本文介绍: 文献阅读1
A Hierarchical Representation Network for Accurate and Detailed Face Reconstruction from In-The-Wild Images
会议/期刊:CVPR 2023;阿里达摩院;Biwen Lei
概述:这是一篇单张图片三维人脸重建的论文,这篇论文的主要目标是在三维人脸重建时尽量还原细节信息。
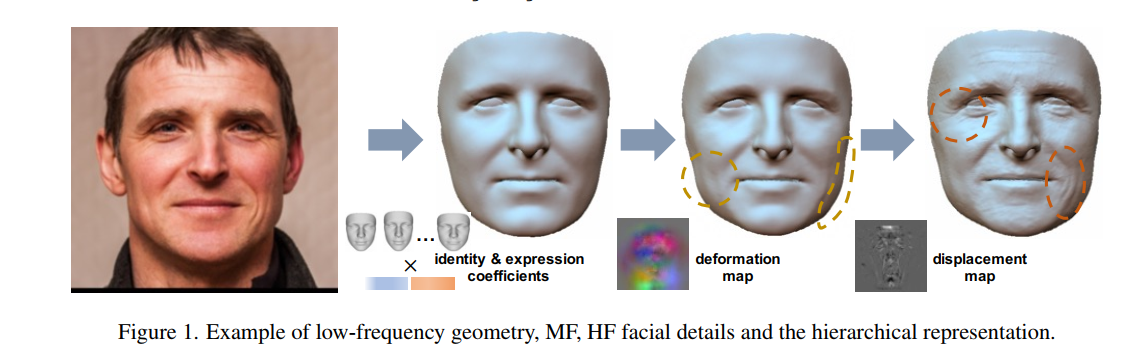
如上图所示,他们将人脸重建过程分为三个部分,分别用低频、中频、高频信号来区分。低频表示基本的形状,也就是用3dmm生成的部分;中频表示顶点尺度的几何变形,用deformation map (64*64*3)来记录;高频表示像素尺度的位移,也就是一个displacement map(normal map)(256*256),在渲染的时候根据像素进行高度的插值。
我觉得很神奇的一点是,他的中频信号尽管只用于每个顶点的变形,但他仍然是用贴图的方式来存储,实际上如果deformation map的分辨率大一些,是和displacement map有类似作用的。是否真的有必要强行拆分成两个部分呢?
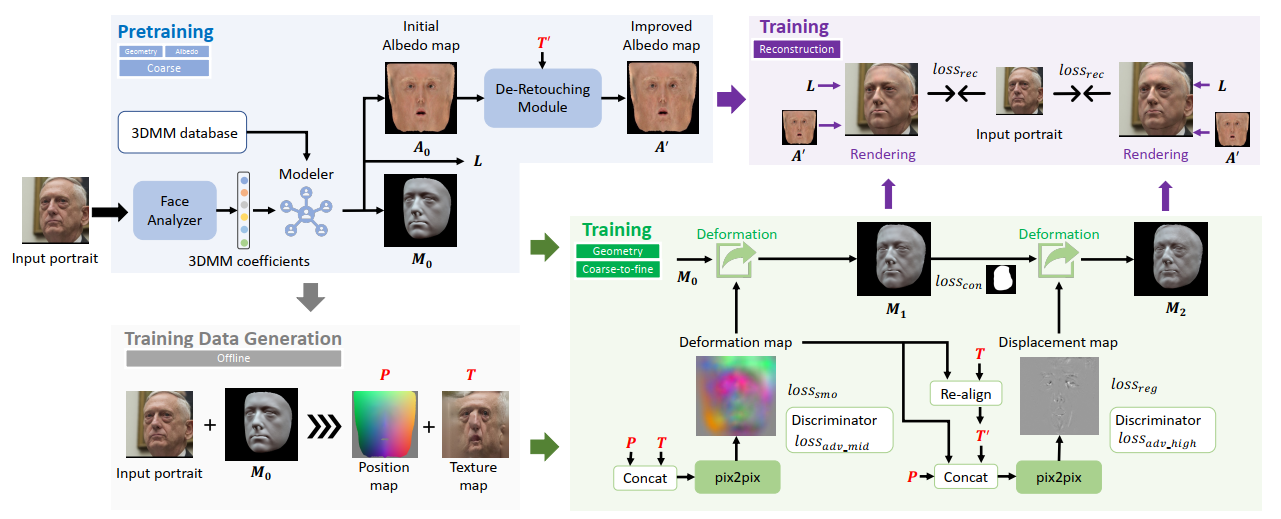
下图展示了他们的方法流程图:
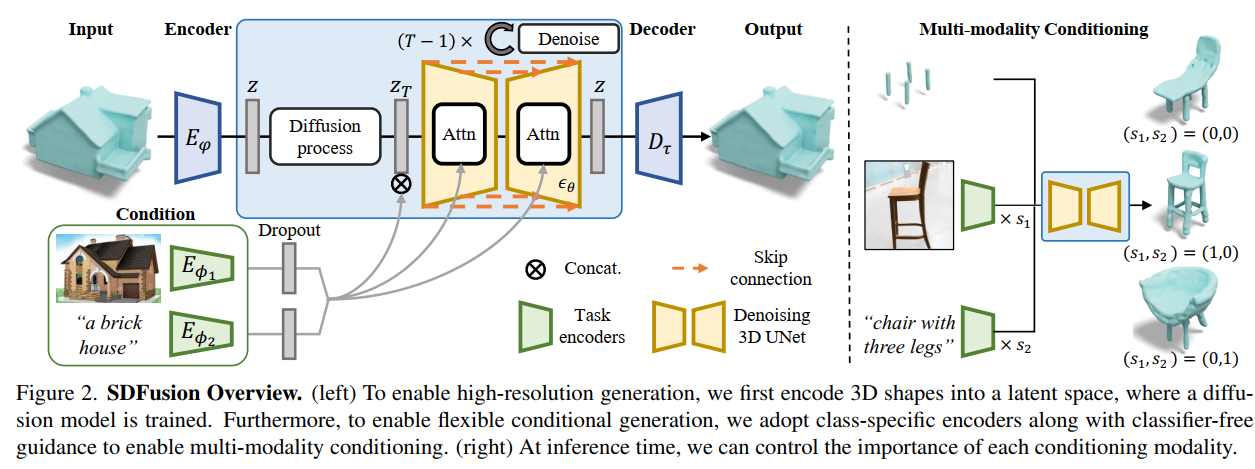
Sdfusion: Multimodal 3d shape completion, reconstruction, and generation
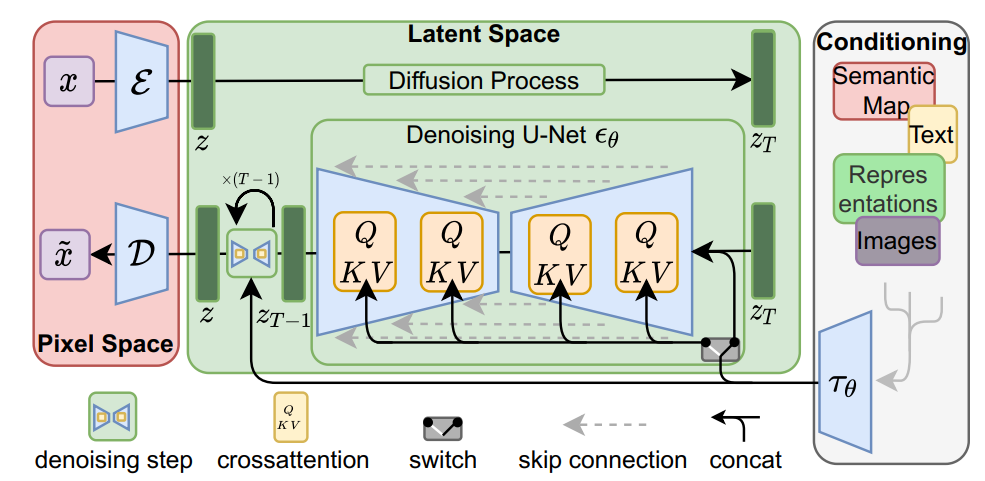
High-Resolution Image Synthesis with Latent Diffusion Models
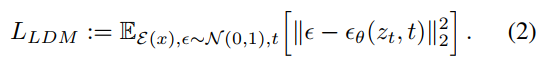
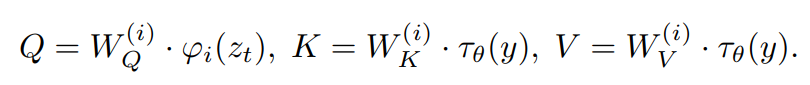
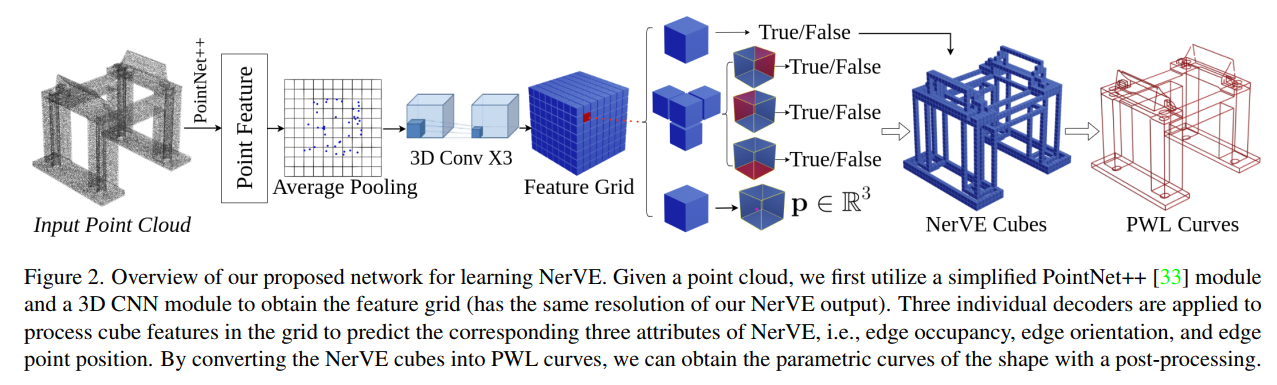
NerVE: Neural Volumetric Edges for Parametric Curve Extraction from Point Cloud
Denoising Diffusion Probabilistic Models for Robust Image Super-Resolution in the Wild
声明:本站所有文章,如无特殊说明或标注,均为本站原创发布。任何个人或组织,在未征得本站同意时,禁止复制、盗用、采集、发布本站内容到任何网站、书籍等各类媒体平台。如若本站内容侵犯了原著者的合法权益,可联系我们进行处理。