1. XML概述

XML是EXtensible Markup Language的缩写,翻译过来就是可扩展标记语言。XML是一种用于存储和传输数据的语言,它使用标签来标记数据,以便于计算机处理和我们人来阅读。
- “可扩展”三个字表明XML可以根据需要进行扩展和定制。这意味着XML可以根据特定的应用场景和需求来定义自己的标签和语法,使得XML具有很高的灵活性和适应性。
- XML和HTML一样都是标记语言,它们的基本语法都是标签。在XML中,数据被包含在标签中,而标签则由尖括号(<>)包围。如下图示例:
<person>
<name>John Doe</name>
<age>30</age>
</person>在这个例子中,person、name和age都是标签,而John Doe和30则是标签中的 数据。
- 我们需要了解XML的基本语法,以便知道如何正确地修改这些配置文件以满足我们的需求。对于XML基本语法,我们并不需要从开始完全手动编写XML文档,因为许多第三方应用程序和框架已经提供了配置文件供我们使用和修改。我们需要根据实际的需求来修改这些文件,而这些修改的方式则取决于XML的基本语法和具体的XML约束。
所以简单来讲:XML(可扩展标记语言)是一种标记语言,它使用一系列标签来描述数据。这些标签可以用来表示不同类型的数据,如元素、属性、注释等。XML 的目标是提供一种易于阅读和理解的文本格式,用于存储和传输数据,同时能够被不同的系统和技术轻松地解析和使用。因此,XML 可以被视为一种数据格式。
2. 为什么需要XML
- XML可用于两个程序之间进行数据通信。它是一种通用的标记语言,可以轻松地在不同的程序或系统之间交换数据。
- XML可用于创建配置文件,例如为服务器指定应当监听的端口、连接数据库的用户名和密码等。当服务器程序启动时,它可以读取这些配置文件并相应地执行操作。
- Spring中的配置文件、mybatis的Mapper文件、tomcat的server.xml文件、web.xml文件等都使用XML格式。这是因为XML易于阅读和编写,并且具有灵活的数据表示和结构。
- XML能够存储复杂的数据关系。它支持嵌套的元素和属性,因此可以表示层次结构复杂的数据。这使得XML成为存储和处理复杂数据结构的理想选择。
2.1. XML 技术用于解决什么问题
- 数据传输:XML可以用于在不同程序或系统之间进行数据传输,但由于JSON格式的简洁性和高效性,现在更多地使用JSON来进行数据传输。
- 配置文件:XML可以用来编写配置文件,许多服务器和应用程序都使用XML文件来定义其行为和特性。比如Tomcat服务器的server.xml和web.xml文件就是使用XML编写的。
- 数据库:XML也可以作为小型数据库使用,如果您需要在程序中存储和检索数据,而使用数据库会增加额外的维护工作,那么XML可以是一个很好的选择。将数据存储在XML文件中可以使读取速度更快,而且不需要额外的数据库管理系统。
3. XML快速入门
<?xml version="1.0" encoding="utf-8" ?>
<!--
<?xml version="1.0" encoding="utf-8" ?> 声明XML文档的版本和字符编码
<students> 根标签/标签,一个xml文件中只能存在一个,程序员自己命名
<student> 根标签/标签,程序员自己命名的子标签,可以有多个
-->
<students>
<student id="1">
<id>1</id>
<name>张三</name>
<age>20</age>
</student>
<student id="2">
<id>2</id>
<name>李四</name>
<age>21</age>
</student>
</students>4. XML语法
一个 XML 文件分为如下几部分内容:
4.1. 文档声明
<?xml version="1.0" encoding="utf-8" ?>4.2. 元素
- 每个 XML 文档必须有且只有一个根元素。
- 根元素是一个完全包括文档中其他所有元素的元素。
- 根元素的起始标记要放在所有其他元素的起始标记之前。
- 根元素的结束标记要放在所有其他元素的结束标记之后。
- XML 元素指 XML 文件中出现的标签,一个标签分为开始标签和结束标签,一个
标签有如下几种书写形式
不含标签体的:<a></a>, 简写为:<a/>
示例:
<博客文章>
<标题>我的博客文章</标题>
<作者>张三</作者>
<日期>2023-07-06</日期>
<内容>这是我的最新博客文章。</内容>
</博客文章>- 这个XML文档只有一个根元素,那就是“博客文章”。所有的其他元素都包含在这个根元素中。
- 根元素“博客文章”完全包括文档中的其他所有元素,如”标题”、”作者”、”日期“和”内容“。
- 根元素的起始标记
<博客文章>在所有其他元素的起始标记之前。 - 根元素的结束标记
</博客文章>在所有其他元素的结束标记之后。 - XML元素是指XML文件中的标签。这个XML文档中的标签有开始标签和结束标签,例如
<博客文章>是开始标签,</博客文章>是结束标签。也有一些标签是不含标签体的,例如<作者>张三</author>中的</author>,这种情况下,我们通常简写为<author/>。 - 这个XML文档中的标签没有交叉嵌套,都是合理地嵌套的。例如,“标题”元素是“博客文章”元素的子元素,”作者”、”日期“和”内容“元素又是”博客文章”元素的子元素。
- 区分大小写:XML元素名称是区分大小写的,这意味着”<P>”和”<p>”被视为两个完全不同的元素。
- 不能以数字开头:XML元素名称不能以数字开头。这意味着”<123>”是无效的,而”<Book123>”是有效的。
- 不能包含空格:XML元素名称中不能包含空格。例如,”<book title>”是无效的,你应该使用下划线或其他字符来替换空格,如”<book_title>”。
- 名称中间不能包含冒号(:):在XML元素名称中,你不能使用冒号(:)。这通常用于命名空间,但在元素名称本身中是无效的。
- 如果标签单词需要间隔,建议使用下划线:如果你需要在一个元素名称中使用间隔,建议使用下划线,而不是冒号或其他字符。例如,”<book-title>”是有效的,而”book:title“(使用了冒号)是无效的。
在很多时候,说 标签、元素、节点是相同的意思
4.3. 属性
示例:
<book id="12345" title="XML教程" author="张三" year="2023">在这个例子中,book元素具有四个属性:id、title、author和year。每个属性的值用双引号(”)分隔。
注意以下几点:
- 一个元素可以有多个属性,如上面的book元素。
- 特定的属性名称在同一个元素标记中只能出现一次。这意味着你不能有两个同名的属性,如两个title属性。
- 属性值不能包括&字符。这是因为&字符在XML中用于表示实体引用,如&amp;表示字符&。如果你在属性值中直接使用&,XML解析器将无法正确解析它。在这种情况下,你应该使用其对应的实体引用,如上述例子中的&amp;。
4.4. 注释
<!-- 这是一个注释 -->4.5. CDATA节
在XML中,解析器会根据一定的规则对文本进行解析,这些规则包括如何识别元素、属性和文本内容等。当解析器遇到一个文本片段时,它会尝试将其解析为XML的一部分,例如一个元素或一个属性的值。
然而,有些文本片段可能包含一些特殊字符,这些字符在XML中具有特殊的含义。例如,<和>分别用于表示元素的开始和结束,而&用于表示字符实体。如果一个文本片段中包含这些特殊字符,并且被解析器识别为XML的一部分,那么可能会导致错误或意外的结果。
为了解决这个问题,XML提供了CDATA部分。CDATA部分是一个特殊的区域,其中的文本不会被解析器解析或解释。这意味着你可以将包含特殊字符的文本放在CDATA部分中,而不用担心它们会被误解为XML标记。
在CDATA部分中,你可以放置任何文本,包括HTML、JavaScript代码、非标准字符等等。这些文本都会被当作原始文本处理,而不是XML标记。
CDATA部分的开始标记是:“<![CDATA[” , 结束标记是 “]]>”
示例:
<![CDATA[ 这里的内容不会被XML解析器解析,而是作为原始文本处理。 ]]>在CDATA部分中,你可以放置任何文本,包括那些可能会被解析器误解为XML标记的内容。例如,如果你有一些特殊的字符(如 <, >, & 等)在你的XML中,你可以将它们放在CDATA部分中,以防止解析器误解为XML标记。
那为什么不用注释而是使用CDATA节?
CDATA节和注释在XML中的用途不同。注释是用来对XML文档的内容进行解释或说明的,它们不会被解析器解析或解释。而CDATA节则是用来包含那些可能会被解析器误解为XML标记的文本。
CDATA节是一个特殊的区域,其中的文本不会被解析器解析或解释。这意味着你可以将包含特殊字符的文本放在CDATA节中,而不用担心它们会被误解为XML标记。这对于包含特殊字符(如<, >, &等)的文本非常有用,因为这些字符在XML中有特殊的含义。
注释对于解释XML文档的内容非常有用,但它们不会被解析器解析。因此,如果你需要在XML文档中使用注释,你可以使用<!– –>来添加注释。但是,CDATA节和注释是不同的概念,它们的用途不同。
5. XML的转义字符
在XML中,有一些特殊字符具有特殊的含义,例如 <、>、& 等。如果想要在XML中显示这些特殊字符的原始样式,可以使用转义字符的形式进行处理。
|
字符 |
含义 |
|
&lt; |
表示小于号(<) |
|
&gt; |
表示大于号(>) |
|
&amp |
表示和号(&) |
|
' |
表示单引号(’) |
|
" |
表示双引号(”) |
举例来说,如果要在XML中显示文本“5 < 10”,可以使用转义字符的形式表示小于号,即写成“5 < 10”。这样就不会被解析器误解为元素标记。
6. XML文档总结
一个格式正规的 XML 文档需要遵循以下规则:
- 文档必须以 XML 声明语句开始,指定版本和编码方式。
- 文档中必须有且仅有一个根元素,所有的其他元素都必须是该根元素的子元素。
- 标记(元素)的大小写必须区分,即标记的大小写必须一致。
- 属性值必须用引号括起来。
- 标记必须成对出现,每个开标记都必须有一个对应的闭标记。
- 空标记(没有内容和子元素的标记)也必须关闭。
- 元素的嵌套必须正确,例如,一个元素的内容不能是其自身的子元素。
7. DOM4J
7.1. XML解析技术原理
- 不管是 html 文件还是 xml 文件它们都是标记型文档,都可以使用 w3c 组织制定的 dom 技术来解析
- document 对象表示的是整个文档(可以是 html 文档,也可以是 xml 文档)
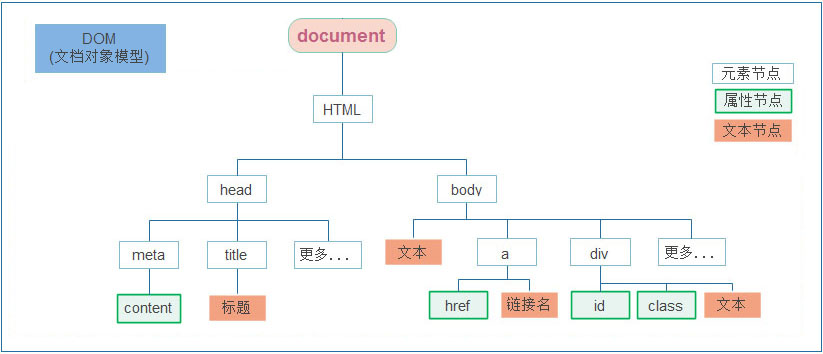
7.2. XML 解析技术介绍
DOM:DOM(Document Object Model)是一种XML解析技术,它将XML文档表示为一个由对象组成的树形结构,每个对象代表一个元素或属性。通过DOM API,我们可以访问和操作这些对象,从而获取XML文档中的数据。DOM解析技术提供了一种全面的XML文档表示方式,但它在内存占用和性能方面可能不太理想。
SAX:SAX(Simple API for XML)是一种基于事件驱动的XML解析技术。它通过调用回调函数来通知用户当前正在解析的元素和属性。SAX解析器逐行读取XML文档,不需要将整个文档加载到内存中,因此具有较高的性能。与DOM相比,SAX更适合处理大型XML文档,并且更适合在处理过程中进行流式操作。
但这两个技术已经过时,了解即可。
7.3. DOM4J介绍
参考文档传送门 –> dom4j 1.6.1 API
DOM4J 是一个用于处理 XML 文件的库,它提供了一个简单且灵活的 API,可以高效地解析和处理 XML 文件。与 JDOM 不同的是,DOM4J 使用接口和抽象基类,这使得它更加灵活,并且可以提供更好的性能。
DOM4J 的 API 相对较复杂,但它提供了许多强大的功能,例如 XPath 查询、XML 验证、XML 序列化等。此外,DOM4J 还具有极佳的性能,可以在处理大型 XML 文件时保持高效率。
由于 DOM4J 的优秀性能和易用性,现在很多软件都在采用它来处理 XML 文件。如果你需要在 Java 应用程序中解析和处理 XML 文件,那么 DOM4J 是一个非常不错的选择。
要使用 DOM4J 进行开发,你需要下载相应的 jar 文件,并将其添加到你的 Java 项目中。这样你就可以使用 DOM4J 提供的功能来解析和处理 XML 文件了。
7.4. DOM4j中获取Document对象的三种方法
首先,DOM4j是一个Java库,用于处理XML文档。它提供了一种非常灵活和强大的方式来解析、操作和创建XML文档。
在DOM4j中,Document对象是XML文档的根节点,它代表了整个XML文档。因此,获取Document对象是进行XML操作的首要步骤。
当使用DOM4j来处理XML文档时,有三种主要方法可以获得Document对象:
- 从XML文件读取:
当你有一个XML文件需要处理时,你可以使用SAXReader类来读取文件并生成一个Document对象。SAXReader是一个事件驱动的解析器,它通过读取文件内容并触发事件来生成DOM树。这种方法适用于处理大型XML文件,因为它不需要将整个文件加载到内存中。
代码示例:
SAXReader reader = new SAXReader();
File file = new File("src/input.xml");
Document document = reader.read(file);
- 解析XML文本:
如果你有一串XML格式的文本字符串,你可以使用DocumentHelper.parseText()方法将其解析为Document对象。这种方法适用于处理较小的XML片段或字符串,并且不需要从外部文件读取。
代码示例:
String text = "<members></members>";
Document document = DocumentHelper.parseText(text);
- 主动创建:
如果你需要从零开始构建一个XML文档,你可以使用DocumentHelper.createDocument()方法创建一个空的Document对象,然后使用addElement()方法添加元素。这种方法适用于创建自定义的XML文档,或者构建一个全新的XML结构。
代码示例:
Document document = DocumentHelper.createDocument();
Element root = document.addElement("members");
原文地址:https://blog.csdn.net/Sakurapaid/article/details/134607043
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。
如若转载,请注明出处:http://www.7code.cn/show_5473.html
如若内容造成侵权/违法违规/事实不符,请联系代码007邮箱:suwngjj01@126.com进行投诉反馈,一经查实,立即删除!







