本文介绍: 主要讲解Hive的基础知识:Hive的数据类型、Hive的运算符、Hive的存储路径、Hive的表存储格式。
hive的基础部分大致有四部分:Hive数据类型、Hive运算符、Hive数据存储、Hive表存储格式。这四部分是学习hive必须掌握的知识。
一、Hive数据类型
整体概述
1,hive的数据类型指的是表中列字段类型,类似于编程语言中对变量类型的定义如:浮点型、整型、布尔型等等。
2,hive的数据类型分为两大类:基本数据类型和复杂数据类型。
基本数据类型包括:数值类型、布尔类型、字符串类型、时间日期类型。
复杂数据类型包括:Array数组、Map映射、Struct结构体。
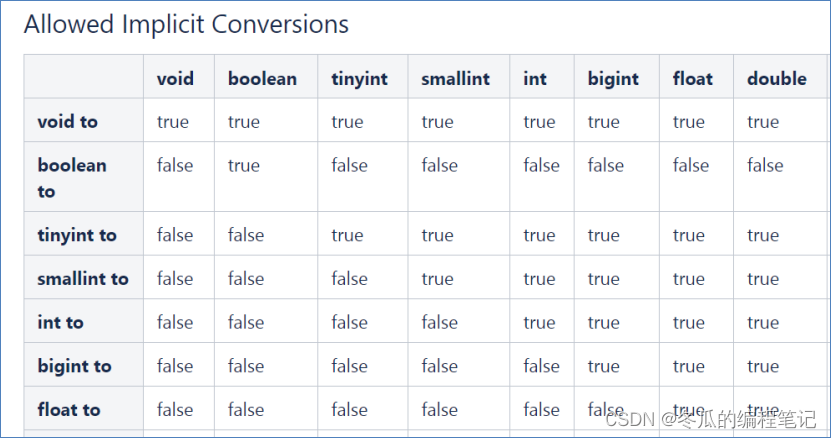
基本数据类型
2字节、4字节、8字节的有符号整数的取值范围:https://blog.csdn.net/m0_48011056/article/details/125153980
复杂数据类型
二、Hive运算符
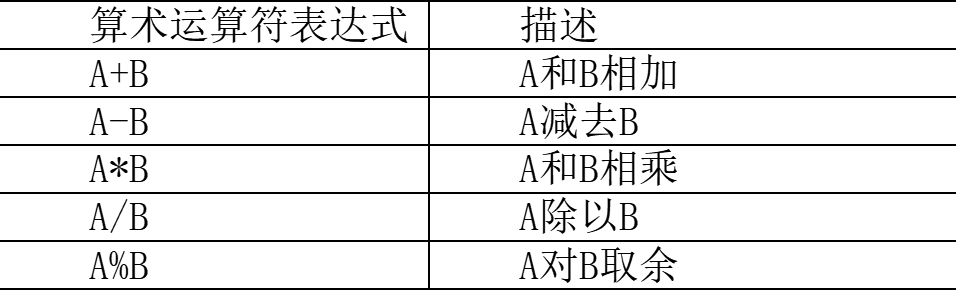
算数运算符:
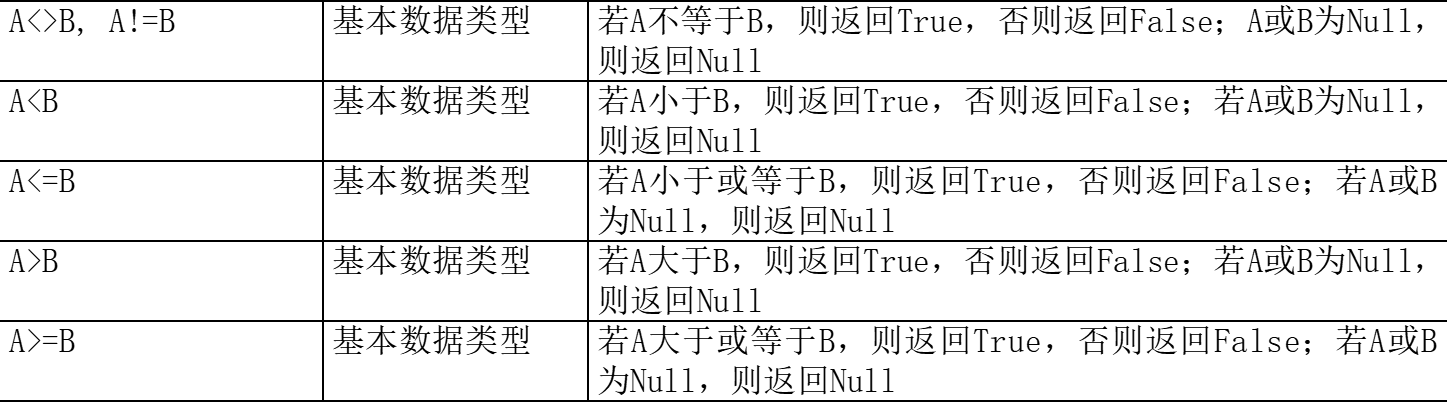
比较运算符:


逻辑运算符:

复杂运算符:

三、Hive存储路径
默认存储路径
Databases 数据库
数据模型概念

四、Hive表存储格式

文件格式-TextFile

文件格式-SequenceFile

文件格式-Parquet

文件格式-ORC

声明:本站所有文章,如无特殊说明或标注,均为本站原创发布。任何个人或组织,在未征得本站同意时,禁止复制、盗用、采集、发布本站内容到任何网站、书籍等各类媒体平台。如若本站内容侵犯了原著者的合法权益,可联系我们进行处理。