本文介绍: LLMs改变了自然语言处理领域,该领域以前依赖于明确的基于规则的系统和更简单的统计方法。LLMs引入了新的深度学习驱动方法,导致了理解、生成和翻译人类语言的进步。
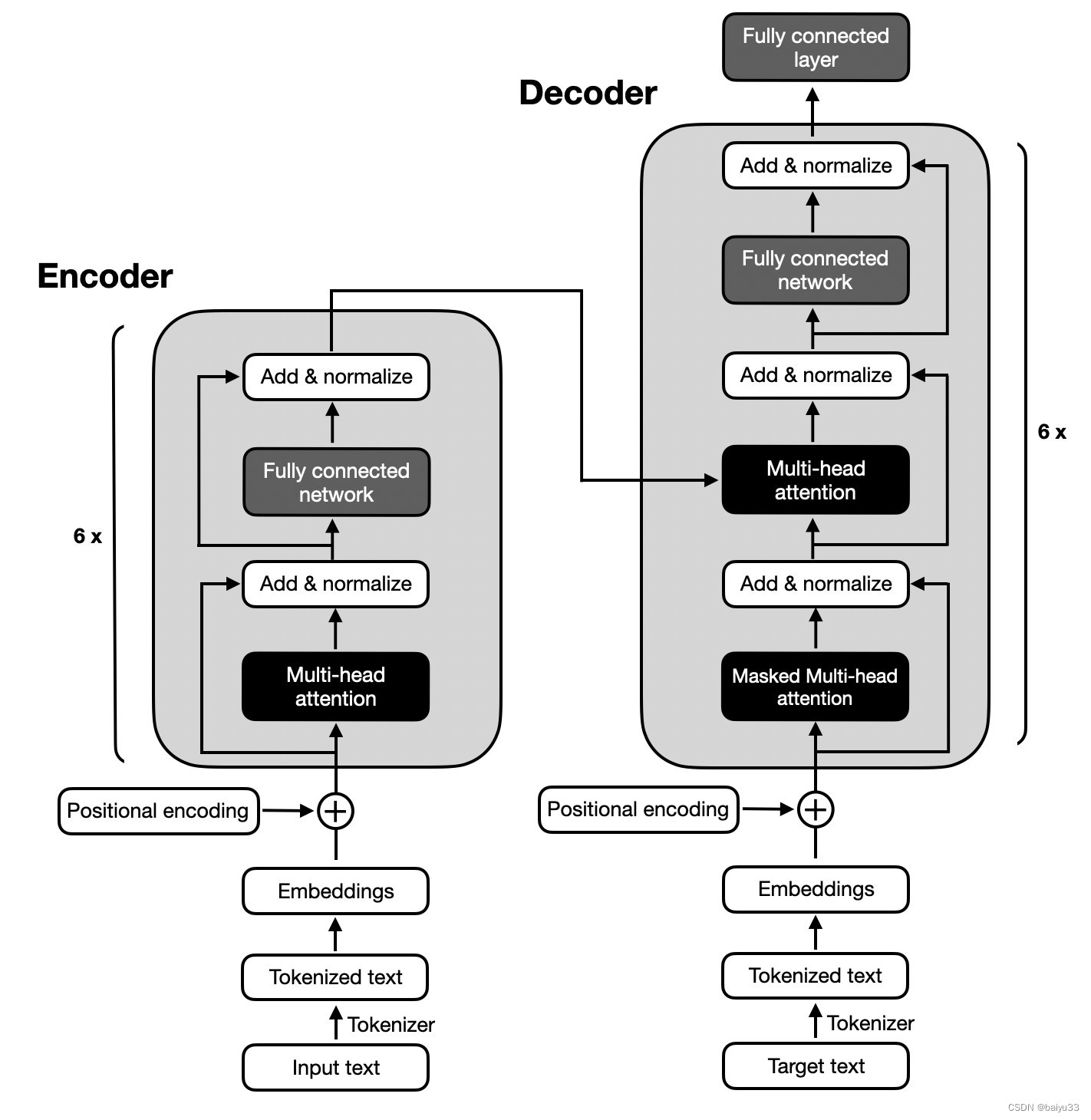
在本章中,我们为理解LLMs奠定了基础。在本书的其余部分,我们将从头开始编写一个代码。我们将以 GPT 背后的基本思想为蓝图,分三个阶段解决这个问题,如图 1.9 所示。
图 1.9 本书中介绍的构建LLMs阶段包括实现LLM架构和数据准备过程、预训练以创建基础模型,以及微调基础模型以LLM成为个人助理或文本分类器。
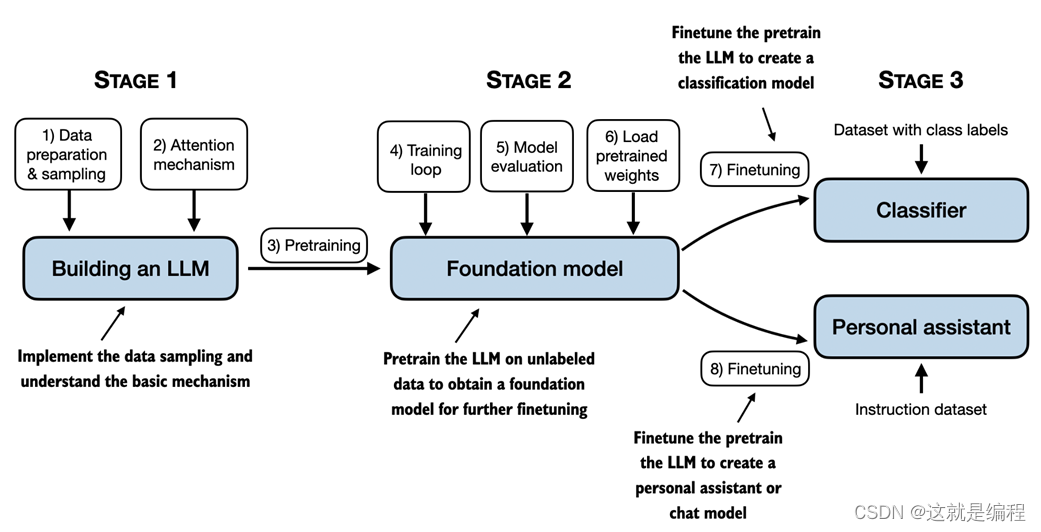
首先,我们将了解基本的数据预处理步骤,并编写每个 LLM.
接下来,在第 2 阶段,我们将学习如何编码和预训练能够生成新文本的类似 LLM GPT。我们还将介绍评估LLMs的基础知识,这对于开发有能力的 NLP 系统至关重要。
请注意,从头开始预训练大型LLM模型是一项艰巨的工作,需要数千到数百万美元的计算成本才能获得类似 GPT 的模型。因此,第 2 阶段的重点是使用小型数据集实施用于教育目的的培训。此外,本书还将提供用于加载公开可用的模型权重的代码示例。
最后,在第 3 阶段,我们将进行预训练LLM并对其进行微调,以遵循回答查询或对文本进行分类等指令——这是许多实际应用和研究中最常见的任务。
LLMs改变了自然语言处理领域,该领域以前依赖于明确的基于规则的系统和更简单的统计方法。LLMs引入了新的深度学习驱动方法,导致了理解、生成和翻译人类语言的进步。
- <
原文地址:https://blog.csdn.net/cq20110310/article/details/135505676
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。
如若转载,请注明出处:http://www.7code.cn/show_54608.html
如若内容造成侵权/违法违规/事实不符,请联系代码007邮箱:suwngjj01@126.com进行投诉反馈,一经查实,立即删除!
声明:本站所有文章,如无特殊说明或标注,均为本站原创发布。任何个人或组织,在未征得本站同意时,禁止复制、盗用、采集、发布本站内容到任何网站、书籍等各类媒体平台。如若本站内容侵犯了原著者的合法权益,可联系我们进行处理。