本文介绍: Redis 的字符串表示为 sds ,而不是 C 字符串(以 结尾的 char*)。对比 C 字符串,sds 有以下特性:可以高效地执行长度计算(strlen);可以高效地执行追加操作(append);– 二进制安全;sds 会为追加操作进行优化:加快追加操作的速度,并降低内存分配的次数,代价是多占 用了一些内存,而且这些内存不会被主动释放。
Redis中字符串表示是如何设计与实现的(SDS)?
引言
在redis中,其键值对中,值可以是数字、字符串或者集合等;但其键key却始终是 字符串 类型。
那么,redis中的字符串底层到底是如何设计的呢?为什么redis要这样设计呢?
本篇文章来详细介绍一下,带你一起了解和学习redis中字符串的设计与实现,不惧面试。
简单动态字符串
Sds (Simple Dynamic String,简单动态字符串)是 Redis 底层所使用的字符串表示,它被用在几乎所有的 Redis 模块中。
SDS是Redis中用于表示字符串值的数据结构,它是一种动态字符串实现。与C语言中的字符串相比,SDS具有更多的特性和功能。SDS的设计目标是在保持高性能的同时,提供较为灵活的字符串操作接口。
底层数据结构
SDS的内部结构如下所示:
SDS的实际存储空间大小为len + free + 1,其中len表示字符串的当前长度,free表示字符串的剩余空间,buf是一个字节数组,用于存储字符串数据。SDS的结构允许字符串长度的动态增长和缩减,且不需要进行内存的重新分配。
为什么不用char *
因为 char* 类型的功能单一,抽象层次低,并且不能高效地支持一些 Redis 常用的操作(比 如追加操作和长度计算操作),所以在 Redis 程序内部,绝大部分情况下都会使用 sds 而不是 char* 来表示字符串。
同时:在 Redis 中,客户端传入服务器的协议内容、aof 缓 存、返回给客户端的回复,等等,这些重要的内容都是由都是由 sds 类型来保存的。
举个🌰
如何优化append操作?
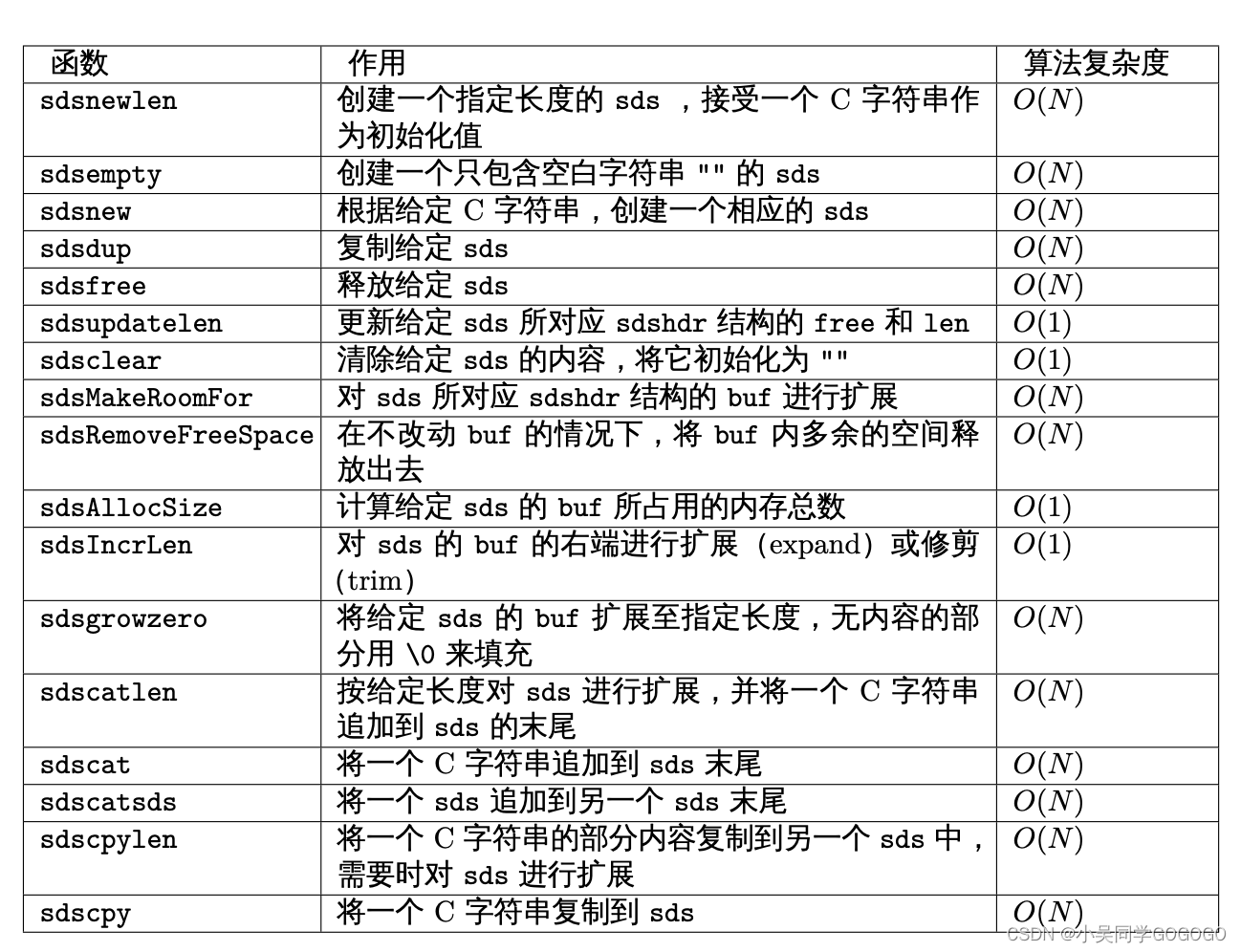
总结
声明:本站所有文章,如无特殊说明或标注,均为本站原创发布。任何个人或组织,在未征得本站同意时,禁止复制、盗用、采集、发布本站内容到任何网站、书籍等各类媒体平台。如若本站内容侵犯了原著者的合法权益,可联系我们进行处理。






