本文介绍: 在现实生活中,很多人的资料是不愿意公布在互联网上的,但是我们又要使用人工智能的能力帮我们处理文件、做决策、执行命令那怎么办呢?于是我们构建自己或公司的私人GPT变得非常重要。
创作不易,请大家多鼓励支持。
在现实生活中,很多人的资料是不愿意公布在互联网上的,但是我们又要使用人工智能的能力帮我们处理文件、做决策、执行命令那怎么办呢?于是我们构建自己或公司的私人GPT变得非常重要。

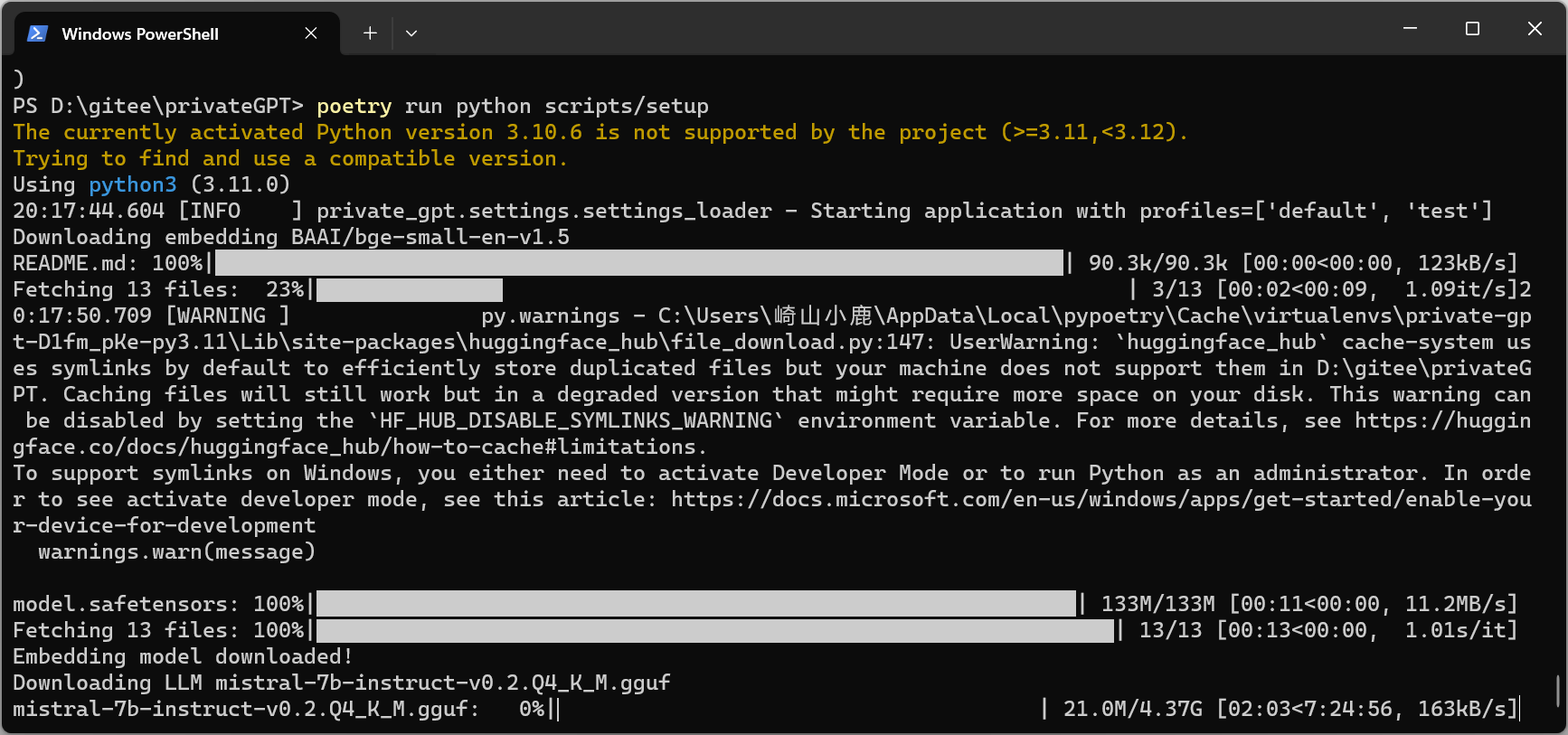
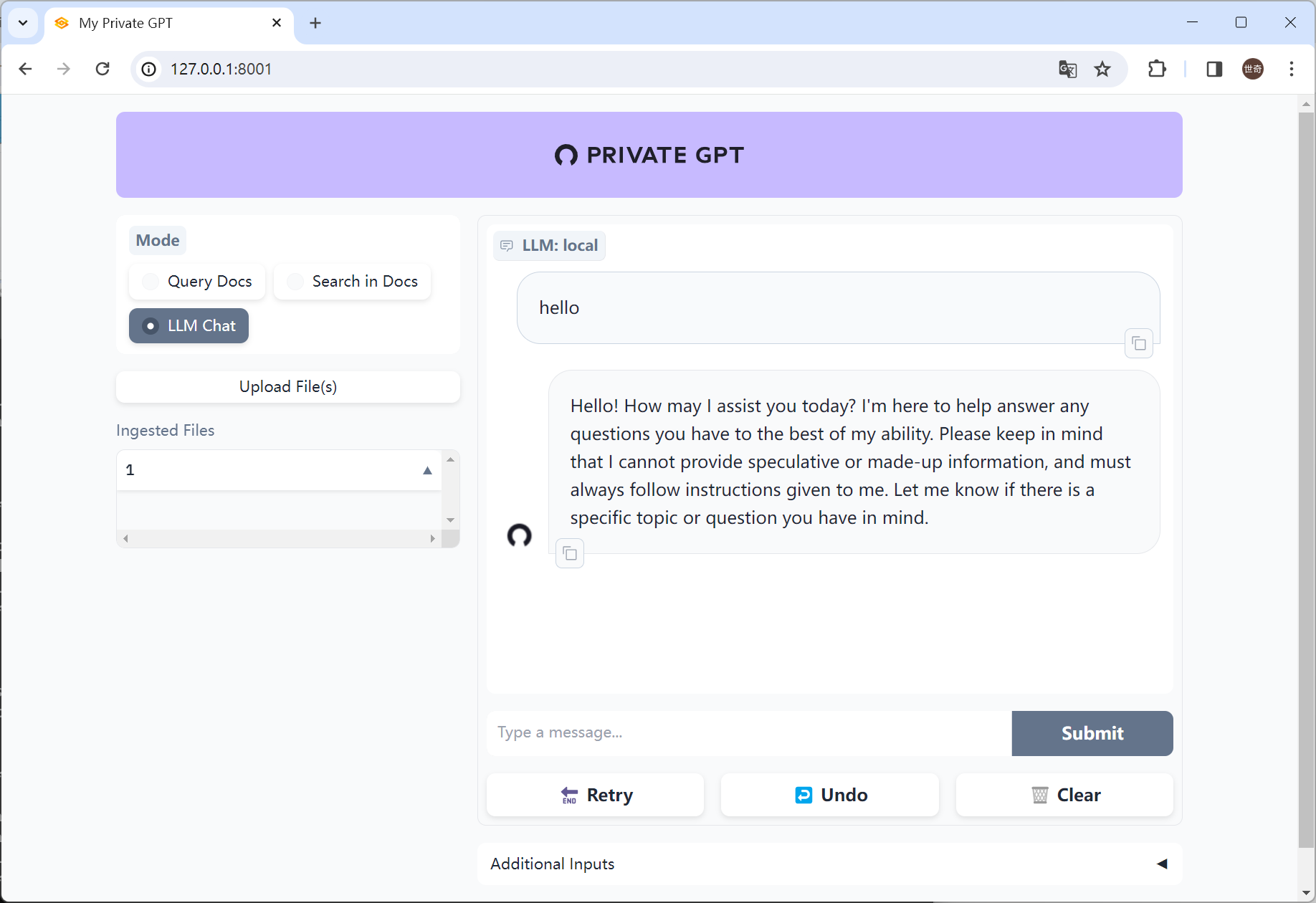
一、本地部署PrivateGPT
快速本地安装步骤:
1. 克隆存储库:
git clone




声明:本站所有文章,如无特殊说明或标注,均为本站原创发布。任何个人或组织,在未征得本站同意时,禁止复制、盗用、采集、发布本站内容到任何网站、书籍等各类媒体平台。如若本站内容侵犯了原著者的合法权益,可联系我们进行处理。