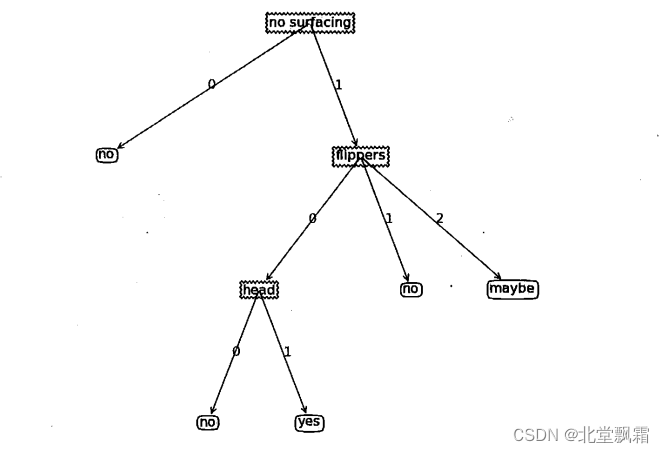
本文介绍: 熵是信息论中的一个核心概念,最初由克劳德·香农提出。它是用来量化信息中的不确定性或混乱度的度量。在信息论中,熵可以理解为传输的信息量或系统的无序程度。我们通过信息增益构建决策树,决策树类似于if else条件流程,我们可以使用python的绘图工具画出来。决策树的范例,如下,我们通过决策树就可以直接得到预测结果。
场景
之前有说过k近邻算法,k近邻算法是根据寻找最相似特征的邻居来解决分类问题。k近邻算法存在的问题是:不支持自我纠错,无法呈现数据格式,且吃性能。k近邻算法的决策过程并不可视化。对缺失数据的样本处理很不友好,而且当处理具有许多特征的高维数据时,K-NN的性能可能会下降。
熵
在了解决策树之前,有必要了解一个熵的概念,这是高数必学的一个东西。
熵(Entropy)的定义
熵是信息论中的一个核心概念,最初由克劳德·香农提出。它是用来量化信息中的不确定性或混乱度的度量。在信息论中,熵可以理解为传输的信息量或系统的无序程度。
举例
抛硬币,硬币有正有反,理论上抛到正面和抛到负面的概率是一样大,我跑了三次硬币,分别是
问:我第四抛硬币的结果是什么?
这不扯淡吗?我怎么会知道?这种情况下的熵是最大的。
拿小球,我一个袋子里有一百个球,其中一个黑球,九十九个白球,问:你会拿到什么球?
我可以直接预测:白球。
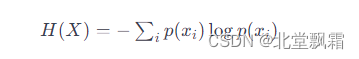
熵和决策树
案例
步骤1:计算数据集的熵
步骤2:特征分割
步骤3:计算信息增益

构建决策树
决策树
和熵关联起来
总结
结束
声明:本站所有文章,如无特殊说明或标注,均为本站原创发布。任何个人或组织,在未征得本站同意时,禁止复制、盗用、采集、发布本站内容到任何网站、书籍等各类媒体平台。如若本站内容侵犯了原著者的合法权益,可联系我们进行处理。




