本文介绍: Scrapy是一个为了爬取网站数据,提取结构性数据而编写的应用框架。可以应用在包括数据挖掘,信息处理或存储历史数据等一系列的程序中。
Scrapy是一个为了爬取网站数据,提取结构性数据而编写的应用框架。 可以应用在包括数据挖
掘,信息处理或存储历史数据等一系列的程序中。
1. 安装scrapy:
注意:需要安装在python解释器相同的位置,例如:D:Program FilesPython3.11.4Scripts
若安装时报错缺少twisted,解决方法:安装twisted合适的版本 twisted下载路径
下载 twisted后,安装twisted:pip install twisted路径
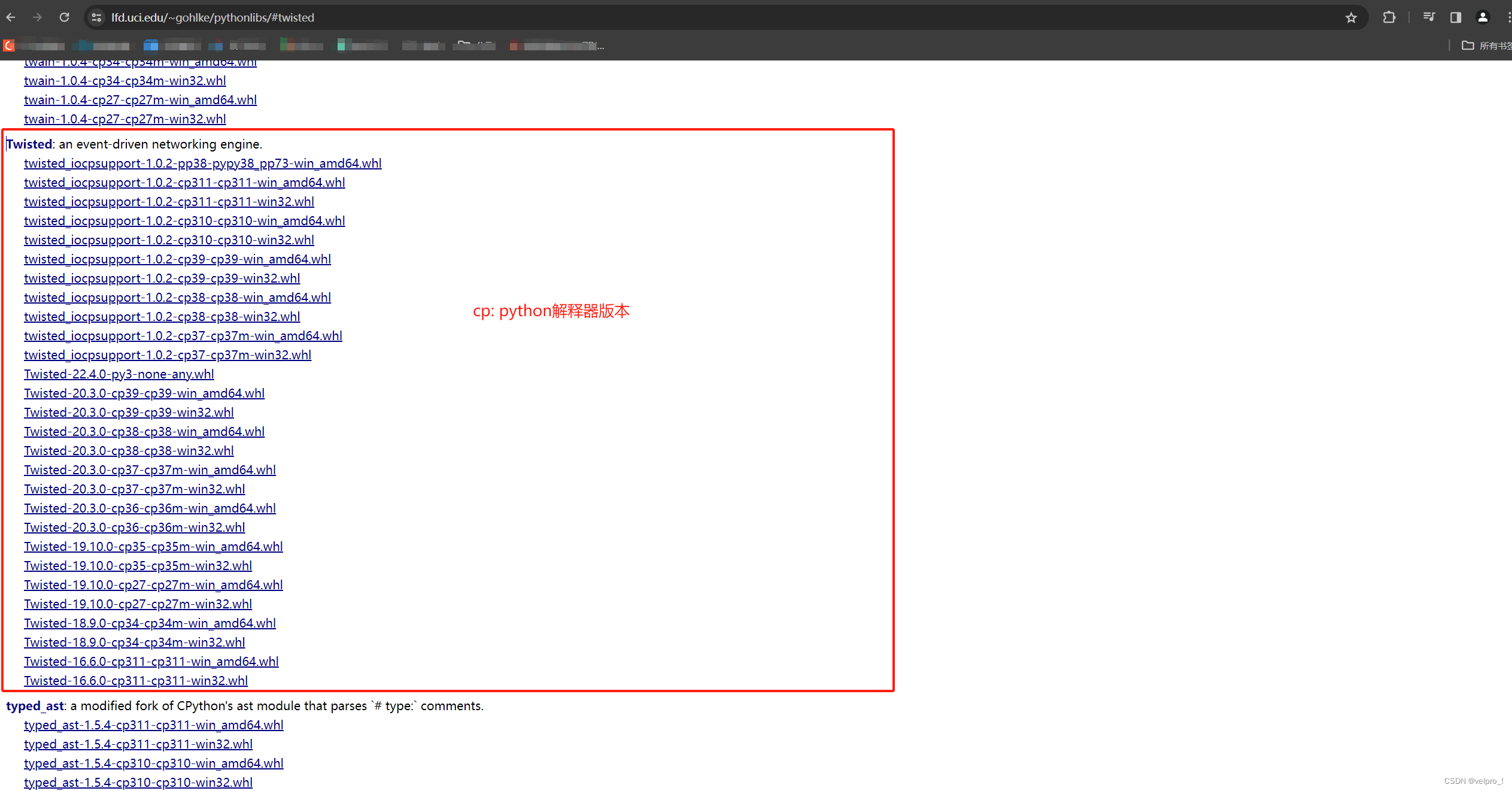 查看python版本:终端输入python
查看python版本:终端输入python

2. 使用scrapy创建项目:

3. 创建爬虫文件

4. 运行爬虫程序

声明:本站所有文章,如无特殊说明或标注,均为本站原创发布。任何个人或组织,在未征得本站同意时,禁止复制、盗用、采集、发布本站内容到任何网站、书籍等各类媒体平台。如若本站内容侵犯了原著者的合法权益,可联系我们进行处理。