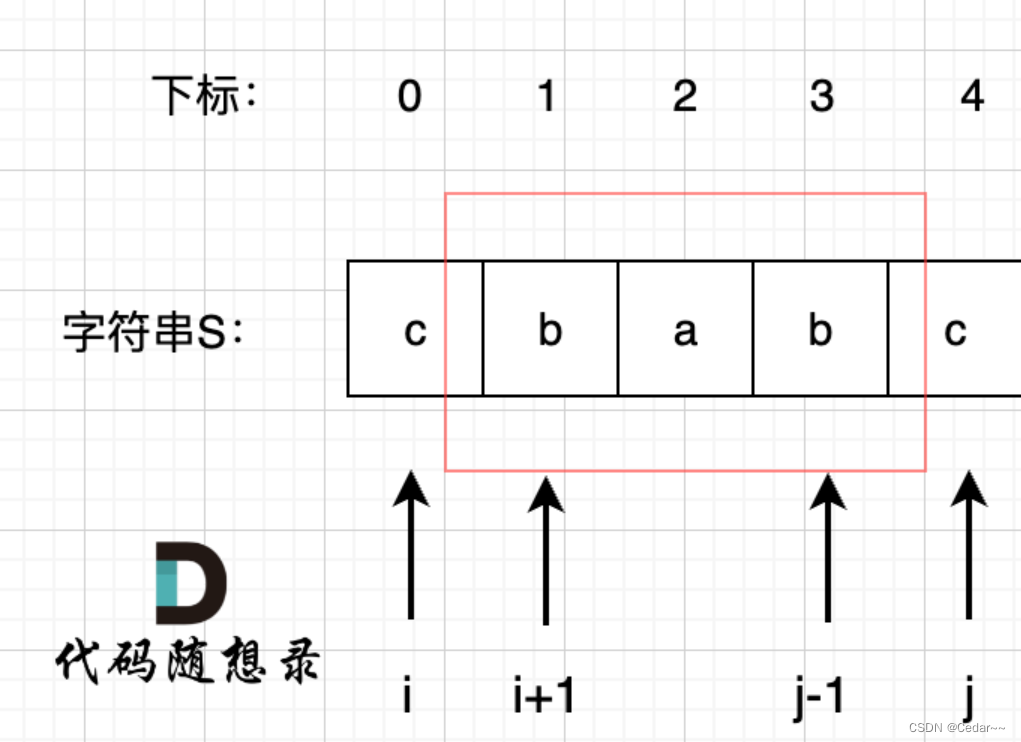
本文介绍: 1. 初始化变量:`max` 用于存储最长子串的长度,`index` 用于跟踪重复字符的索引,空字符串 `str` 用于存储当前子串。4. 如果找到重复的字符,通过比较当前子串 `str` 的长度和当前最大长度 `max` 来更新 `max` 长度。rk不用更新回去,因为从i到rk是不重复的,那从i+1到rk也肯定是不重复的,所以rk不用更新回去,set集合也不用清空。7. 循环结束后,比较最终子串 `str` 的长度和当前最大长度 `max`,以确保最后一个子串也被考虑在内。击败百分之5%的对手。
题目
示例
示例 1:
示例 2:
示例 3:
思想(滑动窗口)
算法分析
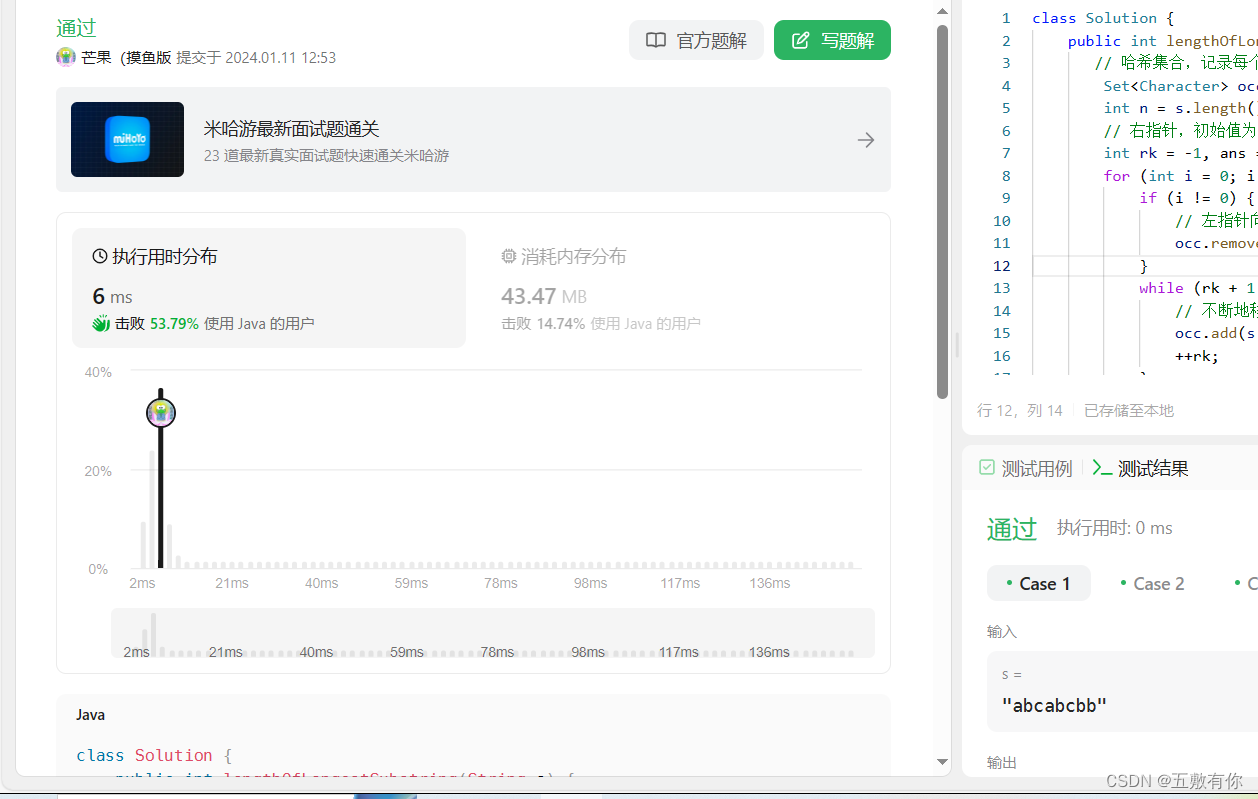
运行结果
总的时间复杂度为 O(n)
击败百分之5%的对手。。。emmm被我击败南坪
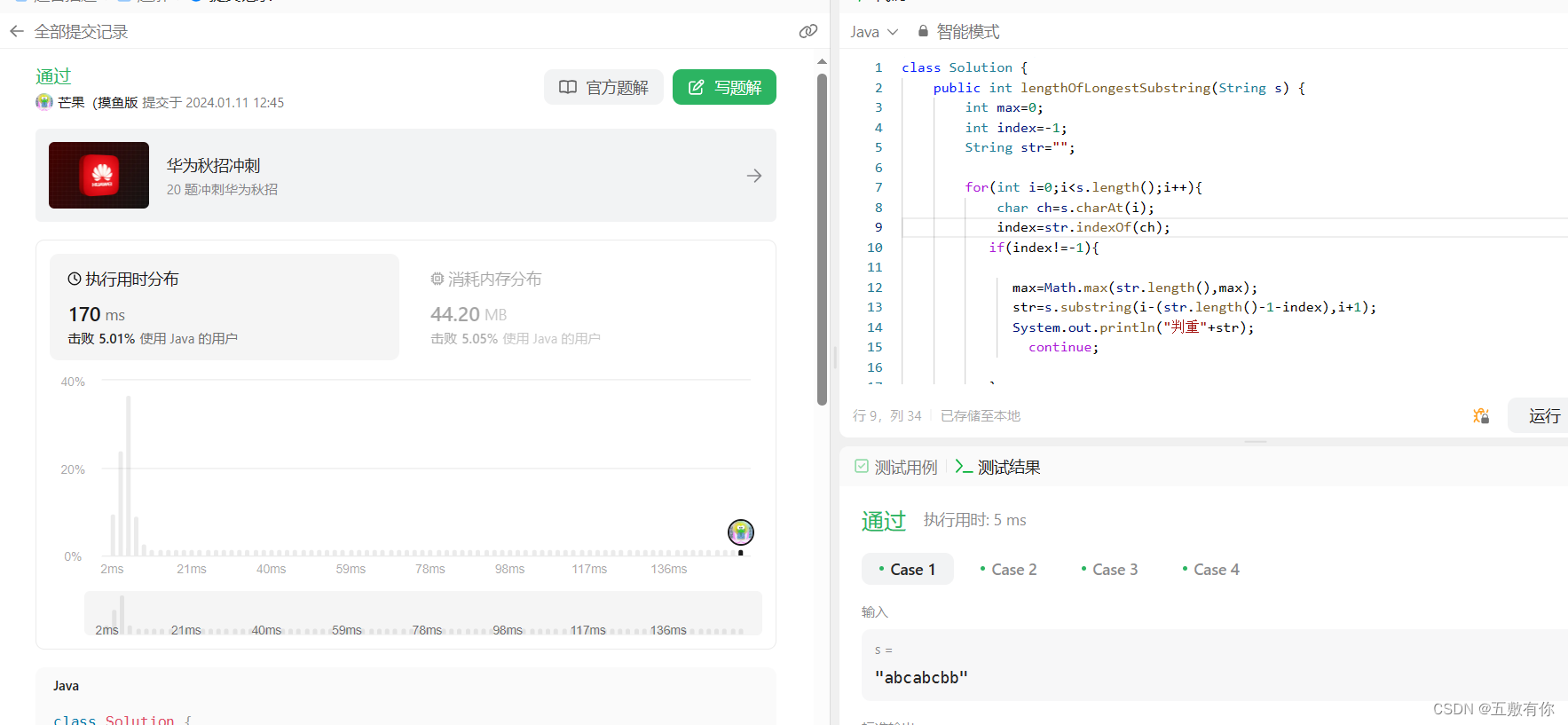
算法调优
声明:本站所有文章,如无特殊说明或标注,均为本站原创发布。任何个人或组织,在未征得本站同意时,禁止复制、盗用、采集、发布本站内容到任何网站、书籍等各类媒体平台。如若本站内容侵犯了原著者的合法权益,可联系我们进行处理。