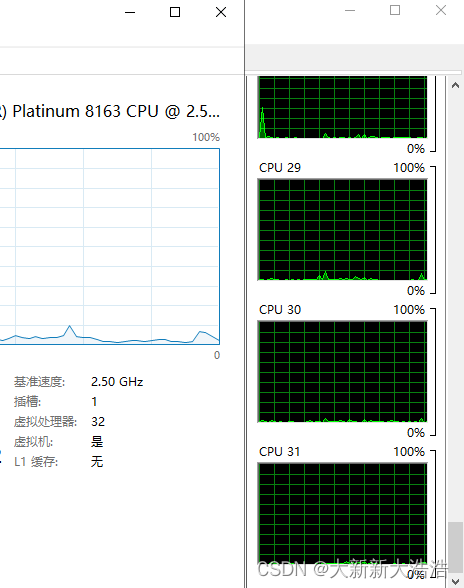
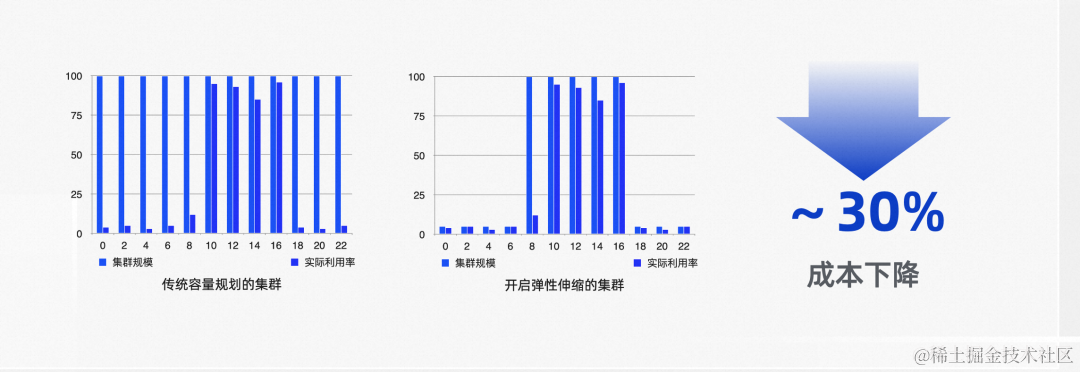
之前做过一个项目,业务最高峰CPU使用率也才50%,是一个IO密集型的应用。里面涉及一些业务编排,所以为了提高CPU使用率,我有两个方案:一个是简单的梳理将任务可并行的采用并行流、额外线程池等方式做并行;另外一个方案是采用基于DAG有向无环图的任务调度。采用并行的方式,改造代码在几十行;采用DAG方案改造代码在几百行,自己觉得也不复杂,但跟别人讲时,感觉理解成本还是有点高,加上并行方案已经可以将最高峰CPU使用率提高到80%多,最终权衡必要性不高,还引入了额外的复杂性,增加维护成本,所以我自己否定了这个方案。但这并不妨碍我对DAG有了一定的理解:
DAG任务调度
DAG任务调度系统的核心概念是将任务表示为一个有向无环图(DAG),其中每个节点表示一个任务,每条边表示一个任务之间的依赖关系。DAG任务调度系统的主要优势在于它可以有效地管理和执行依赖关系复杂的多任务系统,并且可以在大规模分布式环境中运行。所以我们的简单业务编排确实并不需要这样复杂的设计。
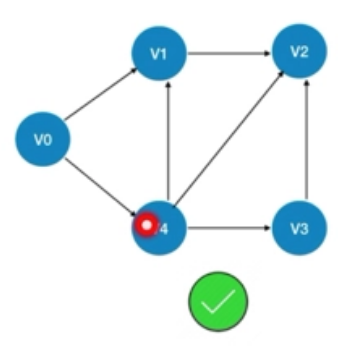
设计DAG,主要要设计三块。一块是节点,代表的是任务。任务对象主要关注任务的执行;
//定义一个Executor接口
//代表一个可执行的任务,execute代表任务的执行
public interface Executor {
boolean execute();
}
/*
* 定义一个Executor接口的实现Task
*id:任务id
*name:任务名
*state:任务状态,简化为0:未执行,1:已执行
*hasExecuted返回任务是否已执行
*/
public class Task implements Executor{
private Long id;
private String name;
private int state;
public Task(Long id, String name, int state) {
this.id = id;
this.name = name;
this.state = state;
}
public boolean execute() {
System.out.println("Task id: [" + id + "], " + "task name: [" + name +"] is running");
state = 1;
return true;
}
public boolean hasExecuted() {
return state == 1;
}
}第二块是图,里面要做两件事,一件是管理任务,一件事管理任务之间的依赖,反应到图上就是要有节点和节点之间的连线;
//任务图,这个类使用了邻接表来表示有向无环图。tasks是顶点集合,也就是任务集合。
//map是任务依赖关系集合。key是一个任务,value是它的前置任务集合。
//一个任务执行的前提是它在map中没有以它作为key的entry,或者是它的前置任务集合中的任务都是已执行的状态。
public class Digraph {
private Set<Task> tasks;
private Map<Task, Set<Task>> map;
public Digraph() {
this.tasks = new HashSet<Task>();
this.map = new HashMap<Task, Set<Task>>();
}
public void addEdge(Task task, Task prev) {
if (!tasks.contains(task) || !tasks.contains(prev)) {
throw new IllegalArgumentException();
}
Set<Task> prevs = map.get(task);
if (prevs == null) {
prevs = new HashSet<Task>();
map.put(task, prevs);
}
if (prevs.contains(prev)) {
throw new IllegalArgumentException();
}
prevs.add(prev);
}
public void addTask(Task task) {
if (tasks.contains(task)) {
throw new IllegalArgumentException();
}
tasks.add(task);
}
public void remove(Task task) {
if (!tasks.contains(task)) {
return;
}
if (map.containsKey(task)) {
map.remove(task);
}
for (Set<Task> set : map.values()) {
if (set.contains(task)) {
set.remove(task);
}
}
}
public Set<Task> getTasks() {
return tasks;
}
public void setTasks(Set<Task> tasks) {
this.tasks = tasks;
}
public Map<Task, Set<Task>> getMap() {
return map;
}
public void setMap(Map<Task, Set<Task>> map) {
this.map = map;
}
}第三块是调度,就是获取任务列表,并按照它们之间的依赖关系来执行。
//调度器,就是遍历任务集合,找出待执行的任务集合,
//放到一个List中,再串行执行(若考虑性能,可优化为并行执行)。
//若List为空,说明所有任务都已执行,则这一次任务调度结束。
public class Scheduler {
public void schedule(Digraph digraph) {
while (true) {
List<Task> todo = new ArrayList<Task>();
for (Task task : digraph.getTasks()) {
if (!task.hasExecuted()) {
Set<Task> prevs = digraph.getMap().get(task);
if (prevs != null && !prevs.isEmpty()) {
boolean toAdd = true;
for (Task task1 : prevs) {
if (!task1.hasExecuted()) {
toAdd = false;
break;
}
}
if (toAdd) {
todo.add(task);
}
} else {
todo.add(task);
}
}
}
if (!todo.isEmpty()) {
for (Task task : todo) {
if (!task.execute()) {
throw new RuntimeException();
}
}
} else {
break;
}
}
}
public static void main(String[] args) {
Digraph digraph = new Digraph();
Task task1 = new Task(1L, "task1", 0);
Task task2 = new Task(2L, "task2", 0);
Task task3 = new Task(3L, "task3", 0);
Task task4 = new Task(4L, "task4", 0);
Task task5 = new Task(5L, "task5", 0);
Task task6 = new Task(6L, "task6", 0);
digraph.addTask(task1);
digraph.addTask(task2);
digraph.addTask(task3);
digraph.addTask(task4);
digraph.addTask(task5);
digraph.addTask(task6);
digraph.addEdge(task1, task2);
digraph.addEdge(task1, task5);
digraph.addEdge(task6, task2);
digraph.addEdge(task2, task3);
digraph.addEdge(task2, task4);
Scheduler scheduler = new Scheduler();
scheduler.schedule(digraph);
}
}是不是也不是很复杂,但是添加删除任务和添加删除依赖需要页面可视化管理,添加多了就容易乱。特别是作为一个平台:用户没有问题,所有用户的误操作问题都可以通过减少操作的复杂性来规避。如果将来真有必要使用DAG任务调度,界面设计至少要将节点和依赖以图形化的方式展示出来,让用户一目了然。
工作流引擎
我们的项目涉及的业务编排,有的同事叫这个是工作流。我就仔细的思考了一下,这个到底是不是工作流。我的理解,就是一个责任链搞定的事情。而工作流是复杂版本的状态机。这个工作流的“流”字更多不是流程,而是流转。如果没有复杂的状态流转就不应该当成工作流来看,增加问题的复杂性。说我们的项目是工作流从道理上讲也不是不对,但就好像说:橘子是一个对象。 对,但没有什么指导意义。
现在基于BPMN2.0协议的工作流引擎很受推崇。Activiti,Flowable都是它的实现。BPMN2.0协议中元素的主要分类为,事件-任务-连线-网关。
一个流程必须包含一个事件(如:开始事件)和至少一个结束(事件)。其中网关的作用是流程流转逻辑的控制。任务则分很多类型,他们各司其职,所有节点均由连线联系起来。
网关分为三类:互斥网关(Exclusive Gateway),又称排他网关,他有且仅有一个有效出口。并行网关(Parallel Gateway),他的所有出口都会被执行。包容性网关(Inclusive Gateway),只要满足条件的出口都会执行。是不是很像DAG有向无环图的一个节点到其他节点的路径?排他网关就是只有一条路径到下一个节点;并行网关就是到下一排节点都有路径;包容性网关就是到下一排节点部分有路径。
这就对了,工作流必须是DAG的。它和任务调度不同在于工作流没有强调调度。但工作流终究要被执行的,实时被执行就是实时被调度;在大数据工作流里也经常见到被周期性调度的情况。
有限状态机
刚才提到工作流是复杂版本的状态机,有没有简单的状态机呢?很多。比如咱们经常见到的用枚举来实现的。定义一个枚举,里面有成功和失败两个状态,他们之间的转换也是状态机。在金融支付领域,支付状态有 支付中,支付成功,支付失败,冲正中,冲正完成…… 状态流转就会比较复杂。可以用状态模式来管理。
状态模式
状态模式是我之前非常喜欢用的来避免大量if else的方法。
根据 GoF 的定义,状态模式的三个核心角色分别是:
环境(Context):它定义了客户端所感兴趣的接口,并维护一个当前状态,在具体状态类中实现该接口的各个具体操作。
抽象状态(State):它定义了一个接口,用于封装环境对象中不同状态对应的行为。
具体状态(Concrete State):它实现了抽象状态接口,封装了不同状态下对环境对象的响应行为。
下面是一个简单实现:
// 定义抽象状态接口
interface State {
void handle();
}
// 定义具体状态类
class ConcreteState1 implements State {
@Override
public void handle() {
System.out.println("当前状态为 State1.");
}
}
class ConcreteState2 implements State {
@Override
public void handle() {
System.out.println("当前状态为 State2.");
}
}
// 定义环境类
class Context {
private State state;
public void setState(State state) {
this.state = state;
}
public void request() {
state.handle();
}
}
public class StatePatternDemo {
public static void main(String[] args) {
// 创建状态对象
State state1 = new ConcreteState1();
State state2 = new ConcreteState2();
// 创建环境对象
Context context = new Context();
context.setState(state1);
context.request();
context.setState(state2);
context.request();
}
}总结
在工作中,有两顶思考帽:一顶是项目可持续性的帽子,要对项目负责,要使用合适的技术;一顶是让项目与时俱进的帽子,过时老套的技术降低了项目的吸引力,可能面临吸引不到更优秀的人才。其实项目中可以不使用某技术本身,却可以使用其思想,比如DAG任务调度的思想梳理清楚依赖,让能执行的尽早执行,提高运行效率。并行化也一定程度的增加了并发度,达到了效果。再举个例子,咱们平时提到的分布式事务,分布式事务的框架工作中很少用,但是分布式事务的思想却随处可见。比如支付时,如果失败超时,则返回失败并发起冲正,确保支付款退回给消费者,这就是一种补偿性事务的思想,就是这么简单。思考有了,工具是次要的。
声明:本文中使用的代码均为网上拷贝,不是本文重点,只做解释说明用。
原文地址:https://blog.csdn.net/xiexiaojing/article/details/135447895
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。
如若转载,请注明出处:http://www.7code.cn/show_56024.html
如若内容造成侵权/违法违规/事实不符,请联系代码007邮箱:suwngjj01@126.com进行投诉反馈,一经查实,立即删除!