本文介绍: 如何搭建网络,这在深度学习中非常重要。简单来讲,我们是要实现一个类,这个类中有属性和方法,能够进行计算。一般来讲,使用PyTorch创建神经网络需要三步:继承基类:nn.Module定义层属性实现前向传播方法
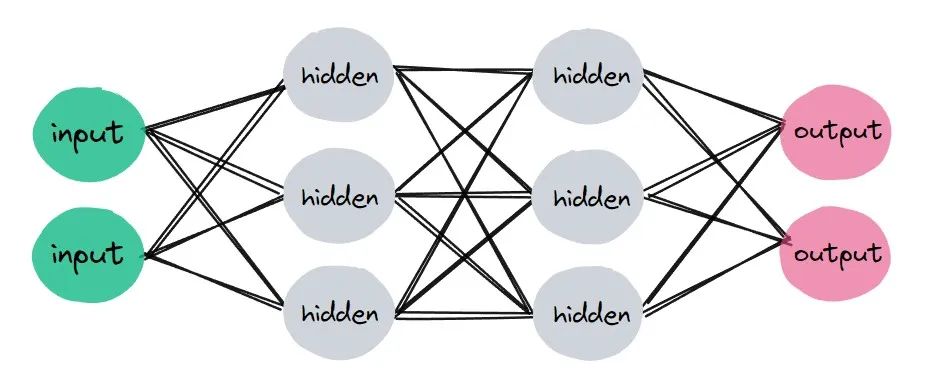
如何搭建网络,这在深度学习中非常重要。简单来讲,我们是要实现一个类,这个类中有属性和方法,能够进行计算。
一般来讲,使用PyTorch创建神经网络需要三步:
如果你对于python面向对象编程非常熟练,那么这里也就非常简单,就是定义一些属性,实现一些方法。
开始建立一个网络,就像这样:
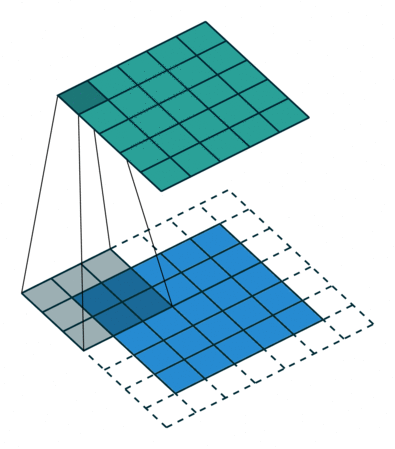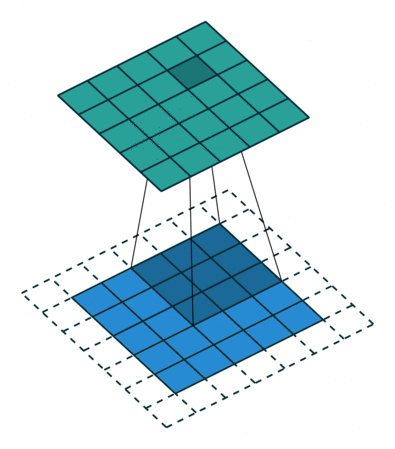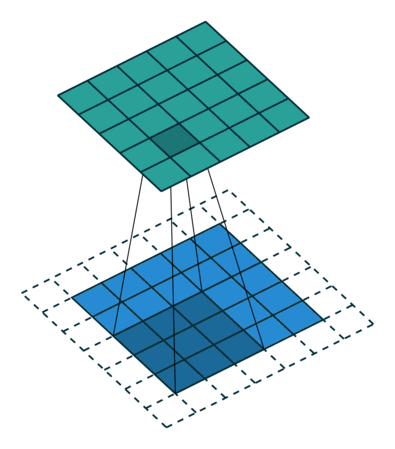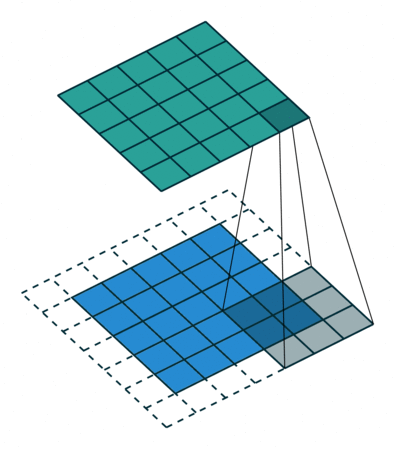
声明:本站所有文章,如无特殊说明或标注,均为本站原创发布。任何个人或组织,在未征得本站同意时,禁止复制、盗用、采集、发布本站内容到任何网站、书籍等各类媒体平台。如若本站内容侵犯了原著者的合法权益,可联系我们进行处理。