本文介绍: 在web服务器中,高可用是指服务器可以正常访问的时间,衡量的标准是在多长时间内可以提供正常服务(99.9%、99.99%、99.999%等等)。但是在Redis语境中,高可用的含义似乎要宽泛一些,除了保证提供正常服务(如主从分离、快速容灾技术),还需要考虑数据容量的扩展数据安全不会丢失等。在Redis中,实现高可用的技术主要包括持久化、主从复制、哨兵和 Cluster集群,下面分别说明它们的作用,以及解决了什么样的问题。
一、redis 高可用概述
在web服务器中,高可用是指服务器可以正常访问的时间,衡量的标准是在多长时间内可以提供正常服务(99.9%、99.99%、99.999%等等)。
但是在Redis语境中,高可用的含义似乎要宽泛一些,除了保证提供正常服务(如主从分离、快速容灾技术),还需要考虑数据容量的扩展、数据安全不会丢失等。
在Redis中,实现高可用的技术主要包括持久化、主从复制、哨兵和 Cluster集群,下面分别说明它们的作用,以及解决了什么样的问题。
●持久化:持久化是最简单的高可用方法(有时甚至不被归为高可用的手段),主要作用是数据备份,即将数据存储在硬盘,保证数据不会因进程退出而丢失。
●主从复制:主从复制是高可用Redis的基础,哨兵和集群都是在主从复制基础上实现高可用的。主从复制主要实现了数据的多机备份,以及对于读操作的负载均衡和简单的故障恢复。缺陷:故障恢复无法自动化;写操作无法负载均衡;存储能力受到单机的限制。
●哨兵:在主从复制的基础上,哨兵实现了自动化的故障恢复。缺陷:写操作无法负载均衡;存储能力受到单机的限制。
二、redis 持久化
1、RDB 持久化
1.1RDB 持久化触发条件
①手动触发
②自动触发
1.2执行流程

13. 启动时加载
2、AOF 持久化
2.1开启AOF
2.2执行流程

2.3.启动时加载
3、 RDB和AOF的优缺点
●RDB持久化
●AOF持久化
三、redis 性能管理
1、查看Redis内存使用

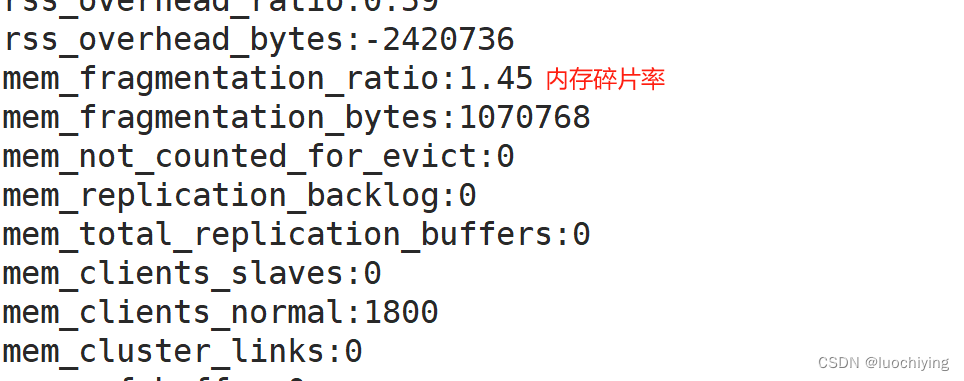
2、内存碎片如何产生的
3、跟踪内存碎片率
4、解决碎片率大的方法
5、内存使用率
6、内存数据淘汰策略
四、redis优化
五、redis的三大缓存问题
1、三大问题
2、解决方法
六、如何保证 MySQL 和 redis 的数据一致性?
声明:本站所有文章,如无特殊说明或标注,均为本站原创发布。任何个人或组织,在未征得本站同意时,禁止复制、盗用、采集、发布本站内容到任何网站、书籍等各类媒体平台。如若本站内容侵犯了原著者的合法权益,可联系我们进行处理。






