操作系统默认值。
send.buffer.bytes=131072 (128 KB)
发送数据时要使用的TCP发送缓冲区(SO_SNDBUF)的大小。如果该值为-1,则将使用操作系统默认值。
offsets.retention.minutes=10080(7 days)
群组提交的没一个分区的最后一个偏移量的保留期限。当
- 消费者组失去所有消费者(即变为空)后,该保留期已经过期,特定分区的已提交偏移将被删除;
- 自上次为分区提交偏移量以来,该保留期已经过去,并且该组不再订阅相应的主题。对于独立使用者(使用手动分配),偏移量将在上次提交后经过此保留期后过期。请注意,当通过删除组请求删除组时,其提交的偏移量也将被删除,而无需额外的保留期;此外,当通过删除主题请求删除主题时,在传播元数据更新时,该主题的任何组的已提交偏移也将被删除,而不会有额外的保留期。
2 分区再均衡
分区从一个消费者转移到另一个消费者的行为称为再均衡。
2.1 再均衡发生的场景
在以下情况会发生再均衡:
- 新的消费者加如群组,它开始读取原本由其他消费者读取的分区
- 消费者被关闭或崩溃,离开群组,原先由它读取的分区将由群组的其它消费者读取
- 主题添加了新的分区,将会导致重新分配分区。
2.2 再均衡的分类
再均衡分为两种类型:
- 主动再均衡
所有消费者停止读取消息,重新加入消费者群组,并重新分配得到分区。 - 协调再均衡(增量再均衡)
通常是指将一个消费者的分区重新分配给另一个消费者。这种增量的方式可能需要几轮迭代,才能达到稳定状态。
2.3 分区分配过程

- 群组的第一个消费者向群组协调器发送加入群组的请求,发生在第一次轮询中
- 协调器将此消费者指定为群组领袖,并发送群组成员列表
- 新的消费者请求加如群组
- 通知群组领袖更新群组成员并重新分配分区
- 分配分区并将结果告知协调器
- 通知群组其他成员分区分配结果
3 固定群组成员
可以给消费者分配一个唯一group.instance.id,使其成为群组固定成员。这样在消费者关闭时,暂时不会退出群组,保留其分区,也就是不会进行分区再均衡,直到超过session.timeout.ms规定的超时时间,才会进行再均衡。期间分区消息暂时不会被读取。
4 创建消费者
Properties props = new Properties();
props.put("bootstrap.servers", "localhost:9092");
props.put("group.id", "test-group");
props.put("key.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
props.put("value.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
KafkaConsumer<String, String> consumer = new KafkaConsumer<>(props);
consumer.subscribe(Arrays.asList("topic1", "topic2"));
5 轮询
while (true) {
ConsumerRecords<String, String> records = consumer.poll(Duration.ofMillis(100));
// 处理拉取到的消息
records.forEach(record -> System.out.printf("offset = %d, key = %s, value = %s%n", record.offset(), record.key(), record.value()));
}
5.1 线程安全
我们既不能在同一个线程中运行多个同属于一个群组的消费者,也不能保证多个线程能够安全地共享一个消费者。所以一个消费者使用一个线程。做好是使用线程池启动多个线程。
6 提交和偏移量
把更新分区当前读取位置的操作叫做偏移量提交。消费者会向一个叫做__consumer_offset的主题发送消息,消息里包含每个分区的偏移量。一旦发生分区再均衡,消费者需要读取之前的偏移量,来继续之前的读取。
如果处理过的偏移量没有及时提交,就可能造成消息重复处理或丢失。
如果使用自动提交或者不指定提交的偏移量,默认会提交poll()返回的最有一个位置+1的偏移量。
6.1 自动提交
自动提交实在poll()方法中实现的。如果在两次提交之间隔之间,默认5秒,消费者崩溃,那么就有可能重复处理这期间的消息
6.2 手动同步提交
加规enable.auto.commit设置为false,然后调用KafkaConsumer.commitSync()同步提交poll()返回的最新偏移量。
public void commitOffset() {
KafkaConsumer<String, String> consumer = create();
consumer.subscribe(Arrays.asList("topic1", "topic2"));
while (true) {
ConsumerRecords<String, String> records = consumer.poll(Duration.ofMillis(100));
for (ConsumerRecord<String, String> record : records) {
System.out.printf("offset = %d, key = %s, value = %s%n", record.offset(), record.key(), record.value());
}
try {
consumer.commitSync();
} catch (CommitFailedException | WakeupException e) {
logger.error("Commit failed.", e);
}
}
}
6.3 异步提交
只管提交请求,不等待broker做出响应。异步提交的缺点时不会自动进行重试,为避免小的偏移量覆盖大的偏移量。
public void commitOffsetAsync() {
KafkaConsumer<String, String> consumer = create();
consumer.subscribe(Arrays.asList("topic1", "topic2"));
while (true) {
ConsumerRecords<String, String> records = consumer.poll(Duration.ofMillis(100));
for (ConsumerRecord<String, String> record : records) {
System.out.printf("offset = %d, key = %s, value = %s%n", record.offset(), record.key(), record.value());
}
consumer.commitAsync(new OffsetCommitCallback() {
@Override
public void onComplete(Map<TopicPartition, OffsetAndMetadata> offsets, Exception exception) {
if (null != exception) {
logger.error("Commit failed for offsets {}", offsets, exception);
}
}
});
}
}
6.4 同步和异步组合提交
public void commitOffsetAsyncAndSync() {
KafkaConsumer<String, String> consumer = create();
consumer.subscribe(Arrays.asList("topic1", "topic2"));
try {
while (true) {
ConsumerRecords<String, String> records = consumer.poll(Duration.ofMillis(100));
for (ConsumerRecord<String, String> record : records) {
System.out.printf("offset = %d, key = %s, value = %s%n", record.offset(), record.key(), record.value());
}
consumer.commitAsync();
}
} catch (WakeupException e) {
logger.error("Unexpected error", e);
consumer.commitSync();
} finally {
consumer.close();
}
}
6.5 提交特定的偏移量
如果poll()返回了大批数据,为了避免再均衡引起的消息重复,可以在批次处理的过程中提交指定的偏移量
public void commitSpecificOffset() {
KafkaConsumer<String, String> consumer = create();
consumer.subscribe(Arrays.asList("topic1", "topic2"));
try {
while (true) {
ConsumerRecords<String, String> records = consumer.poll(Duration.ofMillis(100));
for (ConsumerRecord<String, String> record : records) {
System.out.printf("offset = %d, key = %s, value = %s%n", record.offset(), record.key(), record.value());
}
// 手动提交偏移量
for (TopicPartition partition : records.partitions()) {
long offset = records.records(partition).get(records.records(partition).size() - 1).offset();
consumer.commitSync(Collections.singletonMap(partition, new org.apache.kafka.clients.consumer.OffsetAndMetadata(offset + 1)));
}
}
} catch (WakeupException e) {
// Ignore for shutdown
} finally {
consumer.close();
}
}
7 再均衡监听器
通过再均衡监听器,可以在消费者分配到新分区或就分区被移除是执行一些代码逻辑。
package com.qupeng.demo.kafka.kafkaapache.consumer;
import org.apache.kafka.clients.consumer.ConsumerRebalanceListener;
import org.apache.kafka.clients.consumer.KafkaConsumer;
import org.apache.kafka.common.TopicPartition;
import java.util.Collection;
public class MyRebalanceListener implements ConsumerRebalanceListener {
KafkaConsumer kafkaConsumer;
public MyRebalanceListener(KafkaConsumer kafkaConsumer) {
this.kafkaConsumer = kafkaConsumer;
}
// 消费者放弃对分区的所有权时调用
@Override
public void onPartitionsRevoked(Collection<TopicPartition> partitions) {
}
// 重新分配分区,消费者开始读取消息之前调用
@Override
public void onPartitionsAssigned(Collection<TopicPartition> partitions) {
}
// 使用协作再均衡算法,并且之前不是通过再均衡获得的分区被重新分配给其他消费者时调用
@Override
public void onPartitionsLost(Collection<TopicPartition> partitions) {
ConsumerRebalanceListener.super.onPartitionsLost(partitions);
}
}
public void commitInRebalance() {
KafkaConsumer<String, String> consumer = create();
Map<TopicPartition, OffsetAndMetadata> currentOffsets = new HashMap<>();
try {
consumer.subscribe(Arrays.asList("topic1", "topic2"), new MyRebalanceListener(consumer));
while (true) {
ConsumerRecords<String, String> records = consumer.poll(Duration.ofMillis(100));
for (ConsumerRecord<String, String> record : records) {
System.out.printf("offset = %d, key = %s, value = %s%n", record.offset(), record.key(), record.value());
currentOffsets.put(new TopicPartition(record.topic(), record.partition()),
new OffsetAndMetadata(record.offset() + 1, null));
}
consumer.commitAsync(currentOffsets, null);
}
} catch (WakeupException e) {
logger.error("Unexpected error", e);
} finally {
try {
consumer.commitSync(currentOffsets);
} catch (Exception e) {
throw new RuntimeException(e);
} finally {
consumer.close();
}
}
}
8 从特定偏移量位置读取记录
查找偏移量的用途:
- 对于时间敏感的应用程序在处理速度滞后的情况先可以向前跳过几条消息
public void seekOffsetByTime() {
KafkaConsumer<String, String> consumer = create();
Long oneHourEarlier = Instant.now().atZone(ZoneId.systemDefault()).minusHours(1).toEpochSecond();
Map<TopicPartition, Long> partitionLongMap = consumer.assignment().stream().collect(Collectors.toMap(tp -> tp, tp ->oneHourEarlier));
Map<TopicPartition, OffsetAndTimestamp> offsetMap = consumer.offsetsForTimes(partitionLongMap);
for (Map.Entry<TopicPartition, OffsetAndTimestamp> entry : offsetMap.entrySet()) {
consumer.seek(entry.getKey(), entry.getValue().offset());
}
try {
while (true) {
ConsumerRecords<String, String> records = consumer.poll(Duration.ofMillis(100));
for (ConsumerRecord<String, String> record : records) {
System.out.printf("offset = %d, key = %s, value = %s%n", record.offset(), record.key(), record.value());
}
}
} finally {
consumer.close();
}
}
- 消费者的数据丢失了,可以重置偏移量,回到某个位置进行数据恢复
public void seekSpecificOffset() {
KafkaConsumer<String, String> consumer = create();
// Assign a specific partition and offset
TopicPartition partition = new TopicPartition("your-topic", 0);
consumer.assign(Collections.singleton(partition));
consumer.seek(partition, 100);
try {
while (true) {
ConsumerRecords<String, String> records = consumer.poll(Duration.ofMillis(100));
for (ConsumerRecord<String, String> record : records) {
System.out.printf("offset = %d, key = %s, value = %s%n", record.offset(), record.key(), record.value());
}
}
} finally {
consumer.close();
}
}
9 消费者程序如何退出
关闭一个消费者,有两种办法:
- 如果要立刻关闭消费之,可以在另一个线程中调用consumer.close(),它是consumer中唯一一个线程安全的方法。
- 如果轮询等待时间足够短,或者不介意多等待一段退出时间,可是在另一个线程中修改轮询标记的方法退出轮询。
private AtomicBoolean exitFlag = new AtomicBoolean(false);
public void consumeAndExit() {
KafkaConsumer<String, String> consumer = create();
addShutdownHook(consumer, Thread.currentThread());
consumer.subscribe(Arrays.asList("topic1", "topic2"));
try {
while (!exitFlag.get()) {
ConsumerRecords<String, String> records = consumer.poll(Duration.ofMillis(10000));
for (ConsumerRecord<String, String> record : records) {
System.out.printf("offset = %d, key = %s, value = %s%n", record.offset(), record.key(), record.value());
}
consumer.commitAsync();
}
consumer.close();
} catch (WakeupException e) {
consumer.commitSync();
} finally {
consumer.close();
}
}
public void setExitFlag() {
Runtime.getRuntime().addShutdownHook(new Thread() {
@Override
public void run() {
exitFlag.compareAndSet(false, true);
}
});
}
public void addShutdownHook(Consumer consumer, Thread mainThread) {
Runtime.getRuntime().addShutdownHook(new Thread() {
@Override
public void run() {
consumer.wakeup();
try {
mainThread.join();
} catch (InterruptedException e) {
logger.error("", e);
}
}
});
}
在Java程序中可以通过添加关闭钩子,实现在程序退出时关闭资源、平滑退出的功能。
使用Runtime.addShutdownHook(Thread hook)方法,可以注册一个JVM关闭的钩子,这个钩子可以在以下几种场景被调用:
- 程序正常退出
- 使用System.exit()
- 终端使用Ctrl+C触发的中断
- 系统关闭
- 使用Kill pid命令干掉进程
10 反序列化器
消费者使用反序列化器把字节数组转换为Java对象。反序列化器和序列化器必须匹配,不然会出错。
10.1 自定义反序列化器
package com.qupeng.demo.kafka.kafkaapache.consumer;
import com.qupeng.demo.kafka.kafkaapache.producer.Product;
import org.apache.kafka.common.serialization.Deserializer;
import java.nio.ByteBuffer;
import java.nio.charset.StandardCharsets;
public class CustomizedDeserializer implements Deserializer<Product> {
@Override
public Product deserialize(String topic, byte[] data) {
ByteBuffer byteBuffer = ByteBuffer.wrap(data);
int id = byteBuffer.getInt();
int nameSize = byteBuffer.getInt();
byte[] nameBytes = new byte[nameSize];
byteBuffer.get(nameBytes);
String name = new String(nameBytes, StandardCharsets.UTF_8);
return new Product(id, name);
}
}
10.2 Avro反序列化器
package com.qupeng.demo.kafka.kafkaapache.consumer;
import com.qupeng.demo.kafka.kafkaapache.producer.Product;
import org.apache.kafka.clients.consumer.ConsumerRecords;
import org.apache.kafka.clients.consumer.KafkaConsumer;
import java.time.Duration;
import java.util.Arrays;
import java.util.Properties;
public class AvroConsumer {
public KafkaConsumer create() {
Properties props = new Properties();
props.put("bootstrap.servers", "localhost:9092");
props.put("group.id", "test-group");
props.put("key.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
props.put("value.deserializer", "io.confluent.kafka.serializers.KafkaAvroDeserializer");
props.put("schema.registry.url", "localhost:8081");
return new KafkaConsumer<>(props);
}
public void consume() {
KafkaConsumer<String, Product> consumer = create();
consumer.subscribe(Arrays.asList("topic1", "topic2"));
while (true) {
ConsumerRecords<String, Product> records = consumer.poll(Duration.ofMillis(100));
// 处理拉取到的消息
records.forEach(record -> System.out.printf("offset = %d, key = %s, value = %s%n", record.offset(), record.key(), record.value().getName()));
}
}
}
11 独立消费者
需要一个消费者读取主题的所有分区或某个分区时,只需要把主题或分区分配给这个消费者,就不需要消费者群组和再均衡了。
package com.qupeng.demo.kafka.kafkaapache.consumer;
import org.apache.kafka.clients.consumer.ConsumerRecords;
import org.apache.kafka.clients.consumer.KafkaConsumer;
import org.apache.kafka.common.PartitionInfo;
import org.apache.kafka.common.TopicPartition;
import java.time.Duration;
import java.util.ArrayList;
import java.util.List;
import java.util.Properties;
public class IndependentConsumer {
public KafkaConsumer create() {
Properties props = new Properties();
props.put("bootstrap.servers", "localhost:9092");
props.put("group.id", "test-group");
props.put("key.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
props.put("value.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
return new KafkaConsumer<>(props);
}
public void consume() {
KafkaConsumer<String, String> consumer = create();
List<PartitionInfo> partitionInfos = consumer.partitionsFor("Topic");
if (null != partitionInfos) {
List<TopicPartition> topicPartitions = new ArrayList<>();
for (PartitionInfo partitionInfo : partitionInfos) {
topicPartitions.add(new TopicPartition(partitionInfo.topic(), partitionInfo.partition()));
}
consumer.assign(topicPartitions);
while (true) {
ConsumerRecords<String, String> records = consumer.poll(Duration.ofMillis(100));
records.forEach(record -> System.out.printf("offset = %d, key = %s, value = %s%n", record.offset(), record.key(), record.value()));
consumer.commitSync();
}
}
}
}
注意独立消费者在增加了新的分区之后,并不会收到通知,需要通过API重新获取分区列表。
原文地址:https://blog.csdn.net/yunyun1886358/article/details/135437744
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。
如若转载,请注明出处:http://www.7code.cn/show_54114.html
如若内容造成侵权/违法违规/事实不符,请联系代码007邮箱:suwngjj01@126.com进行投诉反馈,一经查实,立即删除!