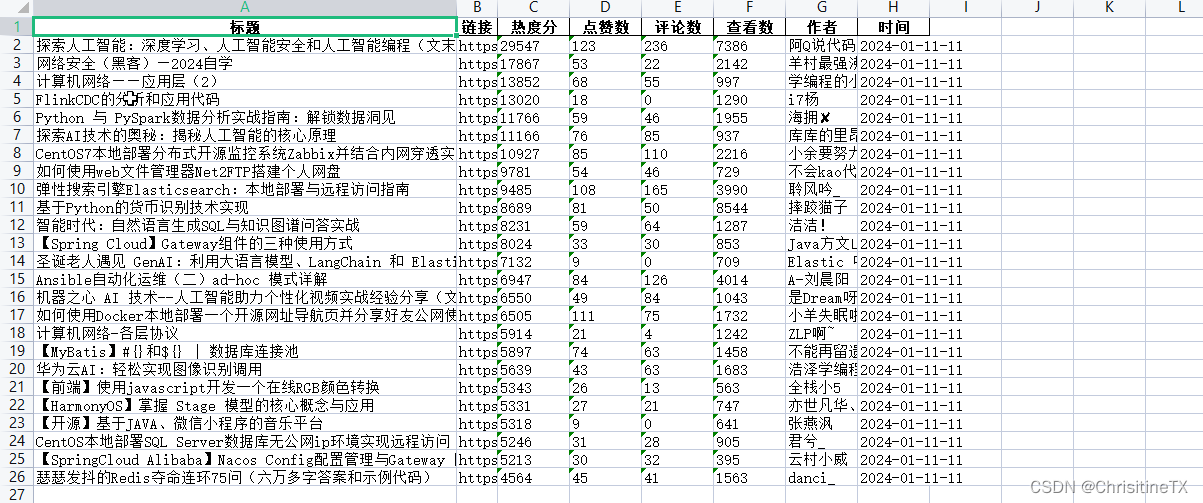
当前位置: 首页python正文 本文介绍: 通过分析,本站的热榜数据可以直接通过接口拿到,故不需要解析标签,请求热榜数据接口。直接请求解析会有点问题,数据无法解析,加上请求头。 1. 需要的类库 import requests import pandas as pd 2. 分析 通过分析,本站的热榜数据可以直接通过接口拿到,故不需要解析标签,请求热榜数据接口 url = "https://xxxt/xxxx/web/blog/hot-rank?page=0&pageSize=25&type=" #本站地址 直接请求解析会有点问题,数据无法解析,加上请求头 headers = { "Accept": "*/*", "Accept-Encoding": "gzip, deflate, br", "Accept-Language": "zh-CN,zh;q=0.9", "Sec-Ch-Ua": ""Chromium";v="116", "Not)A;Brand";v="24", "Google Chrome";v="116"", "Sec-Ch-Ua-Mobile": "?1", "Sec-Ch-Ua-Platform": ""Android"", "Sec-Fetch-Dest": "empty", "Sec-Fetch-Mode": "cors", "Sec-Fetch-Site": "same-site", "User-Agent": "Mozilla/5.0 (Linux; Android 6.0; Nexus 5 Build/MRA58N) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/116.0.0.0 Mobile Safari/537.36" } 完整请求代码 # 发送HTTP请求 r = requests.get(url, headers=headers) # 解析JSON数据 data = r.json() # 提取所需信息 articles = [] for item in data["data"]: title = item["articleTitle"] link = item["articleDetailUrl"] rank = item["hotRankScore"] likes = item["favorCount"] comments = item["commentCount"] views = item["viewCount"] author = item["nickName"] time = item["period"] articles.append({ "标题": title, "链接": link, "热度分": rank, "点赞数": likes, "评论数": comments, "查看数": views, "作者": author, "时间": time }) 3.导出Excel # 创建DataFrame df = pd.DataFrame(articles) # 将DataFrame保存为Excel文件 df.to_excel("csdn_top.xlsx", index=False) 4. 成果展示 原文地址:https://blog.csdn.net/qq_34252622/article/details/135524892 本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若转载,请注明出处:http://www.7code.cn/show_55506.html 如若内容造成侵权/违法违规/事实不符,请联系代码007邮箱:suwngjj01@126.com进行投诉反馈,一经查实,立即删除! 主题授权提示:请在后台主题设置-主题授权-激活主题的正版授权,授权购买:RiTheme官网显示所有内容声明:本站所有文章,如无特殊说明或标注,均为本站原创发布。任何个人或组织,在未征得本站同意时,禁止复制、盗用、采集、发布本站内容到任何网站、书籍等各类媒体平台。如若本站内容侵犯了原著者的合法权益,可联系我们进行处理。热榜解析请求 代码007普通 打赏 收藏 海报 链接
![[设计模式Java实现附plantuml源码~行为型]请求的链式处理——职责链模式](https://img-blog.csdnimg.cn/direct/699aac3ed0c446d088772a0ed4c444ed.png)