本文介绍: 一致性哈希算法在1997年由[麻省理工学院](https://baike.baidu.com/item/麻省理工学院/117999)提出,是一种特殊的哈希算法,目的是解决分布式缓存的问题。 在移除或者添加一个服务器时,能够尽可能小地改变已存在的服务请求与处理请求服务器之间的映射关系。一致性哈希解决了简单哈希算法在分布式[哈希表](https://baike.baidu.com/item/哈希表/5981869)( Distributed Hash Table,DHT) 中存在的动态伸缩等问题。
Hash算法
哈希算法将任意长度的二进制值映射为较短的固定长度的二进制值,这个小的二进制值称为哈希值。哈希值是一段数据唯一且极其紧凑的数值表示形式。
Hash算法在安全加密领域MD5、SHA等加密算法,数据存储和查找的Hash表等方面均有应用。Hash表的数据查询效率极高,时间复杂度达到O(1)。Hash表通常使用数组下标与数据进行对应的方式进行存储,查找时,通过数据计算出下标(通常是取模)得到下标,然后通过下标直接访问数据。当然,当数组空间有限时,不同的数据计算出相同的下标的情况必然发生,这种情况叫Hash冲突,而解决Hash冲突的常用方法有开放寻址法、拉链法(常用)。
如下图,1和6这两个数据通过对5取模,得到的下标都是1,发生了Hash冲突。
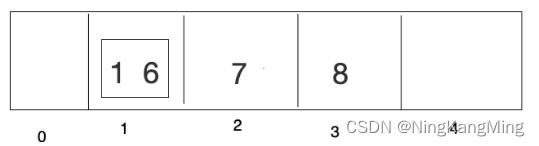
开放寻址法:1放进去了,6再来的时候,向前或者向后找空闲位置存放。但这种方法存在明显缺陷,即数组长度是一定的,当数组被用完时,发生Hash冲突后将无法解决。
拉链法:当发生Hash冲突时,以链表将冲突数据串起来。即数组元素存的一个链表,而不是一个简单数值了。发生Hash冲突时,只需要把新数据放到链表头即可。查找数据时,遍历链表。当然,当链表过长会影响查询性能。此时可以把链表转自平衡二叉查找树(如红黑树,Java8的ConcurrentHashMap 就是使用数组 + 链表 + 红黑树来实现的),这样一来,查询性能将从O(n)降低到 O(log(n))。
Hash算法应用场景
普通Hash算法存在的问题
一致性Hash算法
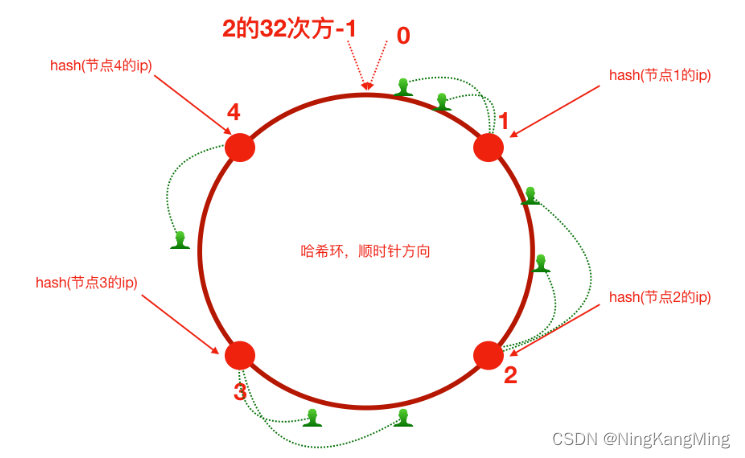
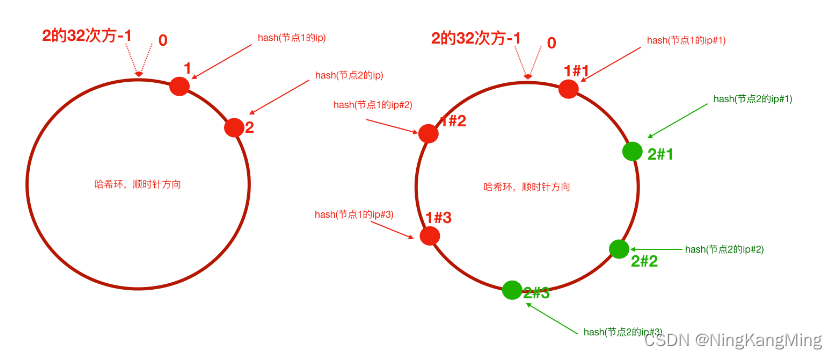
nginx配置一致性Hash负载均衡策略
声明:本站所有文章,如无特殊说明或标注,均为本站原创发布。任何个人或组织,在未征得本站同意时,禁止复制、盗用、采集、发布本站内容到任何网站、书籍等各类媒体平台。如若本站内容侵犯了原著者的合法权益,可联系我们进行处理。



