本文介绍: 所以整个方法就是,encoder在ImageNet-21k上预训练,然后冻结encoder参数,再在ImageNet-21k预训练decoder参数,不需要使用标签。前面提到的噪声大小的γ,在我们的模型是一个定值,也就是相当于扩散模型的一步,PPDM是一个完全的扩散模型,它每一个训练例子中都从[0,1]中随机均匀选一个γ值。上面这些预训练目标的选择,也就是预测噪声而不是x,和噪声的选择等,和扩散模型很相似,这样自然就会产生一个问题,即如果使用完全的扩散模型预训练,是不是提高性能。也就是预测原始图片x。
分割标签耗时且贵,所以常常使用预训练提高分割模型标签有效性,反正就是,需要一个预训练分割模型。典型的分割模型encoder部分通过分类任务预训练,decoder部分参数随机初始化。作者认为这个方法次优,尤其标签比较少的情况。

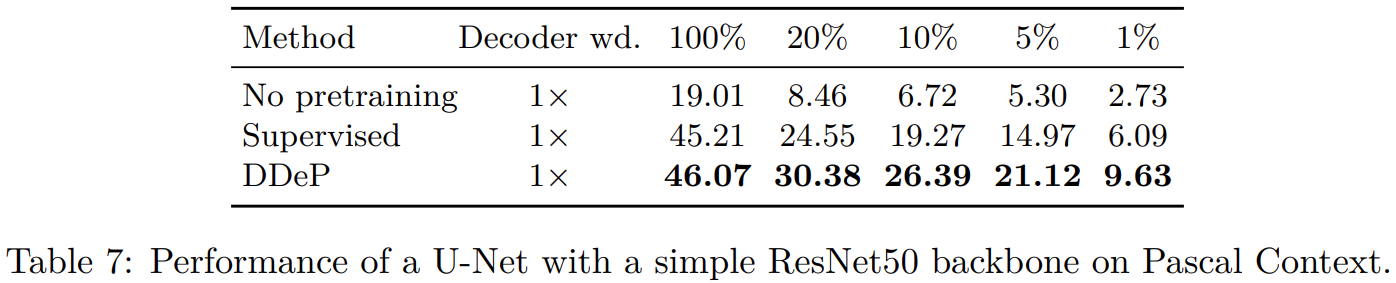
于是提出可以和监督学习encoder结合的基于去噪denoising的decoder预训练方法。当标签少的时候这个方法表现很好,超过监督学习。

所以整个方法就是,encoder在ImageNet-21k上预训练,然后冻结encoder参数,再在ImageNet-21k预训练decoder参数,不需要使用标签。然后在特定数据集上统一微调encoder和decoder。
架构:












声明:本站所有文章,如无特殊说明或标注,均为本站原创发布。任何个人或组织,在未征得本站同意时,禁止复制、盗用、采集、发布本站内容到任何网站、书籍等各类媒体平台。如若本站内容侵犯了原著者的合法权益,可联系我们进行处理。






