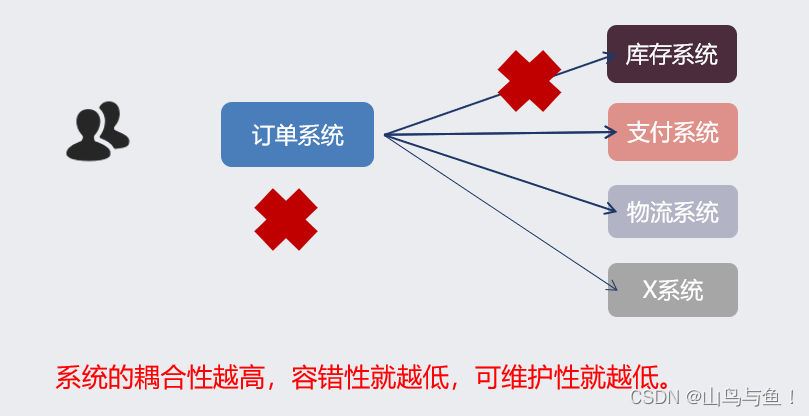
本文介绍: 对于上面的情况,我们迫切需要一些新工具,帮我们精准分析性能问题。于是,分布式系统下链路追踪技术(Distributed Tracing)出现了。它的核心思想是:在用户一次请求服务的调⽤过程中,无论请求被分发到多少个子系统中,子系统又调用了更多的子系统,我们把系统信息和系统间调用关系都追踪记录下来。最终把数据集中起来可视化展示。它会形成一个有向图的链路,看起来像下面这样。
为什么需要分布式链路追踪
提到分布式链路追踪,我们要先提到微服务。相信很多人都接触过微服务。微服务是一种开发软件的架构和组织方法,它侧重将服务解耦,服务之间通过API通信。使应用程序更易于扩展和更快地开发,从而加速新功能上线。
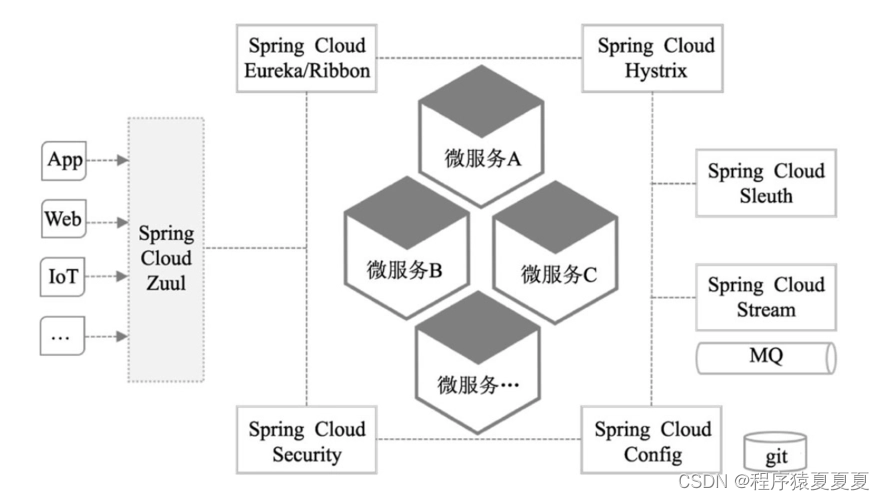
加速研发快速迭代,让微服务在业务驱动的互联网领域全面普及,独领风骚。但是,随之而来也产生了新问题:当生产系统面对高并发,或者解耦成大量微服务时,以前很容易就能实现的监控、预警、定位故障就变困难了。
接下来我们拿一笔支付的例子来举例
比如支付付款这样一个行为,其实是对多个服务器发起了一个请求,这个请求会被发送到多个微服务系统,通俗的讲,这些微服务系统分别用来查询用户信息,查询余额,请求支付等等。每个子系统的做完这一套操作后,会把对应结果展示给用户。
用户一次操作,做了这么一个“全局操作”。任何一个子系统变慢,都会导致最终的操作变得慢,那用户体验就会很差了。
看到这里,你可能会想,体验差我们做优化不就好了么?确实如此,但一般情况,一个前端或者后端工程师虽然知道系统查询耗时,但是他无从知晓这个问题到底是由哪个服务调用造成的,或者为什么这个调用性能差强人意。
这个工程师可能无法准确定位到这次全局搜索是调用了哪些服务,因为新的服务、乃至服务上的某个功能,都有可能在任何时间上过线或修改过。其次,你不能苛求这个工程师对所有参与这次全局搜索的服务都了如指掌,每一个服务都有可能是由不同的团队开发或维护的。再次,搜索服务还同时还被其他客户端使用,比如手机端,这次全局搜索的性能问题甚至有可能是由其他应用造成的。
什么是分布式链路追踪
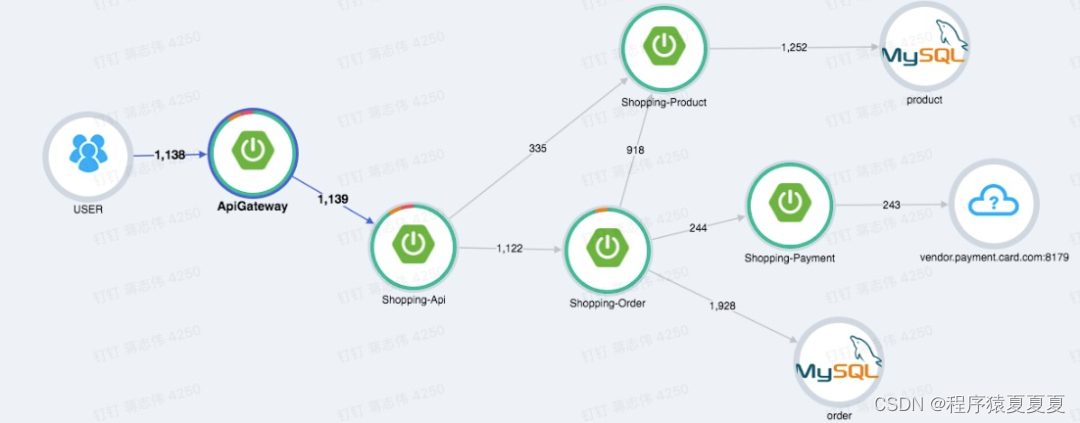
链路Trace的核心结构
我们如何将这个链路串联起来呢?
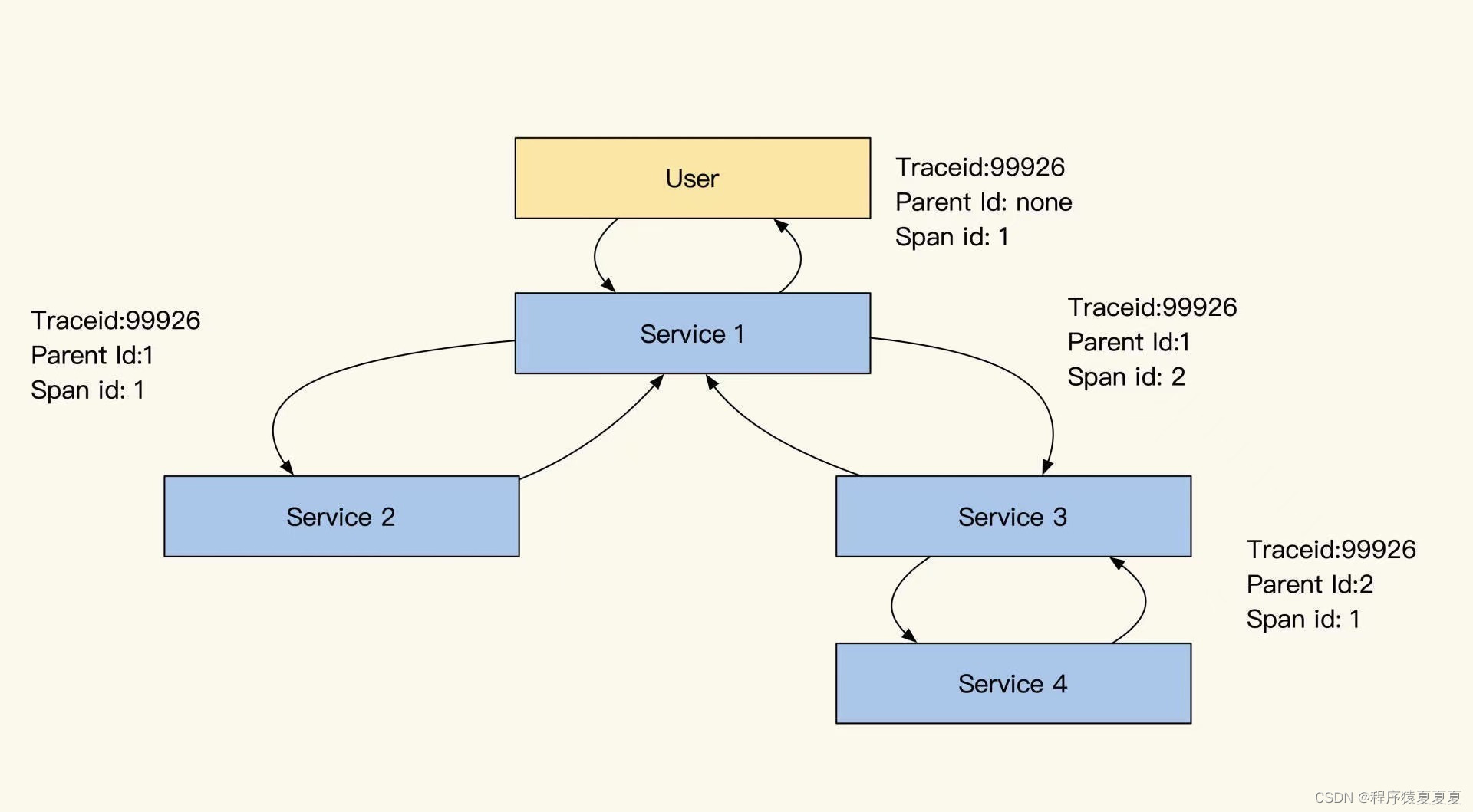
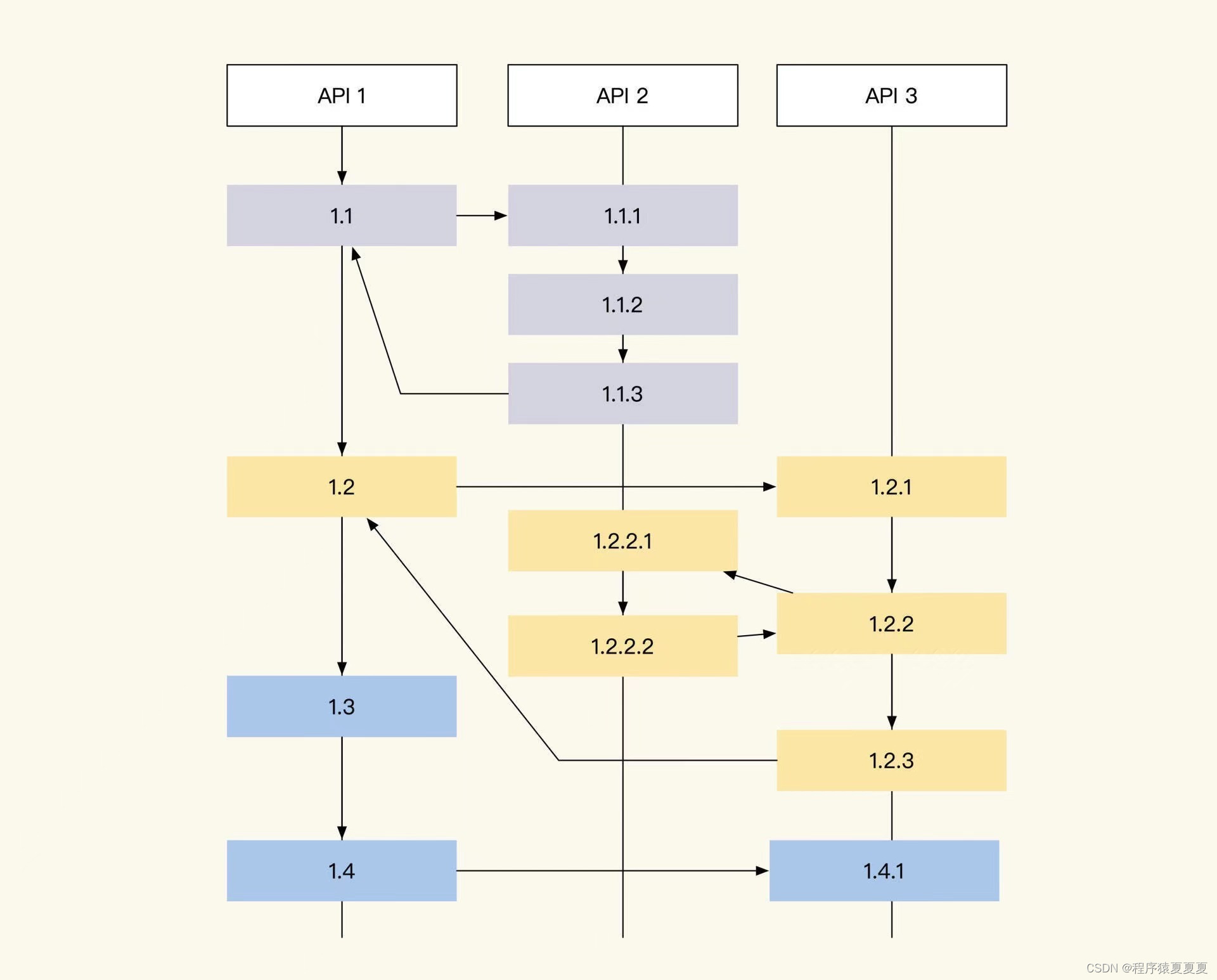
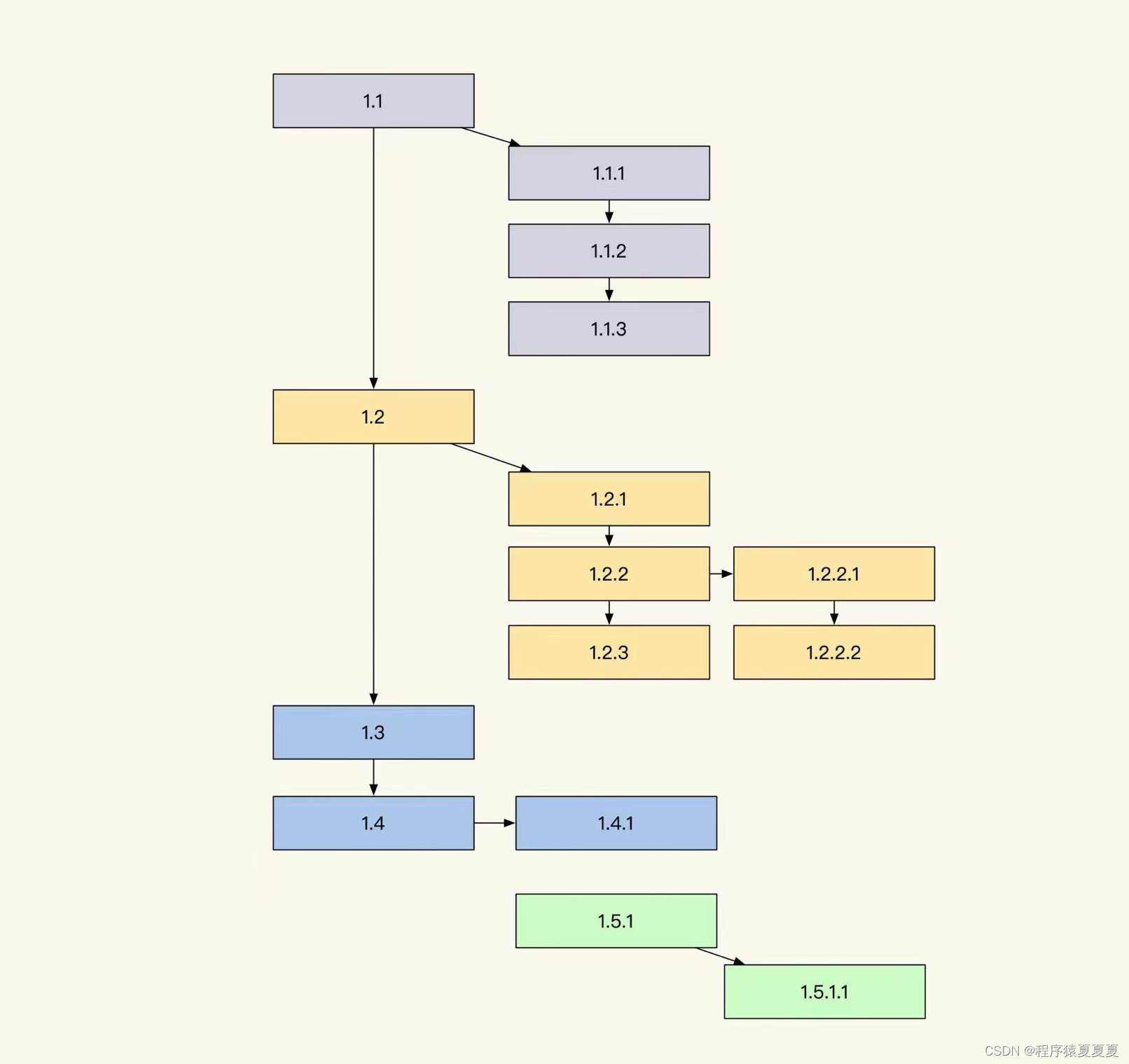
日志样式的定义
日志实现方式
声明:本站所有文章,如无特殊说明或标注,均为本站原创发布。任何个人或组织,在未征得本站同意时,禁止复制、盗用、采集、发布本站内容到任何网站、书籍等各类媒体平台。如若本站内容侵犯了原著者的合法权益,可联系我们进行处理。