Java接入Apache Spark(环境搭建、常见问题)
背景介绍
Apache Spark 是一个快速的,通用的集群计算系统。它对 Java,Scala,Python 和 R 提供了的高层 API,并有一个经优化的支持通用执行图计算的引擎。它还支持一组丰富的高级工具,包括用于 SQL 和结构化数据处理的 Spark SQL,用于机器学习的 MLlib,用于图计算的 GraphX 和 Spark Streaming。
Spark 是 MapReduce 的替代方案,而且兼容 HDFS、Hive,可融入 Hadoop 的生态系统,以弥补 MapReduce 的不足。,Spark 基于内存的运算要快 100 倍以上,基于硬盘的运算也要快 10 倍以上。Spark 实现了高效的 DAG 执行引擎,可以通过基于内存来高效处理数据流
Apache Spark官网:https://spark.apache.org/
Apache Spark中文官网:https://spark.apachecn.org/
开发环境
- win11 操作系统
- IntelliJ IDEA 2023.2.5
- jdk1.8 (corretto-1.8.0_392)
资源下载
Hadoop下载
- hadoop下载地址:
https://hadoop.apache.org/releases.html
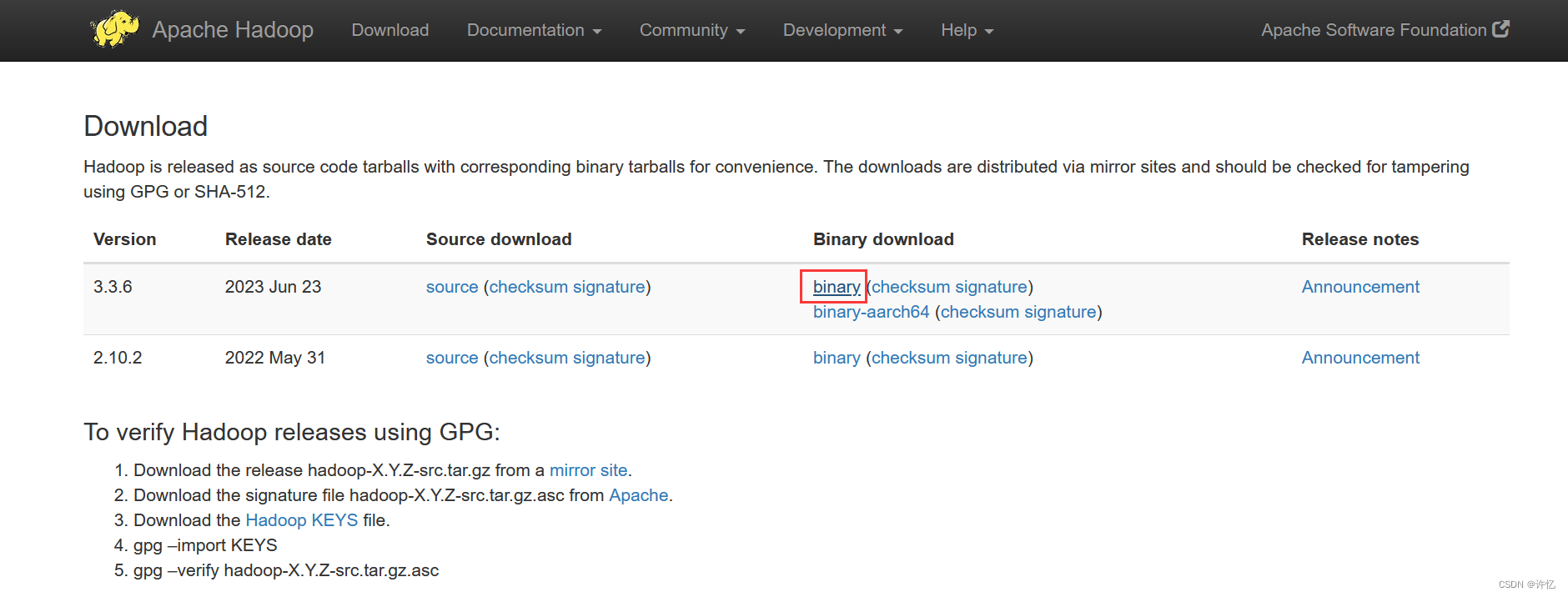
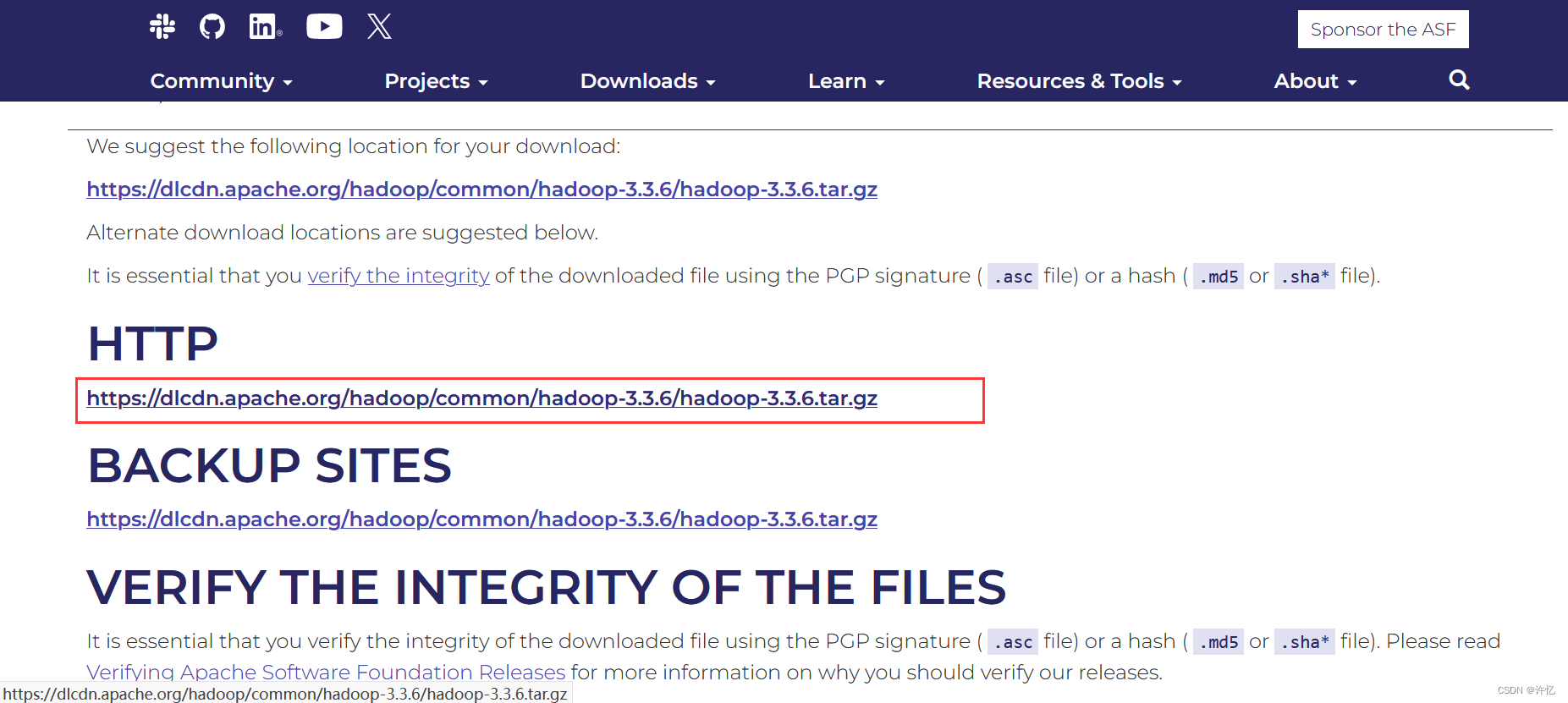 也可以直接进入下载列表,进行下载,我这里使用的是hadoop-3.3.6。下载地址:https://dlcdn.apache.org/hadoop/common/
也可以直接进入下载列表,进行下载,我这里使用的是hadoop-3.3.6。下载地址:https://dlcdn.apache.org/hadoop/common/

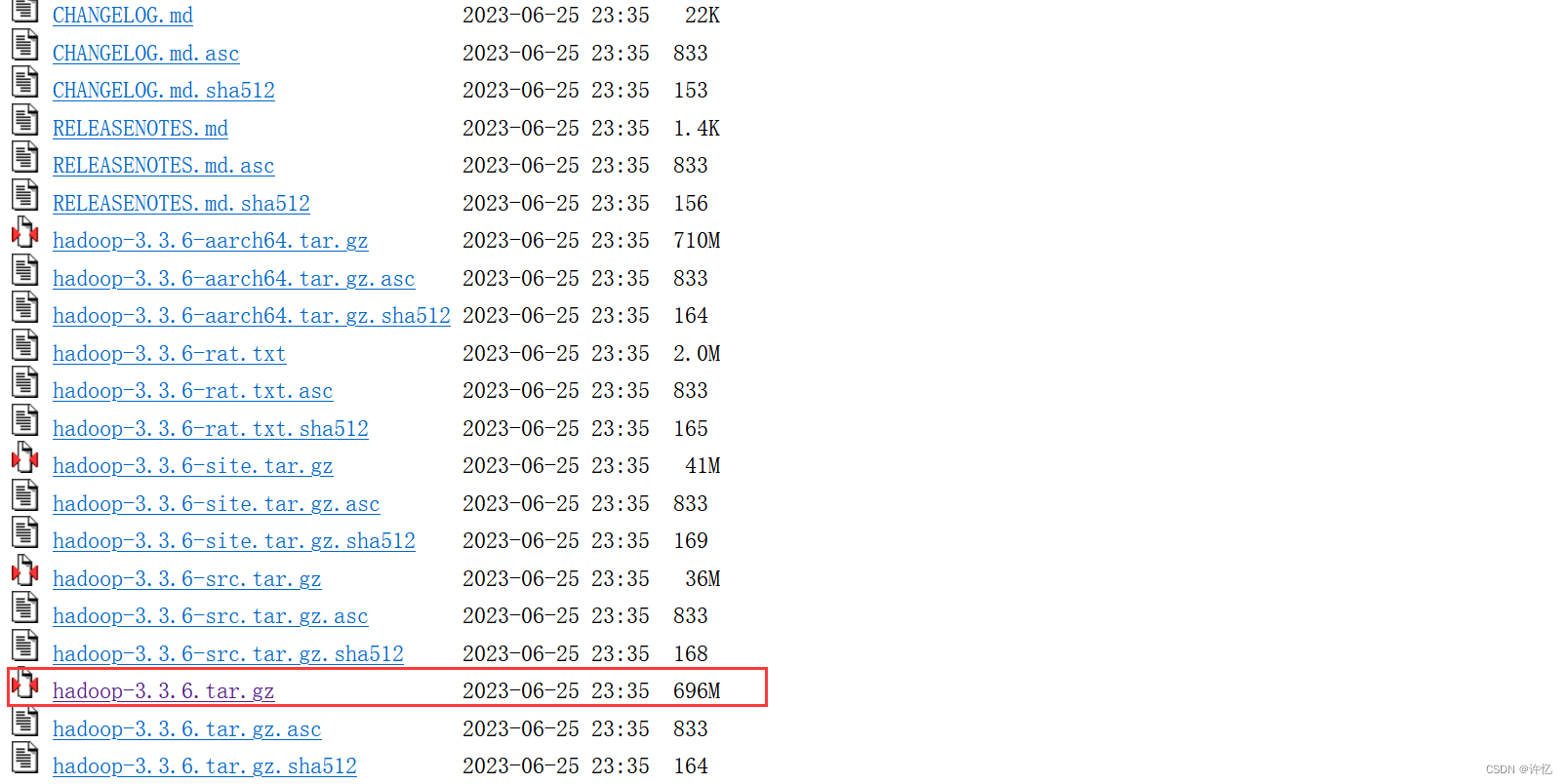
winutils下载
- winutils下载地址:
gitHub:https://github.com/SirMin/winutils/tree/master
下载该目录下的hadoop.dll 和 winutils.exe 文件
或者直接在CSDN下载,【免费】不需要积分。
Hadoop 3.3.6 Windows系统安装包 和 winutils的文件
安装环境
安装Hadoop【别安装在 Program Files这类带空格的文件夹下,因为环境变量找不着!!!】
-
将下载好的hadoop-3.3.6.tar.gz包,放到想要安装的目录,我这里是放在D盘(D:hadoop-3.3.6.tar.gz)
-
解压hadoop-3.3.6.tar.gz文件【注意:需要在cmd中以管理员身份运行】
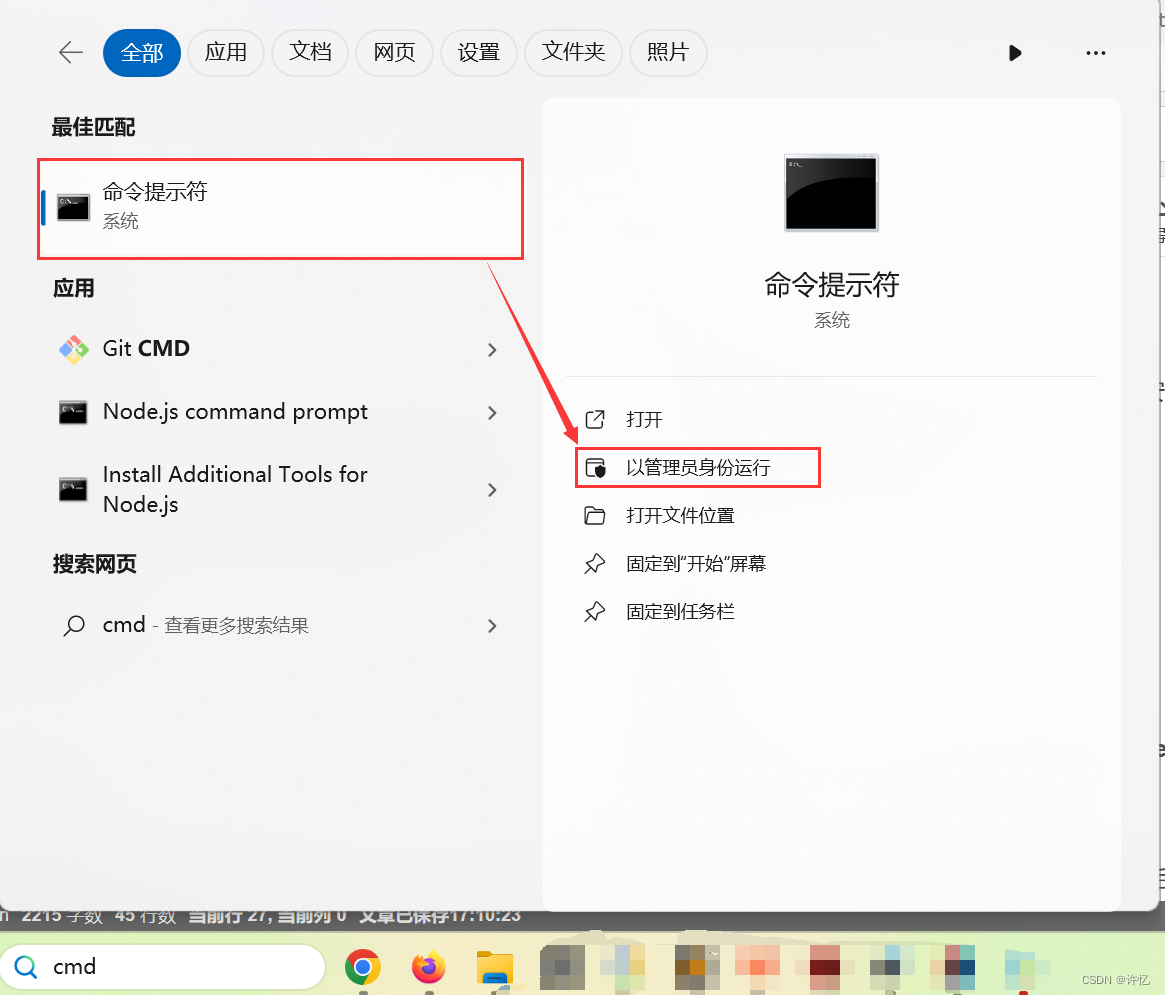
-
进入文件目录
等待执行结束 -
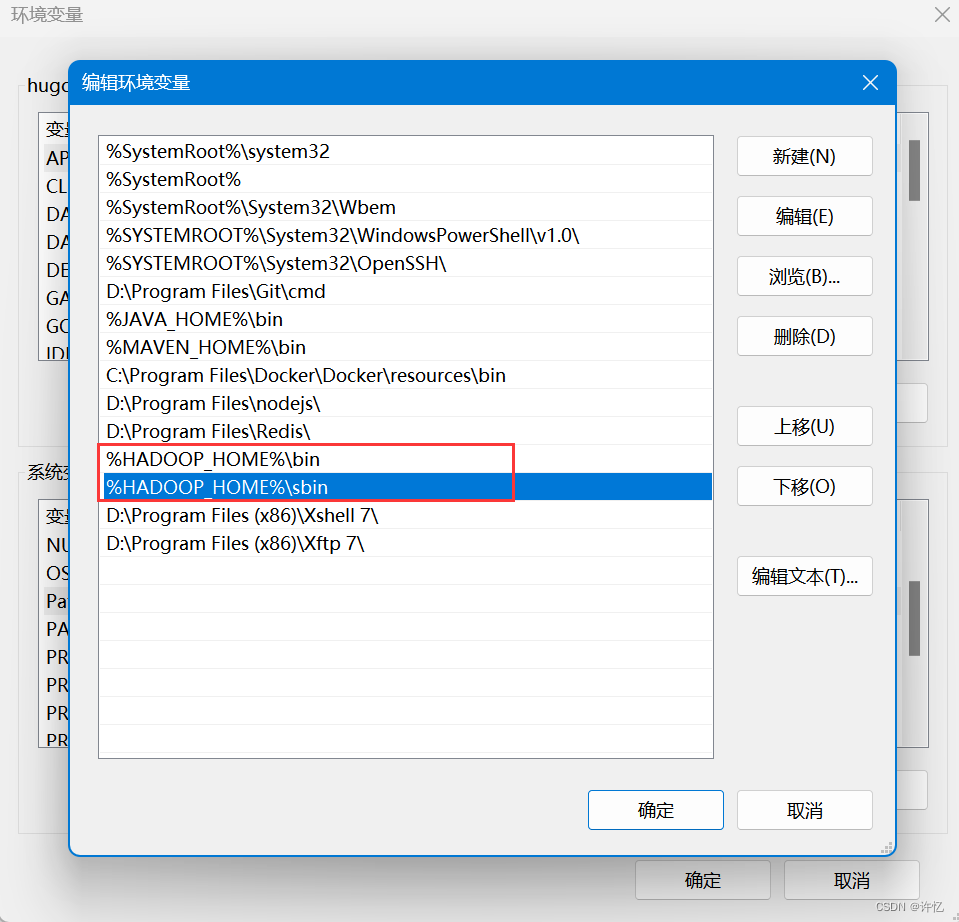
配置HADOOP_HOME环境变量,进入 此电脑 -> 右键 -> 属性 -> 高级系统设置 -> 环境变量
 选择新建,配置变量名 HADOOP_HOME ,变量值为 hadoop的解压路径
选择新建,配置变量名 HADOOP_HOME ,变量值为 hadoop的解压路径
然后在系统变量的path中加入以下两个变量,保存即可。
%HADOOP_HOME%bin
%HADOOP_HOME%sbin
tar zxvf hadoop-3.3.6.tar.gz
解压后路径
D:hadoop-3.3.6
- 配置 Hadoop 环境脚本
在解压后的路径中(D:Program Fileshadoop-3.3.6)找到D:Program Fileshadoop-3.3.6etchadoophadoop-env.cmd脚本,配置JDK的JAVA_HOME真实路径。
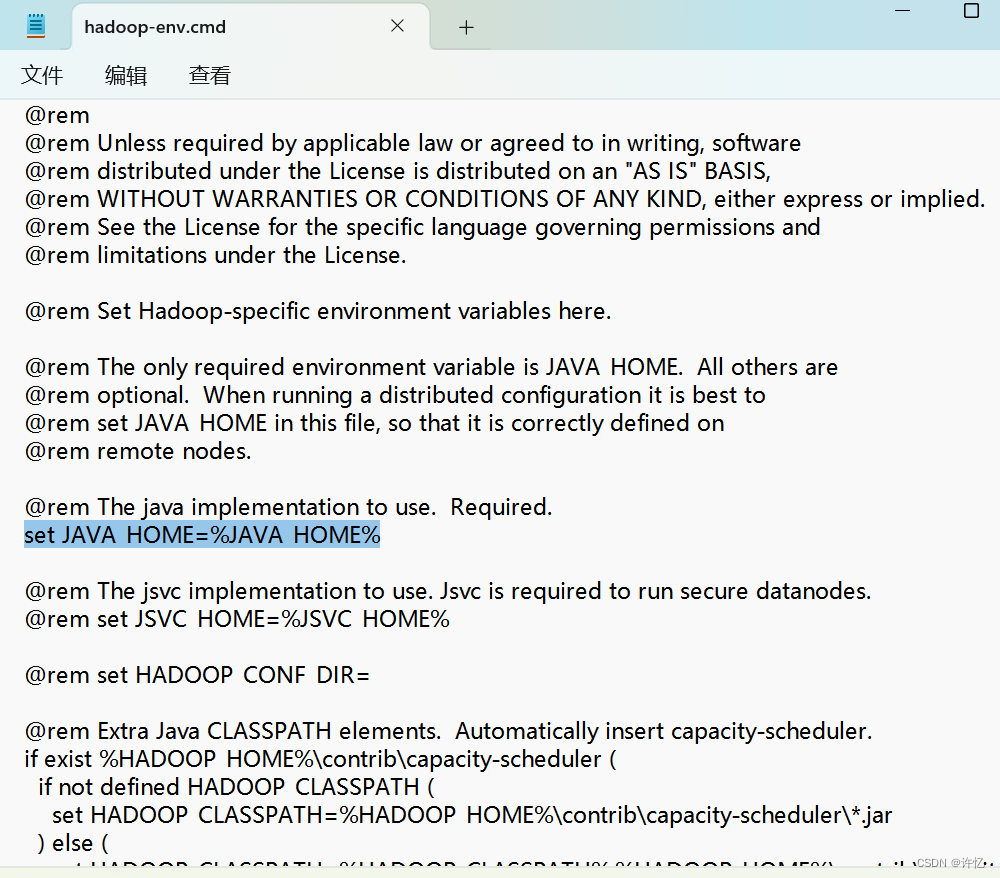
## 替换前
set JAVA_HOME=%JAVA_HOME%
## 替换后
set JAVA_HOME=C:Userscessz.jdkscorretto-1.8.0_392
安装winutils
-
将winutils下载地址里 hadoop.dll 和 winutils.exe 文件拷贝到 C:WindowsSystem32
目录中重启电脑
-
或者将winutils下载地址里的所有文件下载下来放入,hadoop的bin文件夹(D:hadoop-3.3.6bin)
重启IDEA
检查是否安装成功
-
检测环境变量是否配置成功
bash hadoop -version
-
在IDEA中测试
引入依赖
<dependency> <!-- Spark dependency -->
<groupId>org.apache.spark</groupId>
<artifactId>spark-core_2.12</artifactId>
<version>3.5.0</version>
<scope>provided</scope>
</dependency>
<dependency> <!-- Spark dependency -->
<groupId>org.apache.spark</groupId>
<artifactId>spark-sql_2.12</artifactId>
<version>3.5.0</version>
<scope>provided</scope>
</dependency>
编写测试Application
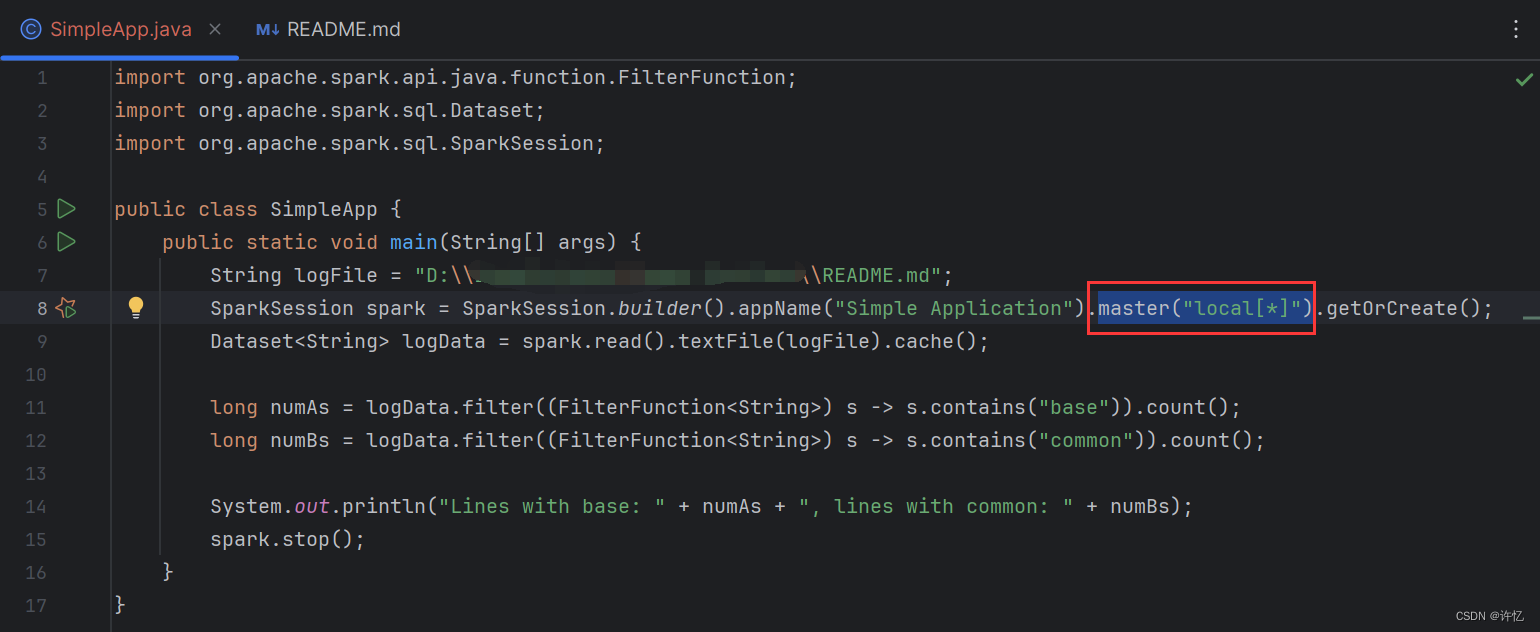
import org.apache.spark.api.java.function.FilterFunction;
import org.apache.spark.sql.Dataset;
import org.apache.spark.sql.SparkSession;
public class SimpleApp {
public static void main(String[] args) {
String logFile = "D:\IdeaProjects\project\README.md";
SparkSession spark = SparkSession.builder().appName("Simple Application").master("local[*]").getOrCreate();
Dataset<String> logData = spark.read().textFile(logFile).cache();
long numAs = logData.filter((FilterFunction<String>) s -> s.contains("base")).count();
long numBs = logData.filter((FilterFunction<String>) s -> s.contains("common")).count();
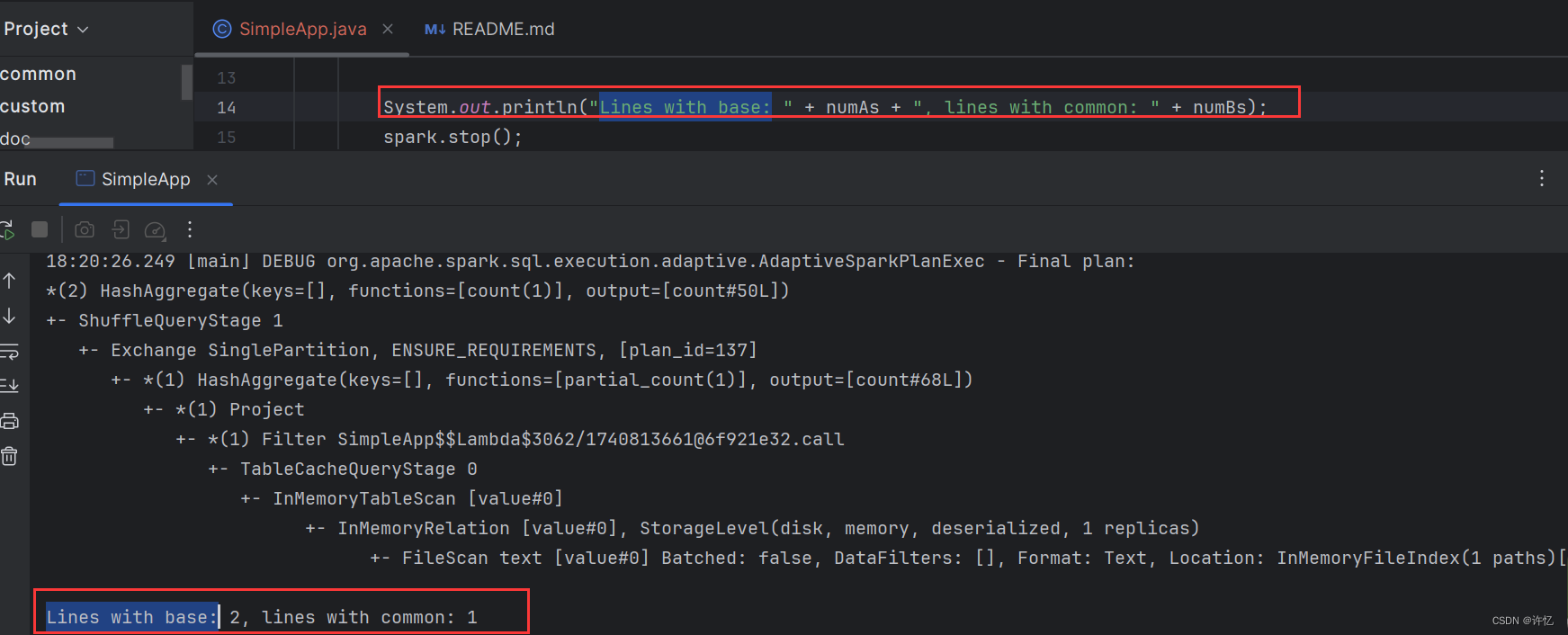
System.out.println("Lines with base: " + numAs + ", lines with common: " + numBs);
spark.stop();
}
}
查看打印读取到的字符数量
常见问题
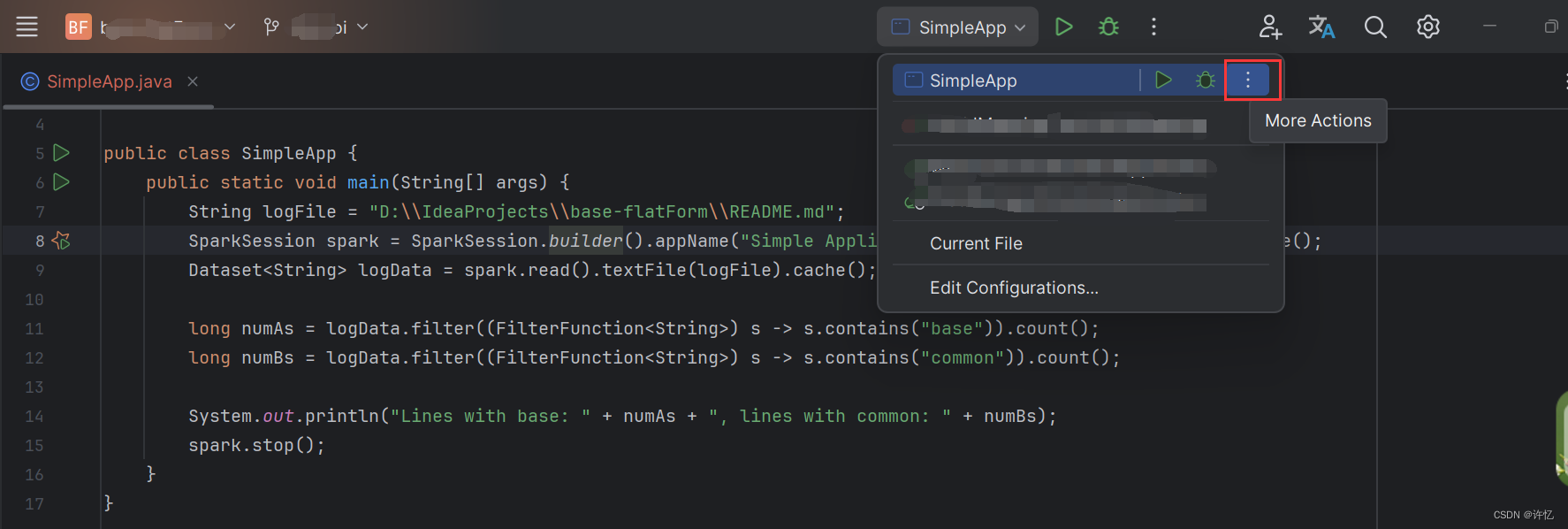
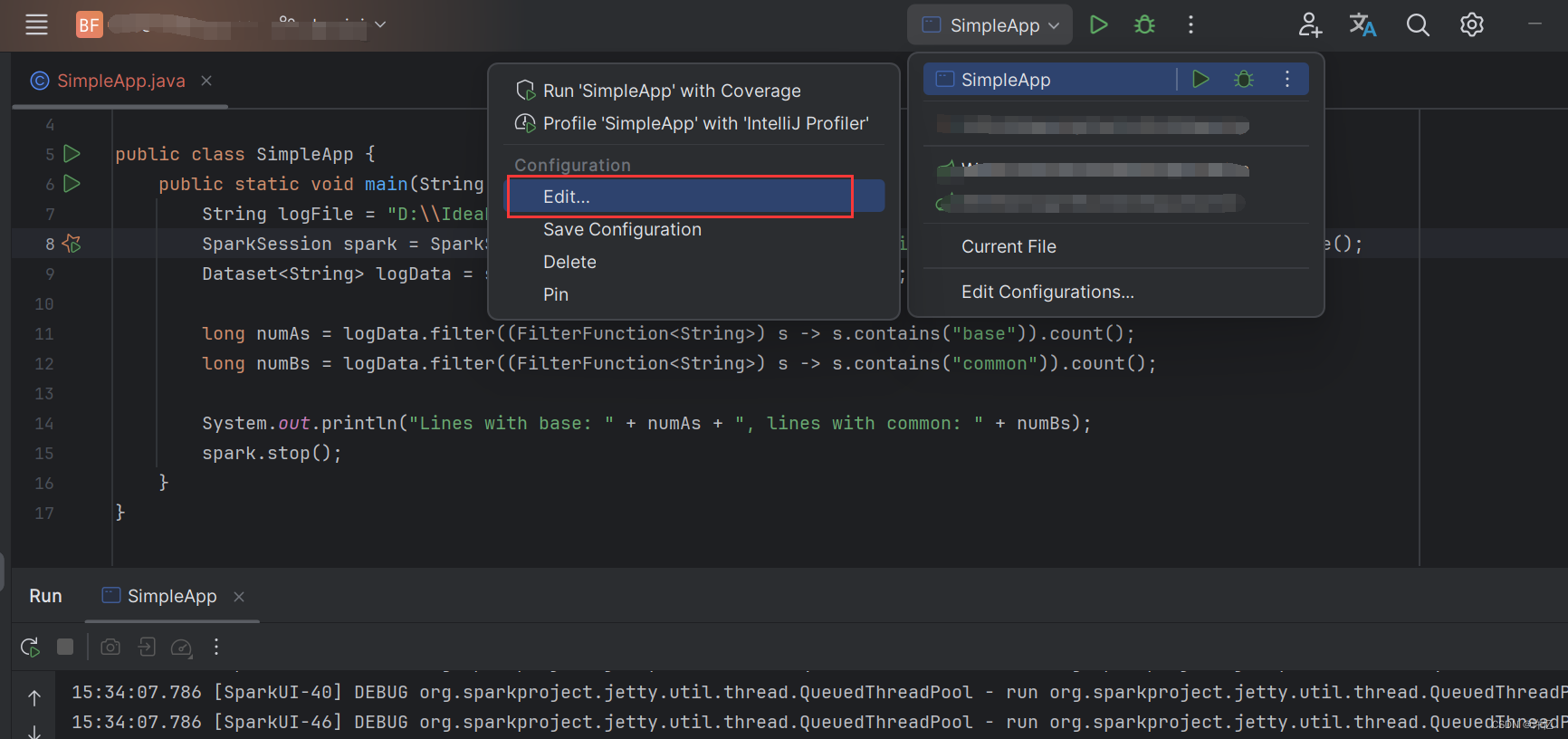
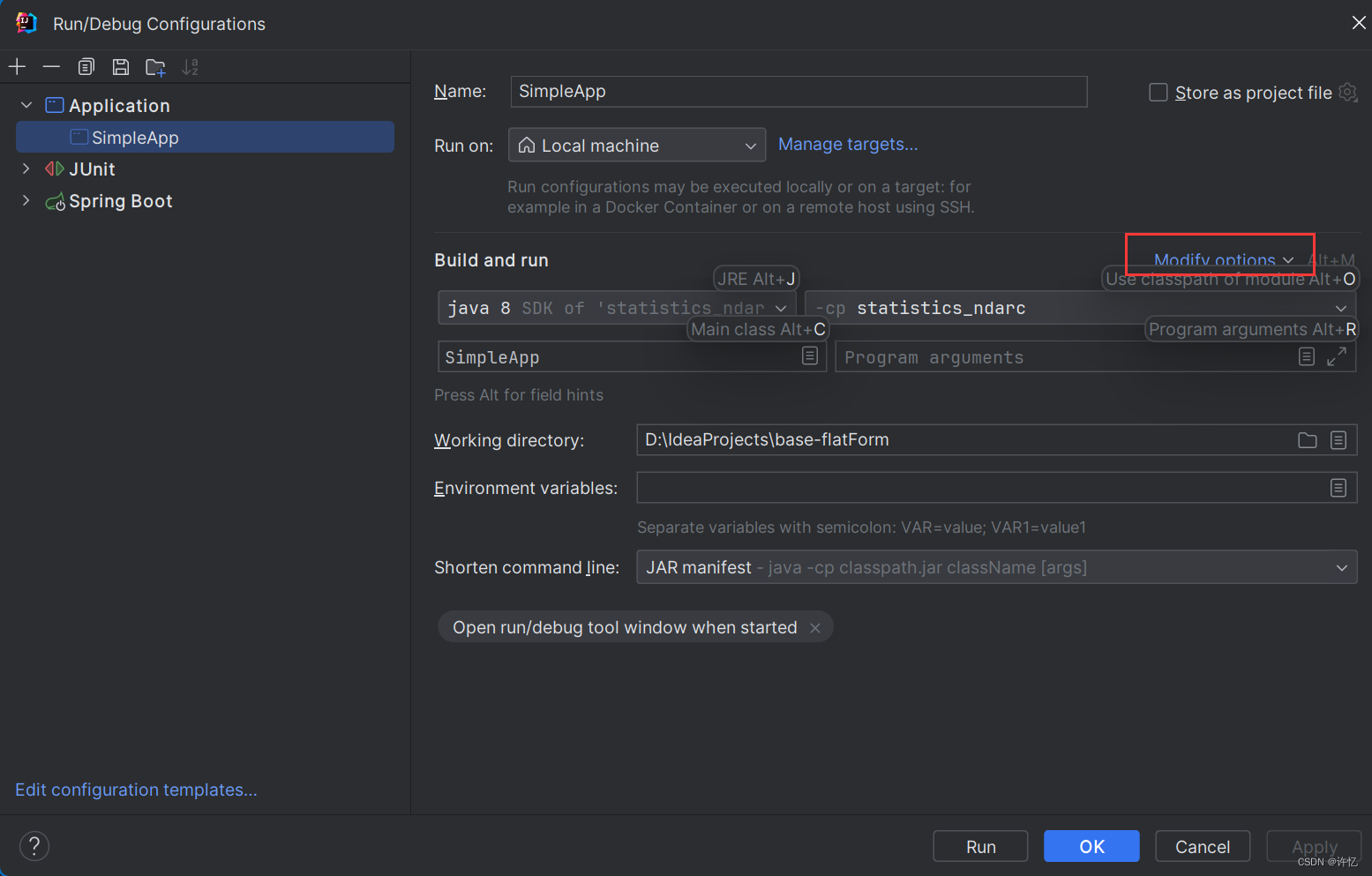
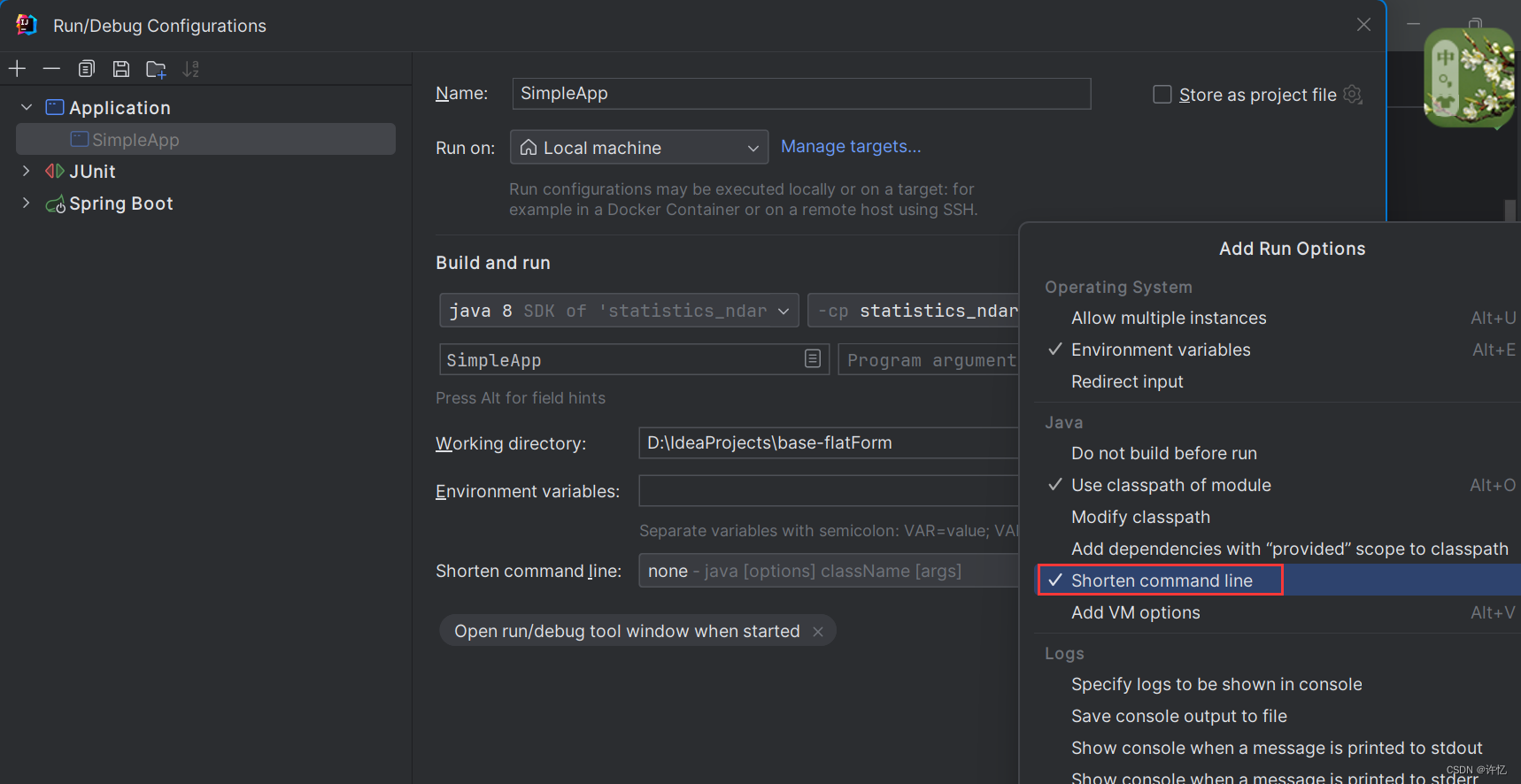
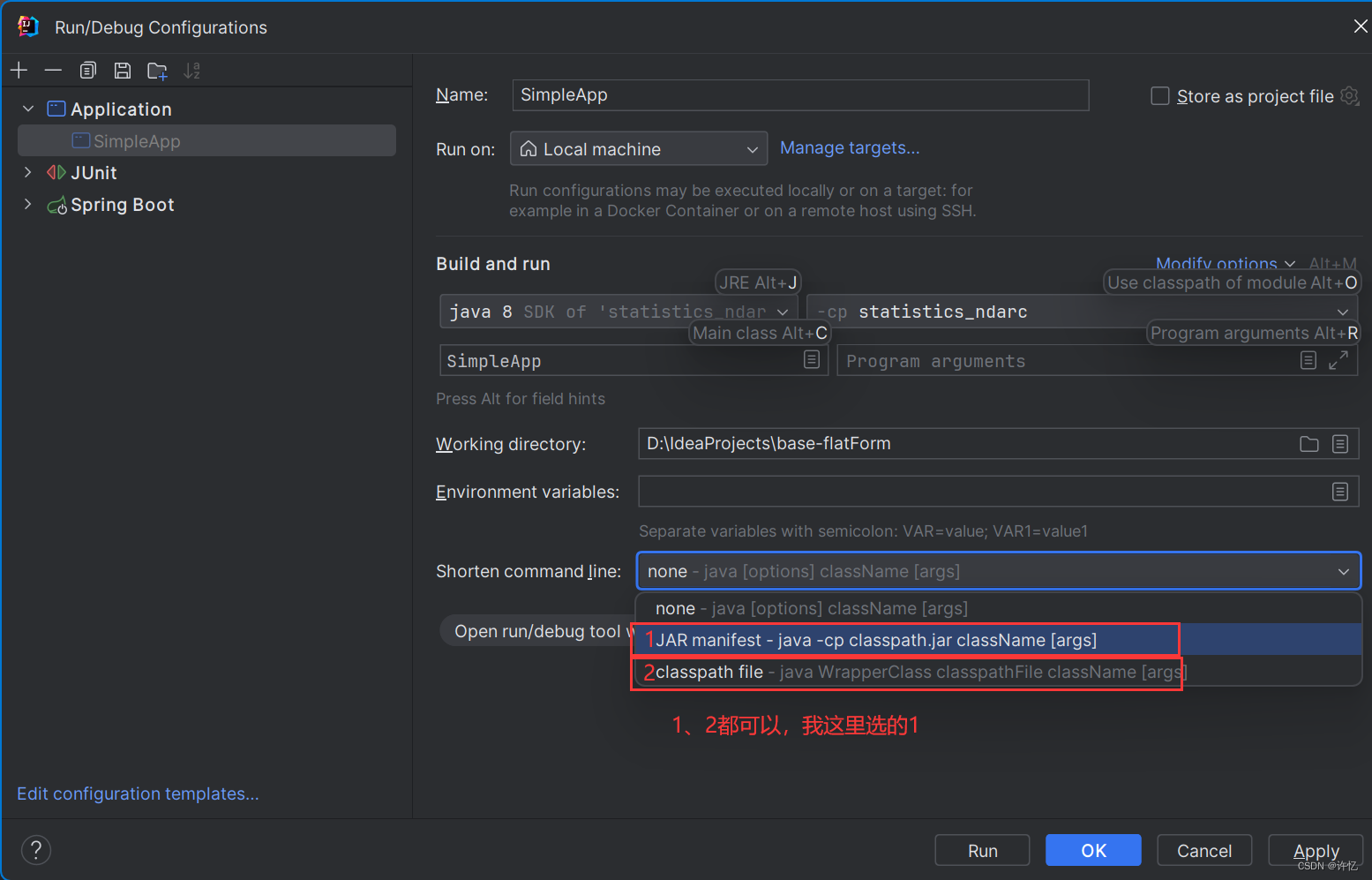
启动问题:IDEA:Error running,Command line is too long. Shorten command line启动行过长
解决方案:
打开Edit Configurations,配置保存完成,Apply之后启动即可。
Spark执行任务时,找不到主节点 Exception in thread “main” org.apache.spark.SparkException: A master URL must be set in your configuration
在Spark中,主节点的地址配置位于spark.master属性中,默认值为local[],表示使用本地模式运行。本文章是本地搭建使用的,所以加上 .master(“local[]”) 即可。
参考博客
- java Exception in thread “main” org.apache.spark.SparkException: A master UR
- IDEA:Error running,Command line is too long. Shorten command line解决方案
- Java大数据处理框架推荐:处理大数据的工具推荐
- 【开发环境】安装 Hadoop 运行环境 ( 下载 Hadoop | 解压 Hadoop | 设置 Hadoop 环境变量 | 配置 Hadoop 环境脚本 | 安装 winutils )
- Hadoop3.x配置流程(Windows)
原文地址:https://blog.csdn.net/qq_43170312/article/details/135459498
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。
如若转载,请注明出处:http://www.7code.cn/show_55862.html
如若内容造成侵权/违法违规/事实不符,请联系代码007邮箱:suwngjj01@126.com进行投诉反馈,一经查实,立即删除!