本文介绍: 【※※※总结】:信息熵是用来衡量 给出的数据集中 数据的纯度的信息熵越小,数据就越纯。通常用在机器学习分类的情况下3.2 信息熵公式。
C2-4.2.2 决策树-纯度+信息熵+信息增益
1、首先了解他的应用背景——决策树

其实说白了,就是一个二叉树
2、纯度
我们举一个买黄金的例子吧!黄金有999 和 9999 。 他们是有区别的,代表着黄金的纯度(相对杂质而言),那在决策树中——我们也引入了“纯度”这一概念。如果结果集中,全是这一类的,那么我们说“vary pure”。如果结果集中有6个,但是3个是一个类别,那么我们说”not pure”,把除这三个外的东西叫做“杂质”
2.1 纯度简述
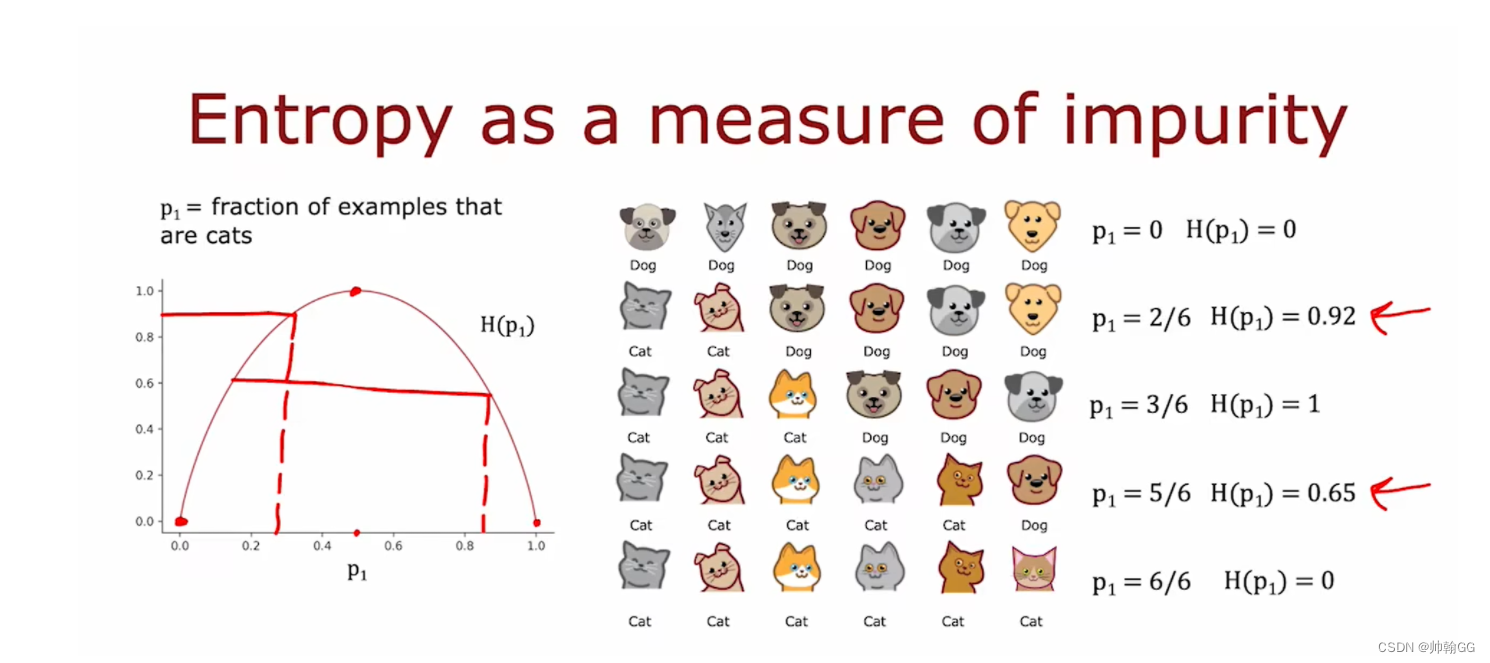
3、信息熵(entropy )
那买黄金,有专业的机器来判别我们的黄金的纯度,那在决策树中的结果集中,如何判别纯度呢 / 判别纯度的标准??——这就引出了**“信息熵”** 的定义。
3.1 信息熵的定义
In Machine Learning, entropy ※※measures the level of disorder or uncertainty in a given dataset or system. It is a metric that quantifies the amount of information in a dataset, and it is commonly used to evaluate the quality of a model and its ability to make accurate predictions.
3.2 信息熵公式
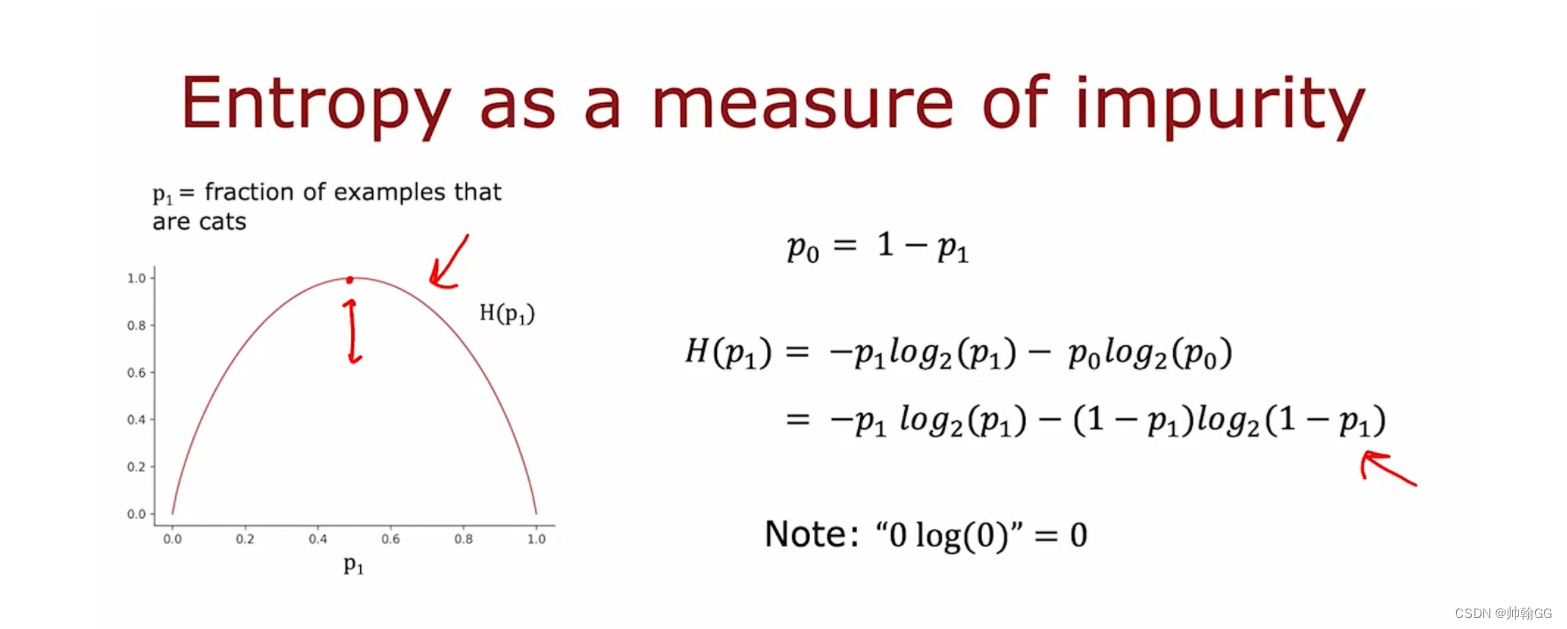
4、信息增益(Information Gain)
4.1、信息增益概念:

4.2 信息增益公式:

声明:本站所有文章,如无特殊说明或标注,均为本站原创发布。任何个人或组织,在未征得本站同意时,禁止复制、盗用、采集、发布本站内容到任何网站、书籍等各类媒体平台。如若本站内容侵犯了原著者的合法权益,可联系我们进行处理。





