一、 实验目的
1、学会训练和搭建深层神经网络;
2、掌握超参数调试正则化及优化。
二、 实验步骤
初始化
1、导入所需要的库
2、搭建神经网络模型
3、零初始化
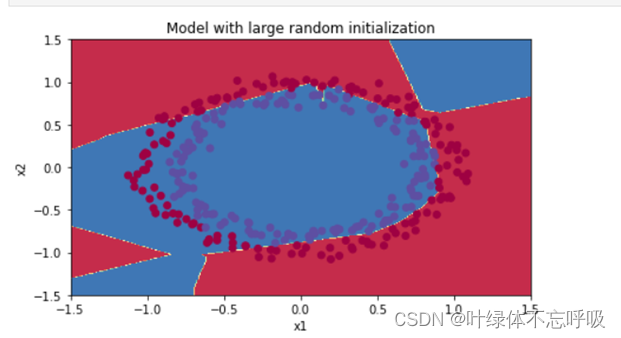
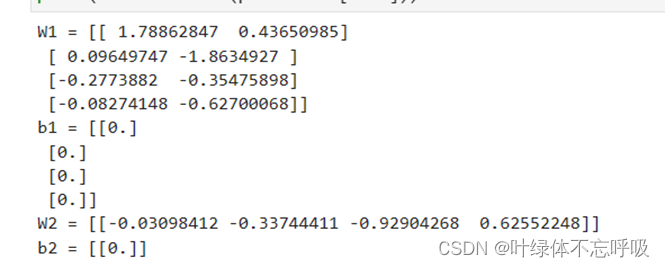
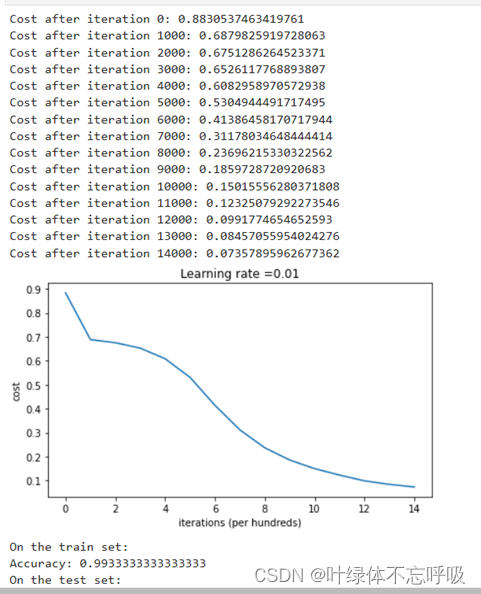
4、随机初始化
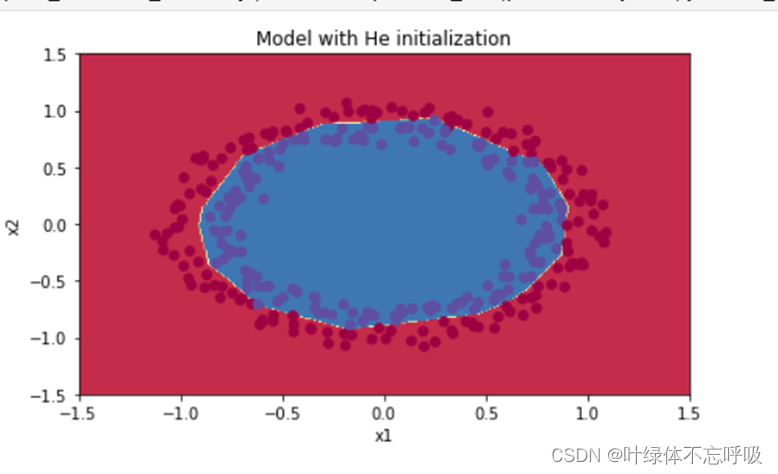
5、He初始化
6、总结三种不同类型的初始化
正则化
1、导入所需要的库
2、使用非正则化模型
3、对模型进行L2正则化(包括正向和反向传播)
4、对模型进行dropout正则化(包括正向和反向传播)
5、总结三种模型的结果
梯度检验
1、导入所需要的库
2、理解梯度检验原理
3、一维梯度检验
4、N维梯度检验(包括前向和反向传播)
梯度下降的优化
1、导入所需要的函数
2、进行梯度下降
3、进行Mini-Batch梯度下降
4、Momentum优化算法
5、Adam优化算法
三、 实验代码分析
1、import numpy as np:提供了Python进行科学计算的基础工具,包括支持多维数组和矩阵运算的功能。
2、import matplotlib.pyplot as plt:用于绘制图形和数据可视化的库。
3、from reg_utils import sigmoid, relu, plot_decision_boundary, initialize_parameters, load_2D_dataset, predict_dec:reg_utils:一个自定义的模块,其中包含了一些常用的辅助函数,用于实现正则化的机器学习模型应用,sigmoid:一个自定义的函数,用于计算sigmoid函数的值。relu:一个自定义的函数,用于计算ReLU(Rectified Linear Unit)函数的值。plot_decision_boundary:一个自定义的函数,用于绘制分类器的决策边界。initialize_parameters:一个自定义的函数,用于初始化参数。load_2D_dataset:一个自定义的函数,用于加载一个二维数据集。predict_dec:一个自定义的函数,用于绘制分类器的预测结果。
4、from reg_utils import compute_cost, predict, forward_propagation, backward_propagation, update_parameters:compute_cost:一个自定义的函数,用于计算代价函数的值。predict:一个自定义的函数,用于进行预测,forward_propagation:一个自定义的函数,用于进行前向传播过程。backward_propagation:一个自定义的函数,用于进行反向传播过程。update_parameters:一个自定义的函数,用于更新参数。
5、import sklearn:用于机器学习的库,提供了许多用于数据预处理、模型选择和评估等功能的函数和类。
6、import sklearn.datasets:sklearn库中的一个模块,包含了许多用于加载示例数据集的函数。
7、import scipy.io:scipy库中的一个模块,提供了与数据输入输出相关的功能,例如读取和写入MATLAB文件等。
8、from testCases import :这是一个自定义的模块,包含了一些测试用例,用于验证代码的正确性。
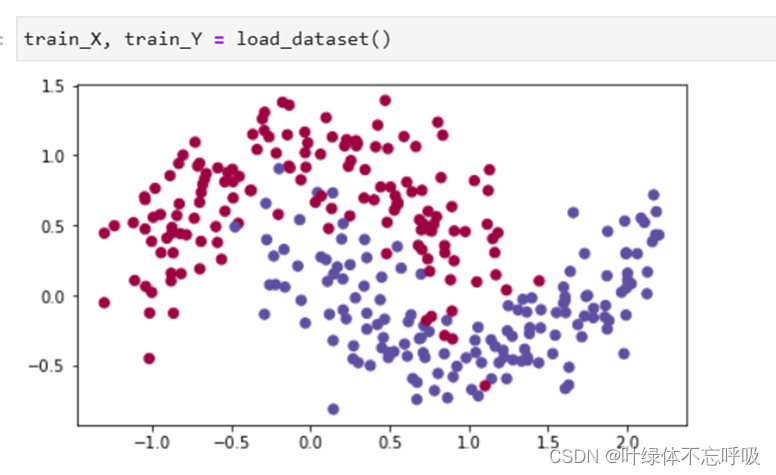
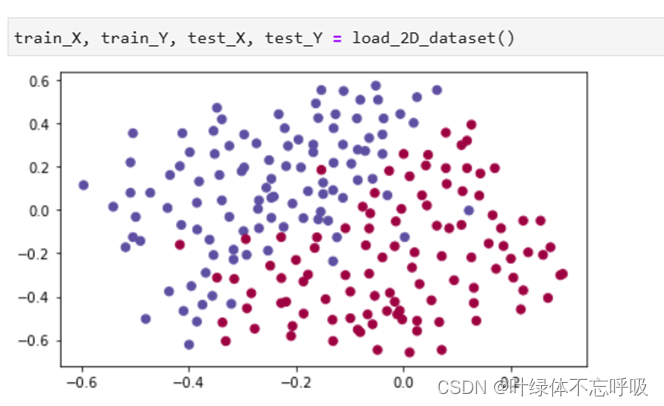
9、train_X, train_Y, test_X, test_Y = load_2D_dataset():调用了名为 load_2D_dataset()的函数,并将返回的结果赋值给了四个变量:train_X、train_Y、test_X和 test_Y,load_2D_dataset()函数是自定义的一个函数,用于加载一个二维数据集。根据函数的命名,可以猜测该函数会返回训练集的特征矩阵 train_X、训练集的标签向量train_Y、测试集的特征矩阵test_X和测试集的标签向量test_Y。
10、if lambd == 0 and keep_prob == 1:
grads = backward_propagation(X, Y, cache):条件判断,如果 lambd等于0并且keep_prob等于1。这个条件判断的目的是判断是否使用正则化或者Dropout技术。如果lambd等于0且 keep_prob等于1,表示没有进行正则化且没有使用Dropout技术。在这种情况下,通过调用backward_propagation()函数进行反向传播,计算梯度值。backward_propagation()函数接收输入X、标签 Y和缓存cache,返回计算出的梯度值grads。
11、elif lambd != 0:
grads = backward_propagation_with_regularization(X, Y, cache, lambd):条件判断,如果lambd等于0并且keep_prob等于1。这个条件判断的目的是判断是否使用正则化或者Dropout技术。如果 lambd等于0且keep_prob等于1,表示没有进行正则化且没有使用Dropout技术。然后通过调backward_propagation()函数进行反向传播,计算梯度值。backward_propagation()函数接收输入X标签、Y和缓存cache,返回计算出的梯度值grads。
12、elif keep_prob < 1:
grads = backward_propagation_with_dropout(X, Y, cache, keep_prob):条件判断,如果lambd不等于0。这个条件判断的目的是判断是否使用L2正则化。如果lambd不等于0,表示使用L2正则化。
在这种情况下,通过调用backward_propagation_with_regularization()函数进行反向传播,计算带有L2正则化的梯度值。backward_propagation_with_regularization()函数接收输入X、标签Y、缓存 cache和正则化参数lambd,返回计算出的梯度值grads。
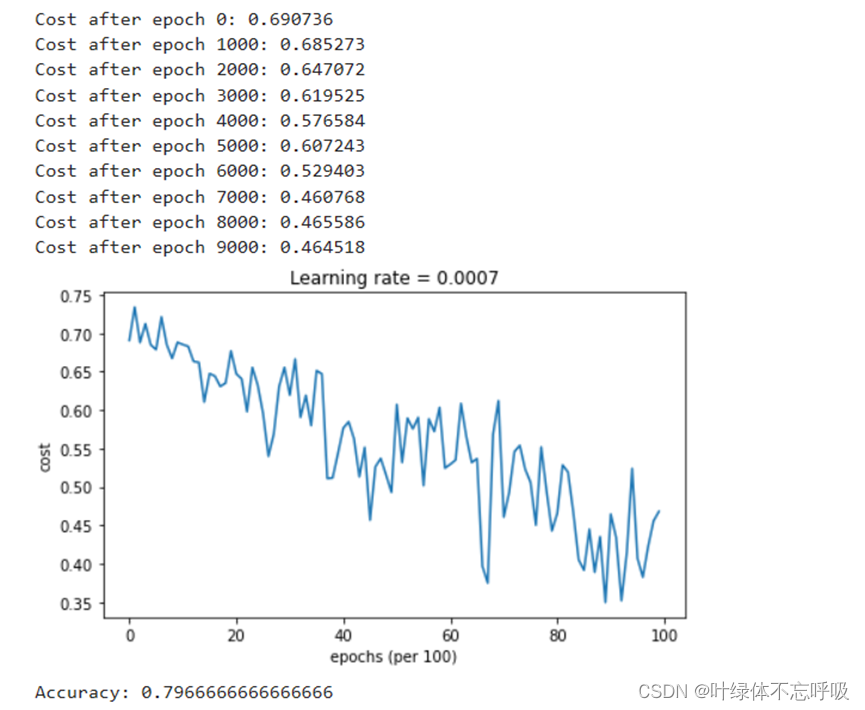
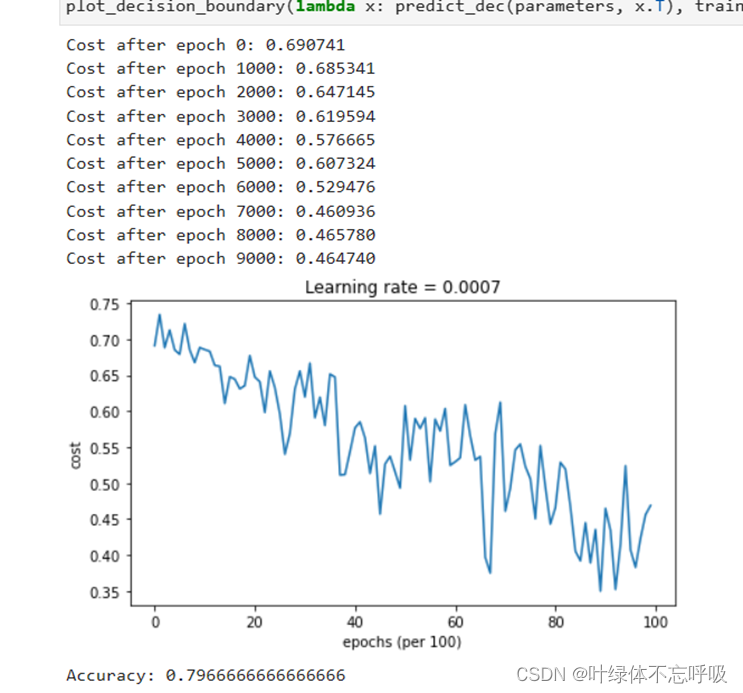
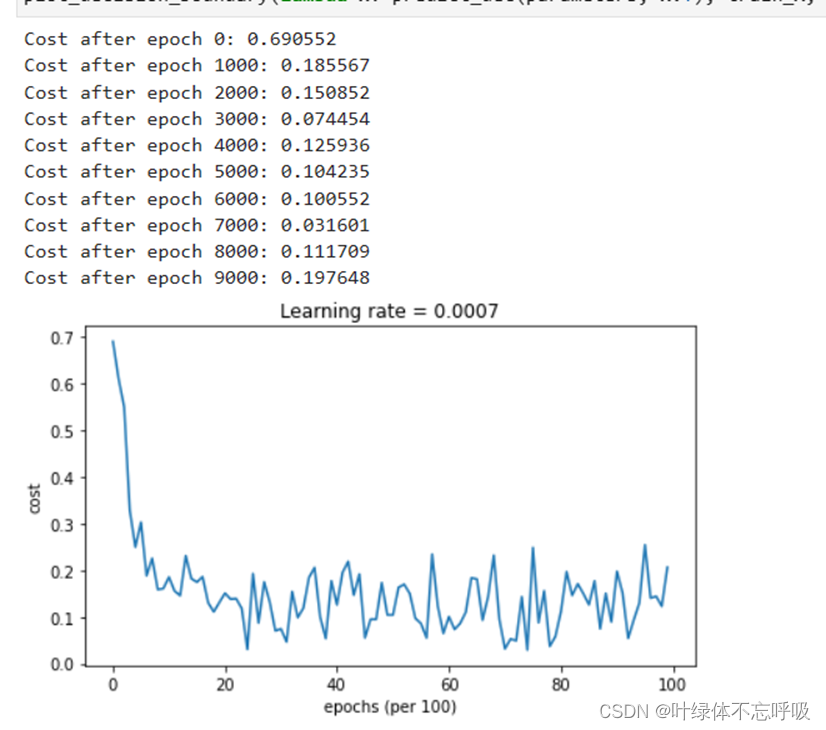
13、plt.plot(costs):使用plot()函数绘制图形。costs是一个列表,包含了每次迭代后计算得到的代价函数值。该函数会将costs中的值连接起来,生成一条曲线,表示代价函数随着迭代次数的变化情况。
14、plt.ylabel(‘cost’):设置y轴标签为”cost”。ylabel()函数用于设置y轴的标签文本。
15、plt.xlabel(‘iterations (x1,000)’):设置x轴标签为”iterations (x1,000)“。xlabel()函数用于设置x轴的标签文本。
16、plt.title(“Learning rate =” + str(learning_rate)):设置图形的标题为”Learning rate = learning_rate”。title()函数用于设置图形的标题。
17、plt.show():显示绘制的图形。show()函数用于显示所有已创建的图形。
18、axes.set_xlim([-0.75,0.40]):设置x轴的范围为[-0.75, 0.40]。set_xlim()函数用于设置x轴的取值范围。
19、axes.set_ylim([-0.75,0.65]):设置y轴的范围为[-0.75, 0.65]。set_ylim()函数用于设置y轴的取值范围。
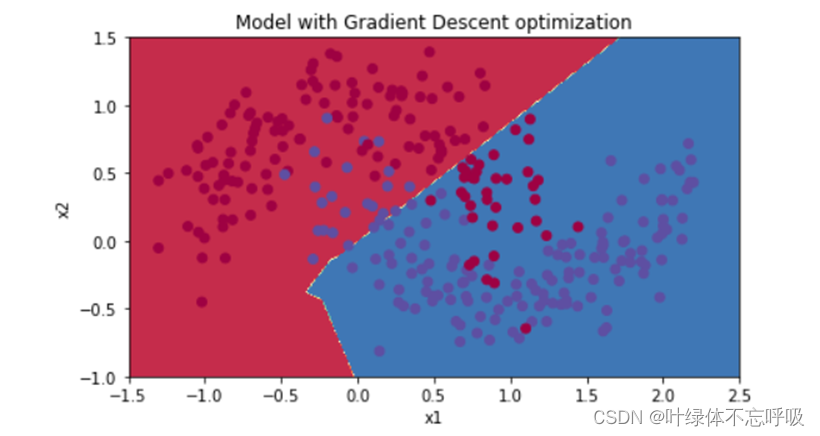
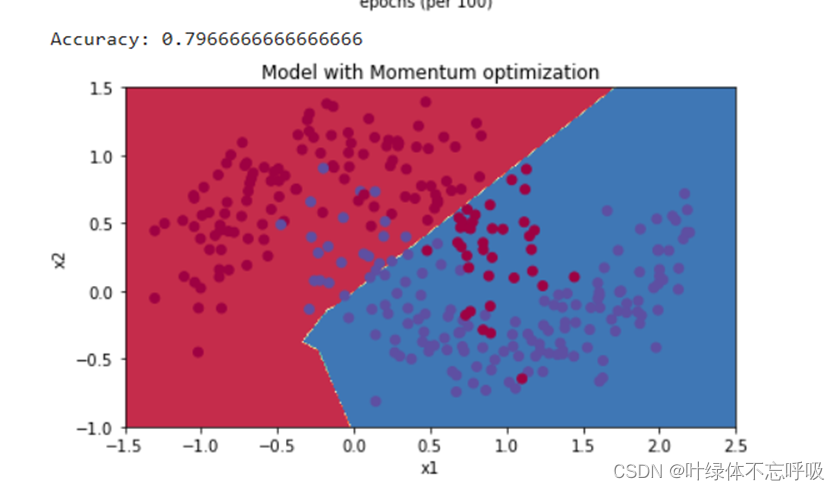
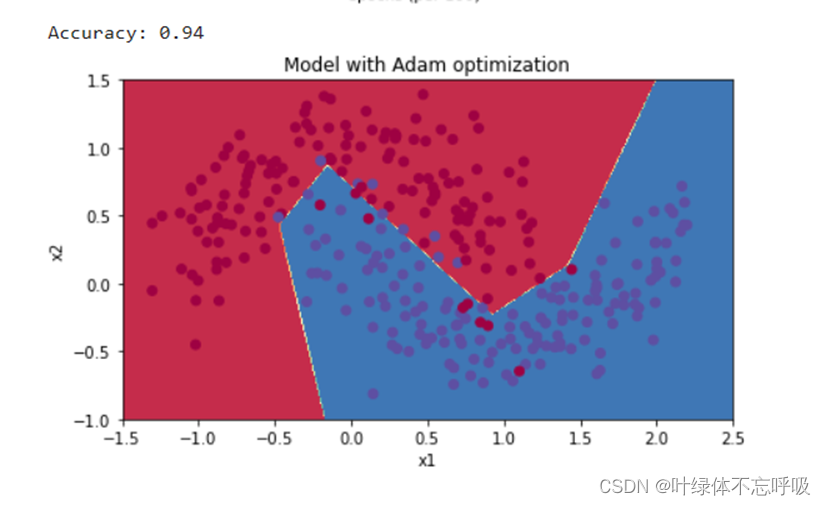
20、plot_decision_boundary(lambda x: predict_dec(parameters, x.T), train_X, train_Y):调用 plot_decision_boundary()函数来绘制决策边界。
21、plot_decision_boundary()函数接受三个参数,一个是一个lambda表达式,用于定义如何预测数据点的标签,第二个是训练集的特征矩阵train_X,第三个是训练集的标签向量train_Y。lambda x: predict_dec(parameters, x.T)是一个lambda表达式,用于定义如何预测数据点的标签。parameters是模型的参数,x.T是数据点的特征向量。
22、cross_entropy_cost = compute_cost(A3, Y):计算交叉熵损失的代价。A3是模型的输出,即预测的结果。Y是样本的真实标签值。compute_cost()函数接收两个参数,即预测值和真实值,返回计算得到的交叉熵损失。
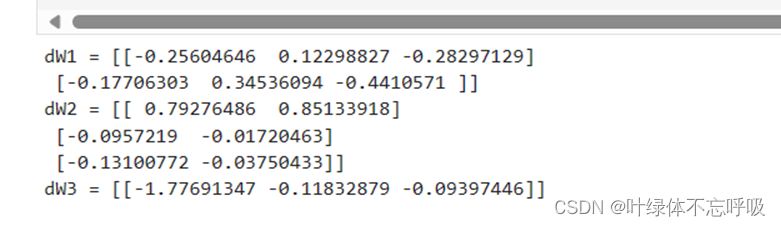
23、 L2_regularization_cost = (1./mlambd/2)(np.sum(np.square(W1))+np.sum(np.square(W2))+np.sum(np.square(W3))):计算L2正则化项的代价。L2_regularization_cost是L2正则化项的代价。
m是样本的数量。lambd是正则化超参数。W1、W2、W3是模型的权重参数。通过 np.sum(np.square(W1))的方式,计算了W1的平方和,依此类推计算了W2和W3的平方和。最终通过(1./mlambd/2)来计算L2正则化项的惩罚,得到L2正则化项的代价。
24、cost = cross_entropy_cost + L2_regularization_cost:将交叉熵损失代价与L2正则化项的代价相加,得到总的代价。cost是模型总的代价,即交叉熵损失代价与L2正则化项的代价之和。
25、dZ3 = A3 – Y:将交叉熵损失代价与L2正则化项的代价相加,得到总的代价。cost是模型总的代价,即交叉熵损失代价与L2正则化项的代价之和。
26、dW3 = 1./m * np.dot(dZ3, A2.T) + lambd/m*W3:计算输出层的激活值A3与真实标签Y之间的差异。dZ3是输出层的误差项,计算参数矩阵W3的梯度。dW3是参数矩阵W3的梯度。A2.T是A2的转置,表示上一层的激活值。lambd是正则化超参数。
27、db3 = 1./m * np.sum(dZ3, axis=1, keepdims = True):计算偏置项b3的梯度。db3是偏置项b3的梯度。axis=1表示在行方向上求和。keepdims=True表示保持求和后的维度与原来一致。
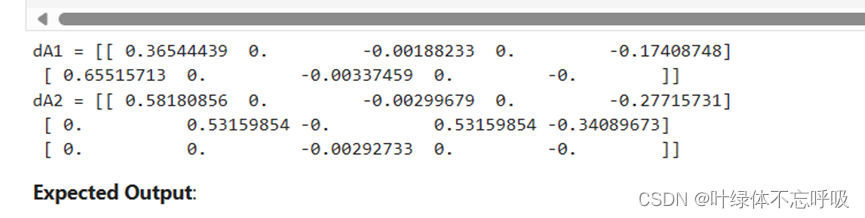
28、dA2 = np.dot(W3.T, dZ3):计算前一层的激活值A2的误差。dA2是前一层的激活值A2的误差。
29、dZ2 = np.multiply(dA2, np.int64(A2 > 0)):计算隐藏层2的误差项。dZ2是隐藏层2的误差项。np.int64(A2 > 0)用于生成一个与A2形状相同的矩阵,其中元素值为0或1,表示A2中大于0的位置。np.multiply()用于按元素进行相乘运算。计算隐藏层2的误差项。dZ2是隐藏层2的误差项。np.int64(A2 > 0)用于生成一个与A2形状相同的矩阵,其中元素值为0或1,表示A2中大于0的位置。np.multiply()用于按元素进行相乘运算。
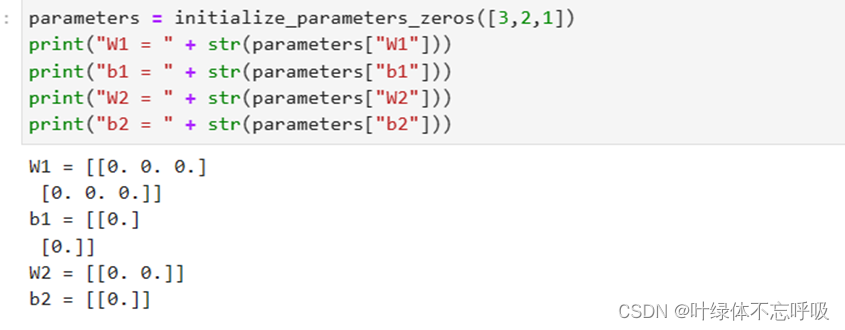
30、parameters[‘W’ + str(i)] = np.zeros((layers_dims[i], layers_dims[i – 1])):初始化权重矩阵W。parameters[‘W’ + str(i)]表示第i层的权重参数矩阵W。layers_dims[i]表示第i层的神经元数量。layers_dims[i – 1]表示第i-1层的神经元数量。np.zeros((layers_dims[i], layers_dims[i – 1]))创建了一个形状为 (layers_dims[i], layers_dims[i – 1])的全零矩阵,用于存储第i层的权重参数。
31、 parameters[‘b’ + str(i)] = np.zeros((layers_dims[i], 1)):初始化偏置parameters[‘b’ + str(i)]表示第i层的偏置项b。layers_dims[i]表示第i层的神经元数量。np.zeros((layers_dims[i], 1))创建了一个形状为(layers_dims[i], 1)的全零矩阵,用于存储第i层的偏置项。
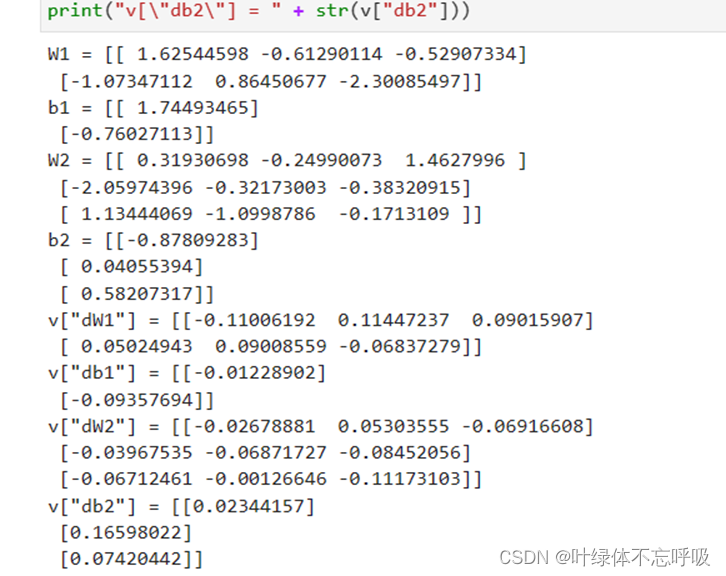
32、parameters[‘W’ + str(i)] = np.random.randn(layers_dims[i], layers_dims[i – 1]) * 10:np.random.randn(layers_dims[i], layers_dims[i – 1]):生成一个形状为 (layers_dims[i], layers_dims[i – 1])的随机数矩阵,服从标准正态分布(均值为0,方差为1),layers_dims[i]表示第i层的神经元数量。layers_dims[i – 1]表示第i-1层的神经元数量。np.random.randn(layers_dims[i], layers_dims[i – 1]) * 10:将上面生成的随机数矩阵中的值都乘以10。这样做的目的是将权重矩阵的初始值放大10倍,以增加模型的表达能力。parameters[‘W’ + str(i)] = np.random.randn(layers_dims[i], layers_dims[i – 1]) * 10:将生成的随机数矩阵赋值给对应的权重矩阵W。parameters[‘W’ + str(i)]表示第i层的权重参数矩阵W。
33、parameters[‘W’ + str(i)] = np.random.randn(layers_dims[i],layers_dims[i – 1]) * np.sqrt(2.0 / layers_dims[i – 1]):np.random.randn(layers_dims[i], layers_dims[i – 1]):生成一个形状为(layers_dims[i], layers_dims[i – 1])的随机数矩阵,服从标准正态分布(均值为0,方差为1)。layers_dims[i]表示第i层的神经元数量。
layers_dims[i – 1]表示第i-1层的神经元数量。np.random.randn(layers_dims[i], layers_dims[i – 1]) * 10:将上面生成的随机数矩阵中的值都乘以10。这样做的目的是将权重矩阵的初始值放大10倍,以增加模型的表达能力。parameters[‘W’ + str(i)] = np.random.randn(layers_dims[i], layers_dims[i – 1]) * 10:将生成的随机数矩阵赋值给对应的权重矩阵W。parameters[‘W’ + str(i)]表示第i层的权重参数矩阵W。
34、thetaplus = theta + epsilon:将参数theta的每个元素加上一个小的扰动值epsilon,得到thetaplus。thetaplus表示theta的加扰动后的值。
35、thetaminus = theta – epsilon:将参数theta的每个元素减去一个小的扰动值epsilon,得到thetaminus。thetaminus表示theta的减扰动后的值。
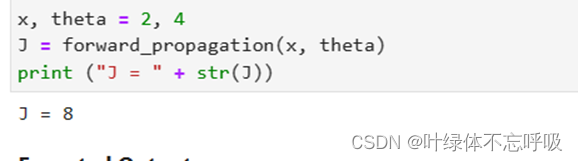
36、Jplus = forward_propagation(x, thetaplus):通过前向传播计算thetaplus对应的代价函数。Jplus表示使用thetaplus计算得到的代价函数值。
37、Jminus = forward_propagation(x, thetaminus):通过前向传播计算thetaminus对应的代价函数。Jminus表示使用thetaminus计算得到的代价函数值。
38、gradapprox = (Jplus – Jminus) / (2 * epsilon):计算数值梯度。gradapprox表示通过数值计算得到的梯度值,使用了代价函数在thetaplus和thetaminus下的差分来近似计算梯度。
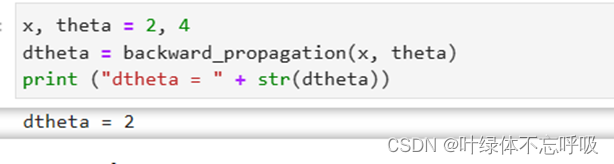
39、grad = backward_propagation(x, theta):使用反向传播计算解析梯度。grad表示使用解析方法计算得到的梯度值。
40、numerator = np.linalg.norm(grad -gradapprox):计算差分梯度和解析梯度之间的范数(欧几里得距离)作为分子。numerator表示差分梯度和解析梯度之间的范数。
41、denominator = np.linalg.norm(grad) + np.linalg.norm(gradapprox):计算解析梯度和差分梯度的范数之和作为分母。denominator表示解析梯度和差分梯度的范数之和。
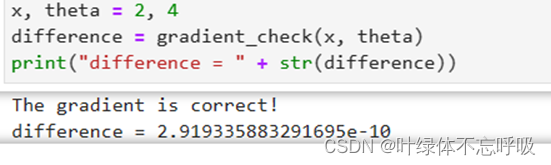
42、difference = numerator / denominator:计算差分梯度和解析梯度之间的差异。difference表示差分梯度和解析梯度之间的差异,即相对误差。
43、mini_batch_X = shuffled_X[:, k * mini_batch_size : (k + 1) * mini_batch_size]
44、mini_batch_Y = shuffled_Y[:, k * mini_batch_size : (k + 1) * mini_batch_size]:mini_batch_X和mini_batch_Y分别表示当前的 mini-batch 对应的输入和输出数据,shuffled_X和shuffled_Y是经过打乱顺序后的输入数据和输出数据。在生成 mini-batches 的过程中,通过k * mini_batch_size和(k + 1) * mini_batch_size计算出当前mini-batch的起始和终止位置,然后从shuffled_X和shuffled_Y中分别取出对应部分作为当前的 mini-batch 数据。
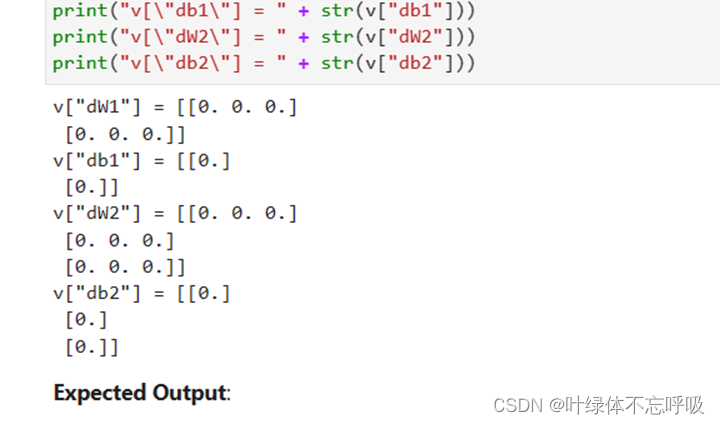
45、v[‘dW’ + str(i + 1)] = np.zeros(parameters[“W” + str(i + 1)].shape):初始化权重矩阵W的速度为零矩阵。v[‘dW’ + str(i + 1)]表示第i+1层的权重矩阵W的速度。np.zeros(parameters[“W” + str(i + 1)].shape)创建了一个与参数W相同形状的全零矩阵。初始化权重矩阵W的速度为零矩阵。v[‘dW’ + str(i + 1)]表示第i+1层的权重矩阵W的速度。np.zeros(parameters[“W” + str(i + 1)].shape)创建了一个与参数W相同形状的全零矩阵。
46、v[‘db’ + str(i + 1)] = np.zeros(parameters[“b” + str(i + 1)].shape):初始化偏置向量b的速度为零矩阵。v[‘db’ + str(i + 1)]表示第i+1层的偏置向量b的速度。
np.zeros(parameters[“b” + str(i + 1)].shape)创建了一个与参数b相同形状的全零矩阵。
四、 运行结果
regularization
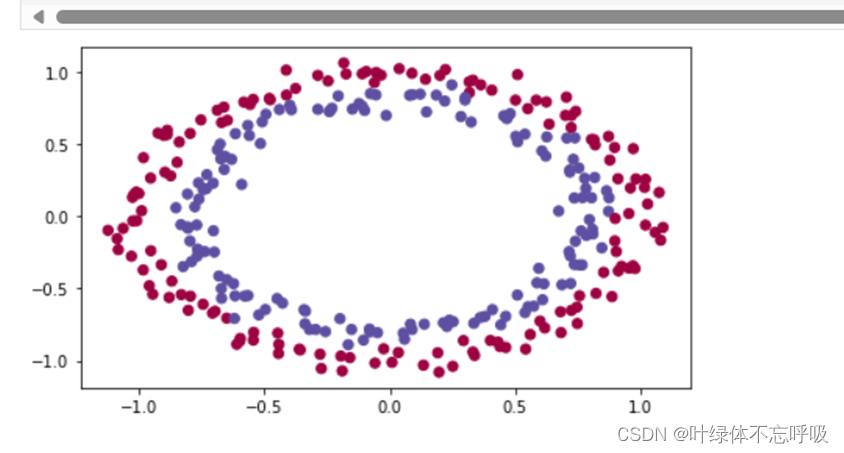
1、加载数据集load_2D_dataset
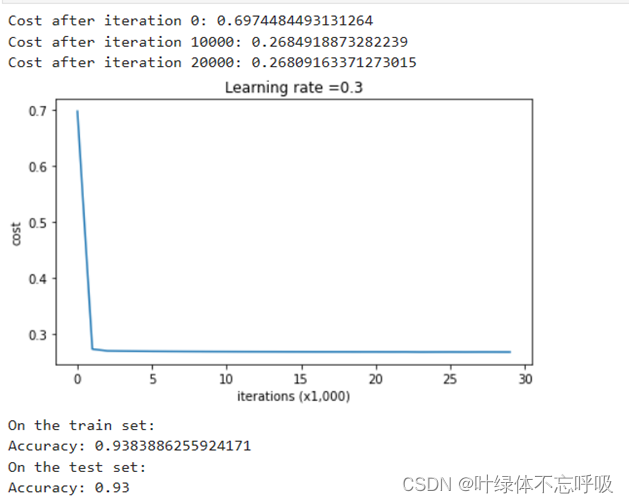
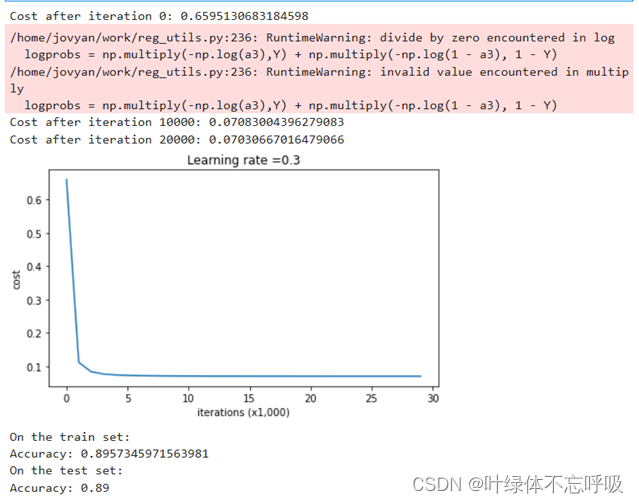
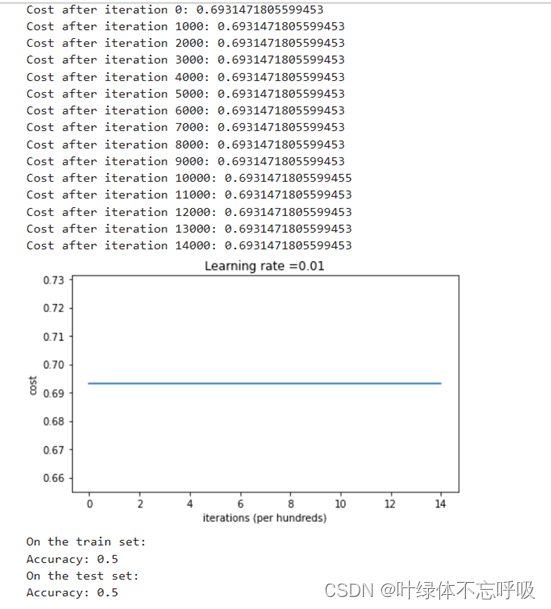
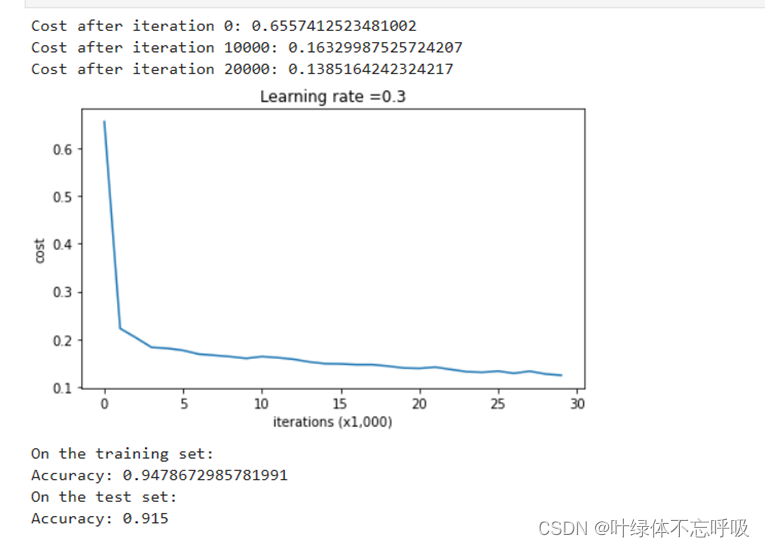
2、无正则化的模型迭代结果以及绘制的代价函数曲线图
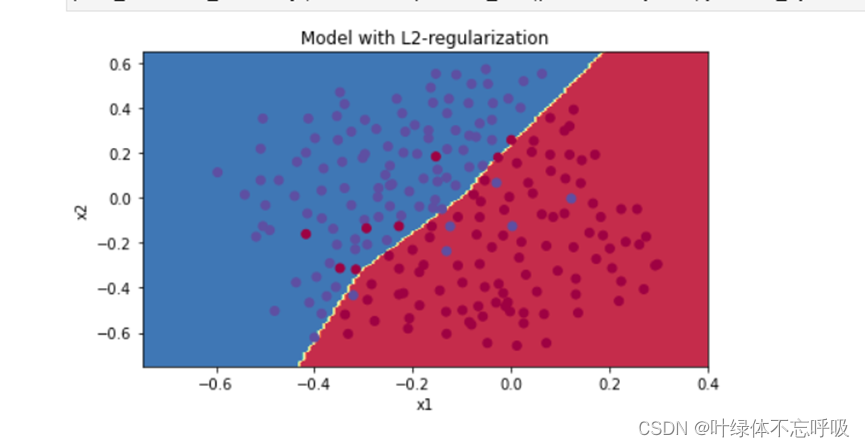
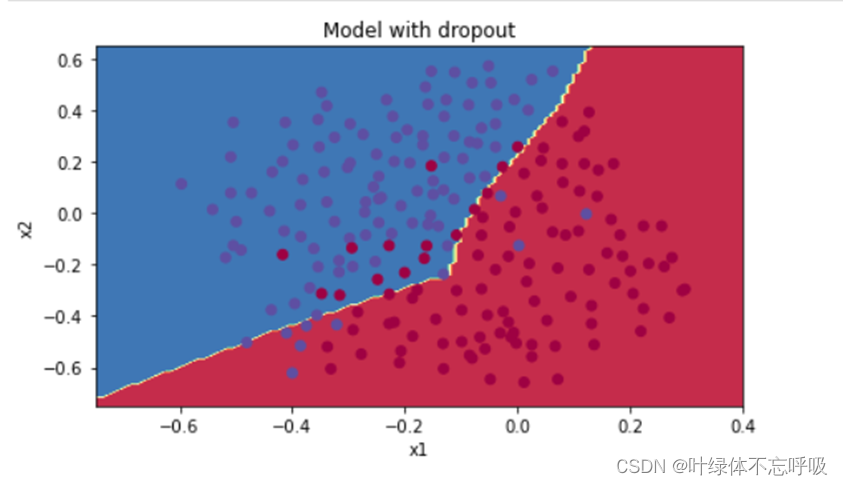
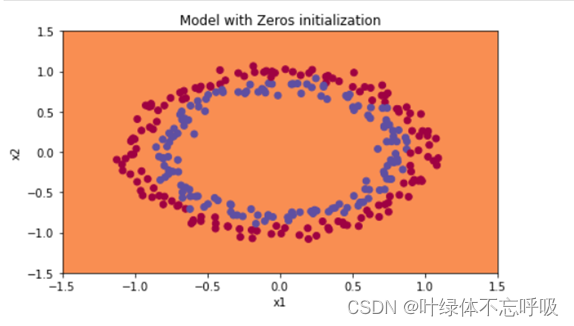
3、无正则化的模型绘制的决策边界
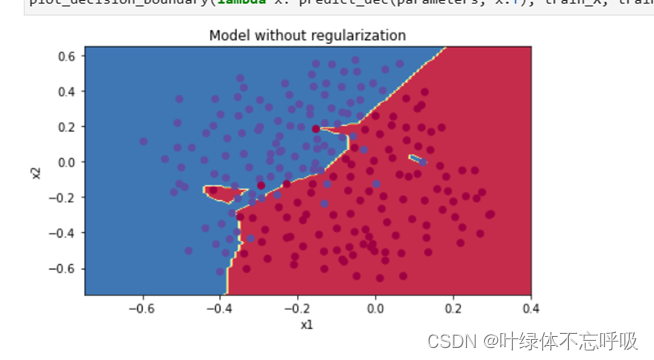
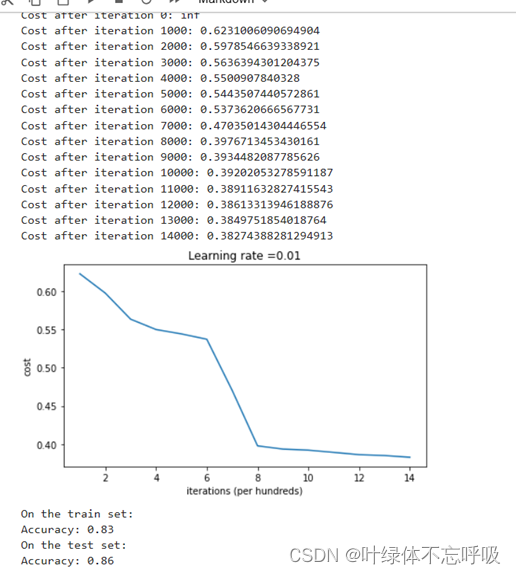
4、L2正则化模型的输出代价函数值

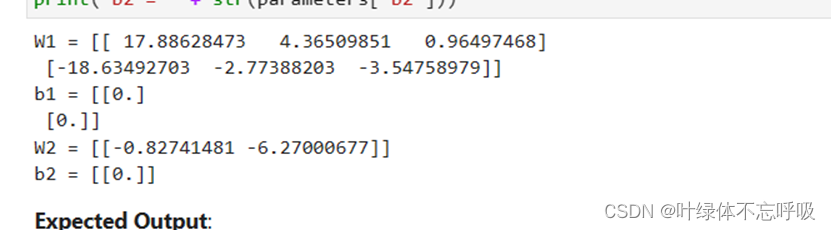
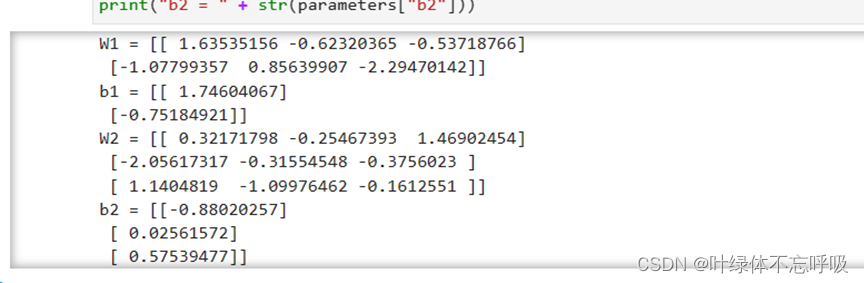
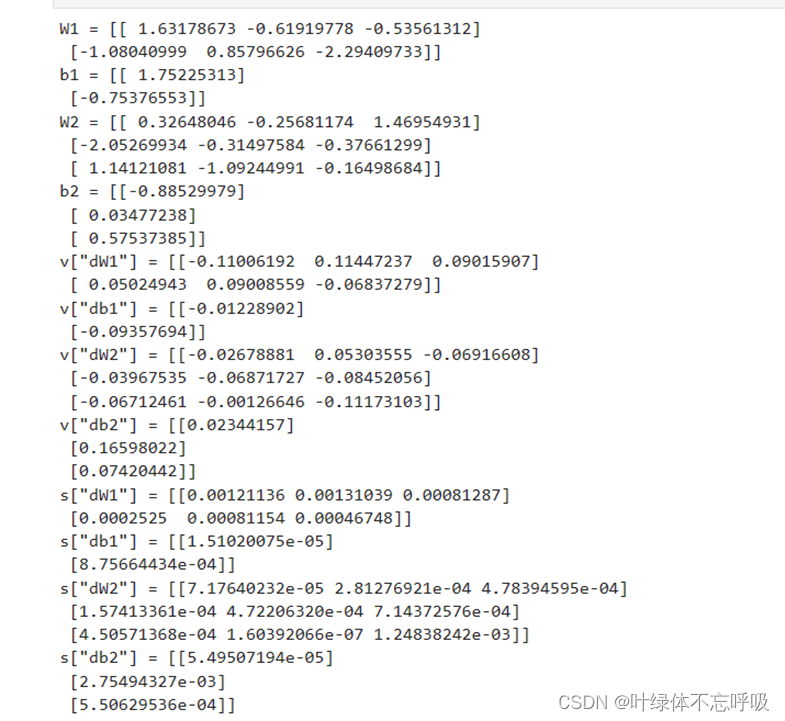
5、带有L2正则化模型反向传播结果