本文介绍: Q-learning是一种强化学习算法,用于解决基于马尔可夫决策过程(MDP)的问题。它通过学习一个价值函数来指导智能体在环境中做出决策,以最大化累积奖励。Q-learning算法的核心思想是通过不断更新一个称为Q值的表格来学习最优策略。Q值表示在给定状态下采取某个动作所能获得的预期累积奖励。算法的基本步骤如下:1. 初始化Q值表格,将所有Q值初始化为0。2. 在每个时间步骤t,智能体观察当前状态st,并根据当前Q值表格选择一个动作at。
一、Q-learning简介
Q-learning是一种强化学习算法,用于解决基于马尔可夫决策过程(MDP)的问题。它通过学习一个价值函数来指导智能体在环境中做出决策,以最大化累积奖励。
Q-learning算法的核心思想是通过不断更新一个称为Q值的表格来学习最优策略。Q值表示在给定状态下采取某个动作所能获得的预期累积奖励。算法的基本步骤如下:
1. 初始化Q值表格,将所有Q值初始化为0。
2. 在每个时间步骤t,智能体观察当前状态st,并根据当前Q值表格选择一个动作at。选择动作的方法可以是ε-greedy策略,即以ε的概率随机选择一个动作,以1-ε的概率选择当前Q值最大的动作。
3. 执行动作at,观察环境反馈的奖励rt+1和下一个状态st+1。
4. 根据Q-learning更新规则更新Q值表格中的Q值:
二、无人机物流路径规划
三、Q-learning求解无人机物流路径规划
1、部分代码
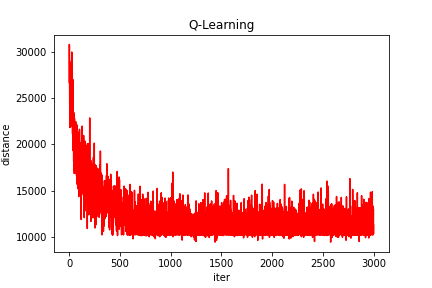
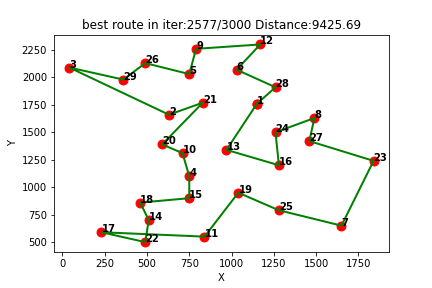
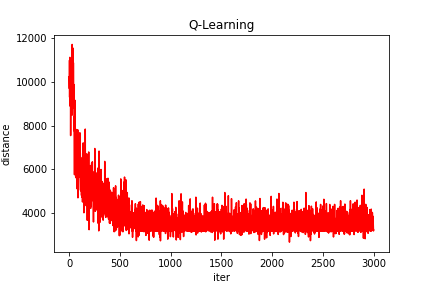
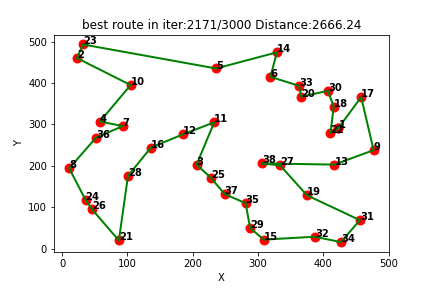
2、部分结果
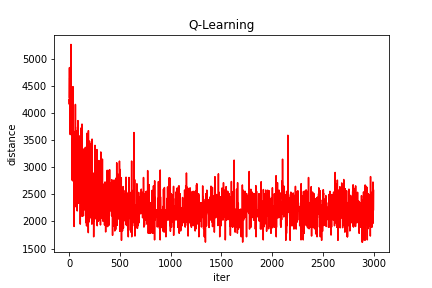
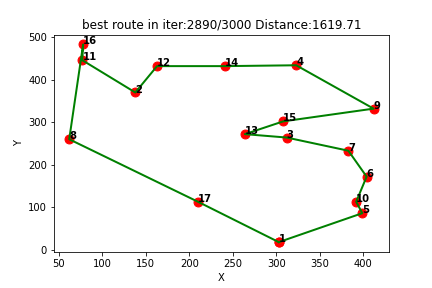
四、完整Python代码
声明:本站所有文章,如无特殊说明或标注,均为本站原创发布。任何个人或组织,在未征得本站同意时,禁止复制、盗用、采集、发布本站内容到任何网站、书籍等各类媒体平台。如若本站内容侵犯了原著者的合法权益,可联系我们进行处理。






