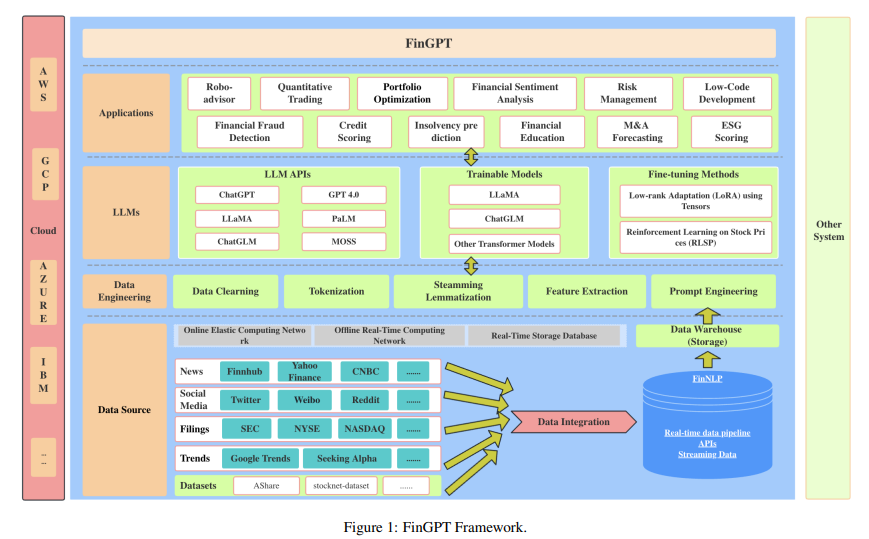
背景
FinGPT 是2023年6月哥伦比亚大学联合上海纽约大学推出全新大模型产品,这是一款面向金融领域的大模型产品。
论文:https://arxiv.org/abs/2306.06031
github:https://github.com/AI4Finance-Foundation/FinGPT
论文摘要
大型语言模型(LLMs)展示了在不同领域中革新自然语言处理任务的潜力,引发了金融领域的极大兴趣。获取高质量的金融数据是金融语言模型(FinLLMs)面临的首要挑战。虽然像BloombergGPT这样的专有模型利用了其独特的数据积累优势,但目前需要一些开源的替代方案,以实现互联网规模的金融数据的民主化。
在本文中,我们介绍了一个针对金融行业的开源大型语言模型FinGPT。与专有模型不同,FinGPT采用了以数据为中心的方法,为研究人员和实践者提供了可访问和透明的资源来开发他们的FinLLMs。我们强调了自动数据筛选流程和轻量级低秩适应技术在构建FinGPT中的重要性。此外,我们展示了一些潜在的应用,例如机器人顾问、算法交易和低代码开发。通过开源AI4Finance社区的协作努力,FinGPT旨在刺激创新,民主化FinLLMs,并在开放金融中开辟新的机会。两个相关的代码库分别是:https://github.com/AI4Finance-Foundation/FinGPT,https://github.com/AI4Finance-Foundation/FinNLP。
人工智能的持续扩展和演进为大型语言模型的普及提供了肥沃的土壤,从而在不同领域的自然语言处理中带来了一场变革性的转变。这一巨大的变化引发了人们对这些模型在金融领域潜在应用的浓厚兴趣。然而,很明显,获取高质量、最新的相关数据是开发高效的开源金融语言模型的关键因素。