本文介绍: 大型语言模型与知识图谱的完美结合:从LLMs到RAG,探索知识图谱构建的全新篇章
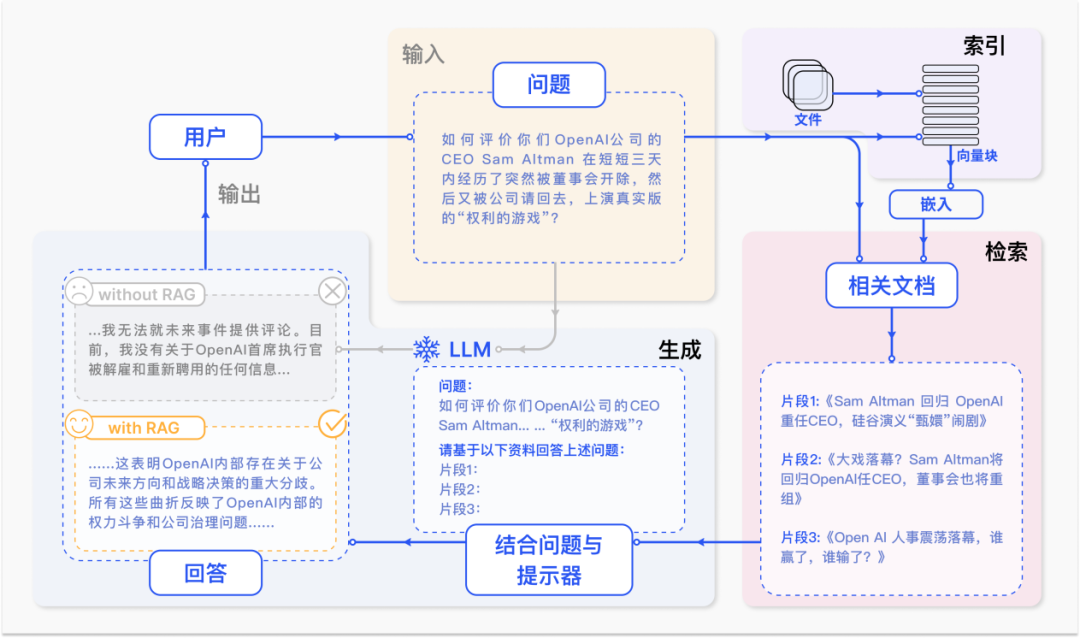
最近,使用大型语言模型(LLMs)和知识图谱(KG)开发 RAG(Retrieval Augmented Generation)流程引起了很大的关注。在这篇文章中,我将使用 LlamaIndex 和 NebulaGraph 来构建一个关于费城费利斯队(Philadelphia Phillies)的 RAG 流程。
我们用的是开源的 NebulaGraph 来完成这次的知识图谱。用来查询费城费利斯队的信息。我们将使用费城费利斯队的维基百科页面作为我们的其中一个信息源数据源,另一个是 YouTube 下载的一段视频。
我们的高级架构图如下:
文章转载:https://www.zhihu.com/question/299907037/answer/3340394547

对于那些已经熟悉知识图和 NebulaGraph 的人,请跳到 “详细实现” 部分。对于 NebulaGraph 的新手,请继续阅读。
1.知识图谱(KG)
1.1主要组件
声明:本站所有文章,如无特殊说明或标注,均为本站原创发布。任何个人或组织,在未征得本站同意时,禁止复制、盗用、采集、发布本站内容到任何网站、书籍等各类媒体平台。如若本站内容侵犯了原著者的合法权益,可联系我们进行处理。