本文介绍: c语言设置了一些预定义符号,可以直接使用,预定义符号也是在预处理期间处理的FILE//进行编译的源文件LINE//文件当前的行号DATE//文件被编译的日期TIME//文件被编译的时间STDC//如果编译器遵循ANSI C,其值为1,否则未定义举个例子:FILELINE基本语法:举个例子#define reg register //为了register这个关键字,创建一个简短的名字😉 //用更形象的符号来替换一种实现。
目录
1. 预定义符号
c语言设置了一些预定义符号,可以直接使用,预定义符号也是在预处理期间处理的
举个例子:
2. #define定义常量
基本语法:
举个例子
3. #define定义宏
4. 带有副作用的宏参数
5. 宏替换的规则
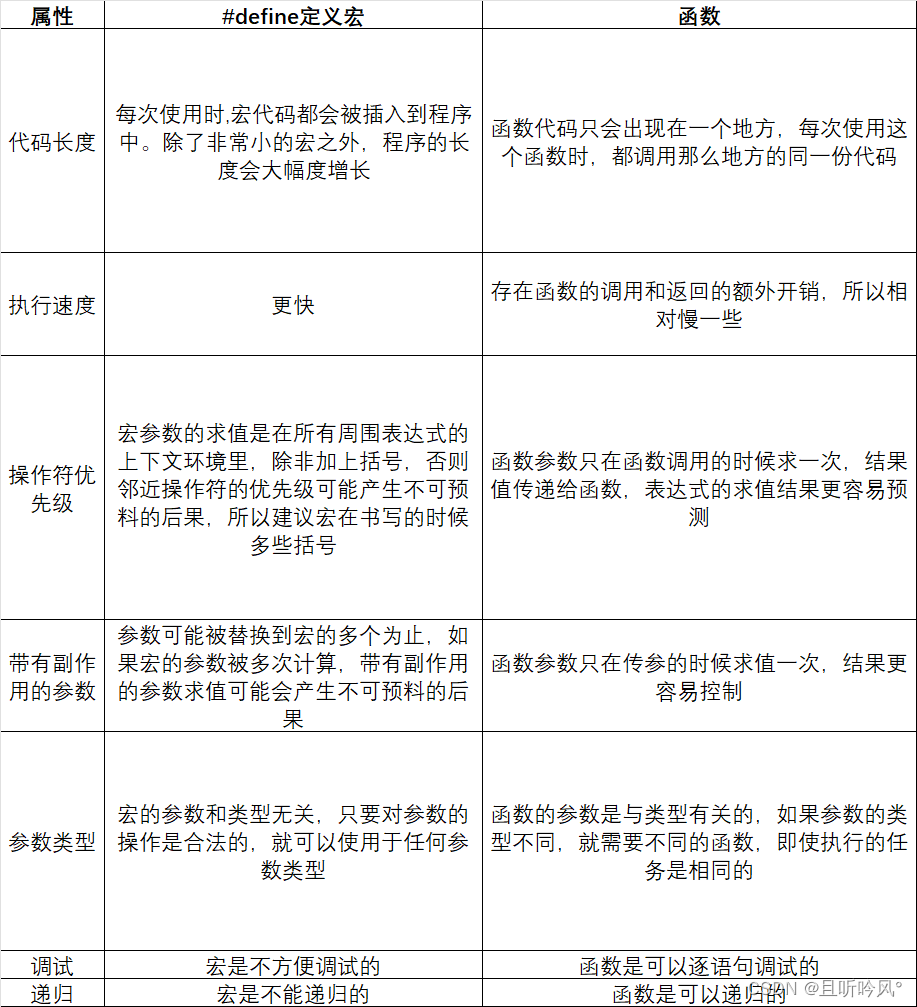
6. 宏函数的对比
7. #和##
7.1 #运算符
7.2 ##运算符
8. 命名约定
9. undef
10. 命令行定义
11. 条件编译
12. 头文件的包含
12.1 头文件被包含的方式:
12.1.1 本地文件包含
12.1.2 库文件包含
12.2 嵌套文件包含
13. 其他预处理指令
声明:本站所有文章,如无特殊说明或标注,均为本站原创发布。任何个人或组织,在未征得本站同意时,禁止复制、盗用、采集、发布本站内容到任何网站、书籍等各类媒体平台。如若本站内容侵犯了原著者的合法权益,可联系我们进行处理。