本文介绍: 软件工程概论—内聚性和耦合性(知识点)
目录
一.耦合性


1.内容耦合
2.公共耦合


4.控制耦合
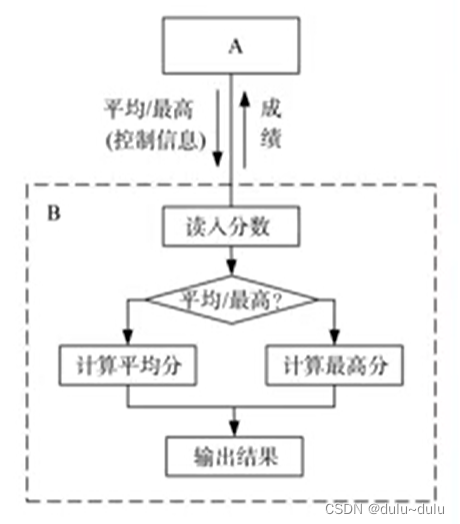
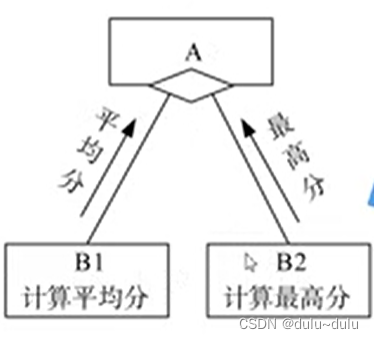
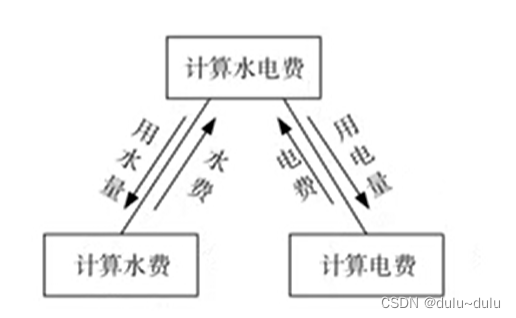
5.标记耦合(特征耦合)

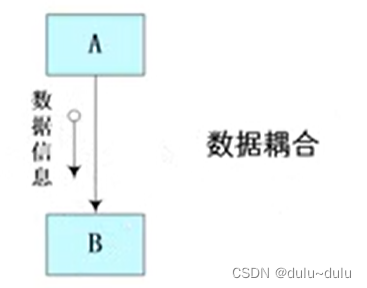
6.数据耦合
7.非直接耦合
二.内聚性

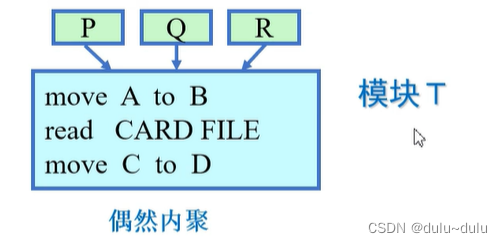
1.偶然内聚
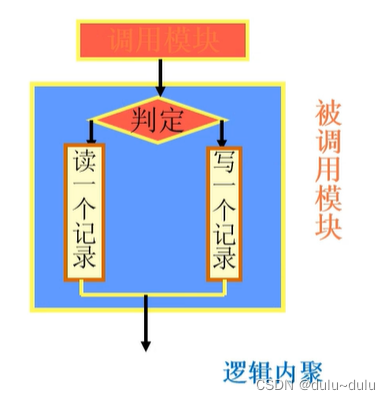
2.逻辑内聚
3.时间内聚

4.过程内聚

5.通信内聚
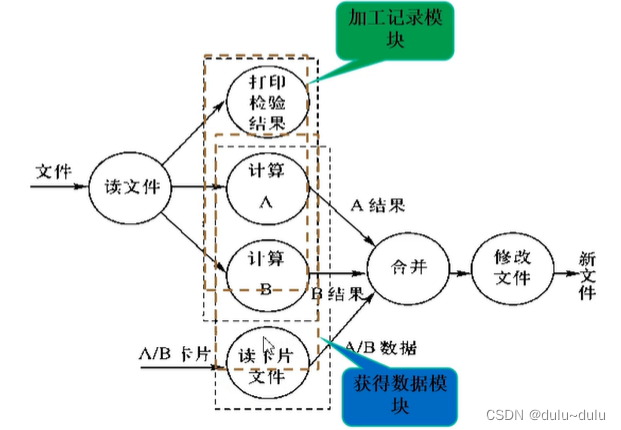
6.顺序内聚

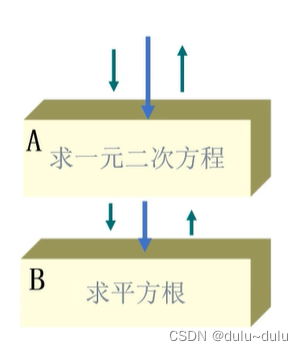
7.功能内聚
声明:本站所有文章,如无特殊说明或标注,均为本站原创发布。任何个人或组织,在未征得本站同意时,禁止复制、盗用、采集、发布本站内容到任何网站、书籍等各类媒体平台。如若本站内容侵犯了原著者的合法权益,可联系我们进行处理。
目录