本文介绍: 详细介绍了桶排序,冒泡排序以及快速排序,std::sort
前言
今天学习了一些简单的排序算法,其实在我们平时解决问题中经常用到,今天正好一起看了看,记录一下。如果对你也有帮助,我很开心~
一、桶排序(Bucket Sort)
桶排序是一种排序算法,它将数组划分为一些有序的桶,然后每个桶再分别排序。最后,将所有的桶合并起来,得到一个有序的数组。桶排序的核心思想是将数据分散到不同的桶中,每个桶内部进行排序,最后将所有桶的数据合并。
小唐有话说:我感觉桶排序也是拿空间换时间的感觉,和哈希表有点像有没有!!!但是他们的主要的区别在于桶排序是一种排序算法,重于对元素的排序,而哈希表是一种数据结构,用于快速查找和插入
对于此处的例子,时间复杂度: O(n + 10 * log(10)),其中10是是因为分了10个桶,分桶的过程时间复杂度是 O(n),std::sort是一种改进的快速排序算法,它的平均时间复杂度是O(n log n)
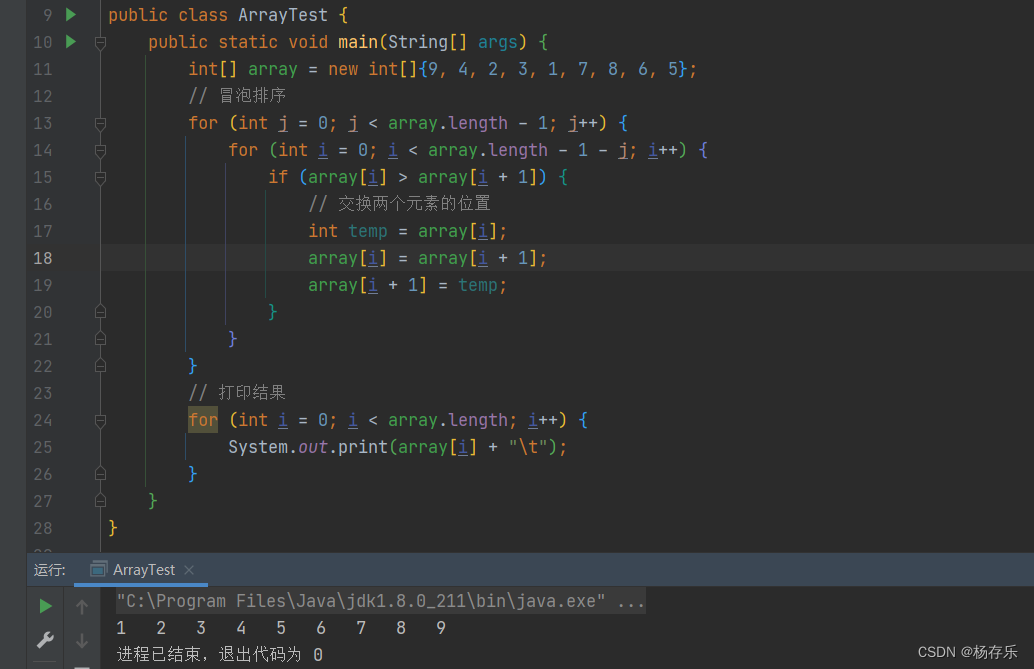
二、冒泡排序(Bubble Sort)
冒泡排序是一种简单的排序算法,其基本思想是通过不断地交换相邻元素,将较大的元素逐渐移到右侧(或较小的元素逐渐移到左侧),从而达到排序的目的。
小唐有话说:不知道大家有没有印象!反正小唐印象超级无敌深刻,大一学C语音的时候就对它印象深刻,到现在仍然记忆尤新,当初看了好多好多遍才弄懂的算法,现在看简直简单的不能再简单,这就是轻舟已过万重山叭!
二、快速排序(Quick Sort)
总结
声明:本站所有文章,如无特殊说明或标注,均为本站原创发布。任何个人或组织,在未征得本站同意时,禁止复制、盗用、采集、发布本站内容到任何网站、书籍等各类媒体平台。如若本站内容侵犯了原著者的合法权益,可联系我们进行处理。