关于深度神经网络中基于后门的数字水印的鲁棒性
ABSTRACT
在过去的几年中,数字水印算法已被引入,用于保护深度学习模型免受未经授权的重新分发。我们调查了最新深度神经网络水印方案的鲁棒性和可靠性。我们专注于基于后门的水印技术,并提出了两种简单而有效的攻击方法 – 一种是黑盒攻击,另一种是白盒攻击 – 可以在没有来自地面真相的标记数据的情况下去除这些水印。我们的黑盒攻击通过仅通过API访问标签窃取模型并移除水印。我们的白盒攻击在标记模型的参数可访问时提出了一种高效的水印去除方法,并将窃取模型的时间提高到从头开始训练模型的时间的二十倍。我们得出结论,这些水印算法不足以抵御受到激励的攻击者的重新分发。
1 INTRODUCTION
生成神经网络模型的任务在计算上是昂贵的,同时需要经过彻底的准备和标记的大量训练数据。数据清理任务被认为是数据科学中最耗时的任务之一。根据数据科学从业者的报告,数据科学家将大约80%的时间用于为分析准备和管理数据。然而,对数据的这种巨大投资以及对其进行训练的模型面临着即时的风险,因为一旦发布,模型就很容易被复制和重新分发。为了保护模型免受未经授权的再分发,人们引入了受到多媒体水印广泛应用启发的水印方法。DNN的水印方法涵盖了两个广泛的类别:白盒水印和黑盒水印。与白盒水印相比,黑盒水印更容易进行验证;在前者中,验证仅需要通过窃取模型使用的服务的API访问,而在后者中,验证需要访问窃取模型的所有参数。此外,黑盒水印比白盒水印更有优势,因为它更有可能对抗统计攻击。
在这项工作中,我们调查了最近的黑盒水印方法。这些方法每个都引入了一种或多种基于后门的水印技术来保护模型所有权。后门或神经特洛伊最初是用于针对深度学习安全性的一类攻击的术语,当实体将模型计算的学习外包给另一个不受信任但资源充足的方时,这些攻击会发生。该方可以训练一个在请求的任务上表现良好的模型,而其嵌入的后门在输入中遇到特定触发器时会导致有针对性的误分类。”将弱点变强”的思想开创了一种新的工作线,建议使用后门来保护所有权。其思想是在训练数据集中使用一些触发器来嵌入特定的行为,即一种签名,但不妨碍常规分类任务。训练数据集中的触发器可以采取以下形式之一:嵌入表示所有者标志的内容,输入中的预定义噪声模式,或充当秘密密钥集的一组特定输入。在本文中,我们调查了DNN中的后门是否足够做为嵌入模型的水印的鲁棒性。用于移除后门的现有方法要么不输出模型,而是与服务一起部署,要么在没有访问地面真实标签的情况下无法有效地移除水印。Neural-Cleanse需要访问一组正确标记的样本来检测后门,并且仅适用于水印中使用的一种类型的后门 – 图像上的小补丁。Fine-Pruning通过剪掉对主要分类不太有用的冗余神经元来移除后门。正如我们在实验结果中展示的,没有正确标记的数据,精细修剪也无法有效地移除前述所有水印类别中的后门。当精细修剪成功降低水印的保留率时,它还导致模型准确性的显著下降,使其基本上无用。
我们引入了两种在上述基于后门的水印方案上概念简单而有效的攻击(黑盒和白盒),并且展示了所有这些水印在这两种攻击中都是可移除的。我们的攻击既不需要任何正确标记的训练数据,也不需要嵌入在模型中的后门。我们有两个目标:i) 移除水印,同时 ii) 提供与原始标记模型相同功能的模型,准确度几乎没有下降。我们的黑盒或白盒攻击都实现了这些目标;黑盒攻击只能通过攻击者获得的预测标签访问,而白盒攻击更为高效。通过使用这两种攻击中的任何一种,攻击者都可以从带有水印的模型中生成一个无水印的模型进行重新分发,而无需准备标记的训练数据,特别是在白盒攻击的情况下无需访问相同的计算资源。我们的黑盒攻击是一种模型窃取攻击,并表明如果窃取的模型未在后门样本上进行训练,则后门不会传输到其他模型。我们的白盒攻击需要访问模型的参数,但比从头开始训练模型高效多达二十倍。此外,我们的白盒攻击生成的模型的准确性甚至可能优于标记模型的准确性。
1.1 Our Contributions
我们在这项工作中提出了两个主要的贡献:(i) 我们引入了我们直观的黑盒攻击,可以移除基于后门的水印方案中嵌入的水印。这个攻击仅依赖于公开可用的信息,即没有标记的数据,并且成功地从神经网络中移除了水印,而无需访问网络参数、分类概率向量或作为水印嵌入的后门。在这个攻击中,窃取的模型的性能和准确性在水印模型的范围内,误差在4%以内。(ii) 我们引入了更有效的白盒攻击,适用于我们有保证能够访问模型参数的场景。利用额外的信息,我们的白盒攻击比从头开始训练数据更快(最多二十倍),且模型的准确性与水印模型的误差在1%以内。我们的攻击表明,这些基于后门的水印方案不足以防止受到激励的攻击者的重新分发。我们明确显示 Adi等人定义的不可移除属性不成立。因此,似乎有必要开发新的、更强大的保护技术。
1.2 Paper Organization
我们在第2节中为深度神经网络和基于后门的水印方案提供正式定义,同时描述了这些方案的安全漏洞。随后在第3节中,我们介绍了用于去除水印的黑盒和白盒攻击。最后在第4节中,我们呈现了证实成功去除水印的实验结果。在第5节中,我们将我们的工作放置在当前研究体系中。
2 BACKDOOR-BASED WATERMARKING
后门使操作者能够训练一个故意输出特定(错误)标签的模型;基于后门的水印方案利用这一特性设计触发器集来给DNN加水印。黑盒水印的直观思路是利用深度神经网络的泛化和记忆能力来学习嵌入的触发器集及其预定义标签的模式。学到的模式和它们对应的预测将充当所有权验证的密钥。如第2.3节所述,我们关注文献中提出的三种基于后门的水印方案。
2.1 Definitions and Models
我们在整个论文中采用 Adi 等人 [1] 的符号,以相应地介绍我们的攻击。为了训练神经网络,我们最初需要一些客观的地面真值函数 𝑓。神经网络由两个算法组成:训练和分类。在训练中,网络试图学习 𝑓 的最接近的近似。然后,在分类阶段,网络利用这个近似来对未见过的数据进行预测。形式上,神经网络的输入由一组二进制字符串表示:𝐷 ⊆ {0, 1}∗,其中 |𝐷| = Θ(2^𝑛),其中 𝑛 表示输入长度。相应的标签由 表示,其中 |𝐿| = Ω(𝑝(𝑛)),对于正多项式 𝑝(.);符号 ⊥ 表示特定输入的未定义分类。地面真值函数 𝑓: 𝐷 → 𝐿,为输入分配标签。此外,对于
(具有定义地面真值标签的输入集),
= {𝑥 ∈ 𝐷|𝑓 (𝑥) ≠ ⊥},算法对 𝑓 的访问通过一个 Oracle
进行。因此,如图1所示的学习过程包括以下两个算法:
Train (, 𝐷): 一个概率多项式时间算法,输出一个模型 𝑀
Classify (𝑀, 𝑥): 一个确定性多项式时间算法,对于每个输入 𝑥 ∈ 𝐷,输出一个标签 𝑀(𝑥) ∈ 𝐿{⊥}
度量 𝜖−准确度评估算法对(Train,Classify)的准确性。在一个 𝜖−准确的算法中,以下不等式成立:
𝑃𝑟[𝐶𝑙𝑎𝑠𝑠𝑖 𝑓 𝑦(𝑀, 𝑥) ≠ 𝑓 (𝑥)|𝑥 ∈ ] ≤ 𝜖
概率是在 Train 随机性的基础上取的,假设对于这些输入,地面真值标签是可用的。

2.2 Backdoor-based Watermarking in DNNs
后门技术教会机器学习模型输出不正确但有效的标签 𝑇𝐿 : 𝑇 → 𝐿{⊥};𝑥 ↦ 𝑇𝐿 (𝑥) ≠ 𝑓 (𝑥) 到特定的输入子集 𝑇 ⊆ 𝐷,即触发器集。对于一个模型,对 𝑏 = (𝑇 ,𝑇𝐿) 形成了后门。一个名为 𝑆𝑎𝑚𝑝𝑙𝑒𝐵𝑎𝑐𝑘𝑑𝑜𝑜𝑟 的随机算法生成后门 𝑏。有两种模型后门的变体:在训练期间或在训练后。我们专注于在训练期间引入后门,因为我们的实验支持 Adi 等人的结论,即在训练后引入的后门更容易移除。完整的后门过程如图2所示。

形式上,后门 (, 𝑏, 𝑀) 是一个算法,对于输入的 𝑓 的 Oracle,后门 𝑏 和模型 𝑀,输出一个模型
。要求后门模型
对于来自触发器集的输入输出特定的不正确标签(关于 𝑓 的)以及其他输入的正确标签。换句话说,对于被后门处理的模型
,以下两个不等式必须始终成立:

为了使用后门处理过程对ML模型进行水印,使用算法 𝑀𝑀𝑜𝑑𝑒𝑙()。MModel 包括以下子算法:
1. 𝑏 ← 𝑆𝑎𝑚𝑝𝑙𝑒𝐵𝑎𝑐𝑘𝑑𝑜𝑜𝑟(): 水印方案确定嵌入的后门 𝑏。注意,我们与 Adi 等人不同,我们忽略了主密钥和验证密钥 𝑚𝑘、𝑣𝑘,因为它们对我们的攻击没有影响。
2. 计算 ← 𝑀𝑎𝑟𝑘 (
, 𝑏): 通过训练和嵌入后门 𝑏 计算水印模型
。
3. 输出 (, 𝑏)。
水印的验证由算法 𝑉𝑒𝑟𝑖𝑓𝑦(𝑀, 𝑏) 执行。𝑉𝑒𝑟𝑖𝑓𝑦以模型M和后门𝑏为输入,并输出 {0, 1} 中的一个比特,指示模型𝑀是否存在水印。形式上

其中,I[expr] 是指示函数,如果 expr 为真,则计算为 1,否则为 0。请注意,由于我们跳过了加密承诺的详细信息,𝑉𝑒𝑟𝑖𝑓𝑦中的标记密钥𝑚𝑘 转化为触发器集𝑇中的输入𝑥,而验证密钥𝑣𝑘指的是相应的标签。此外,
来自地面真值标签对于触发器集𝑇 中的输入是未定义的这一假设,我们假设该标签是随机的。因此,我们假设对于任何 𝑥 ∈ 𝑇,我们有
。因此,预计
的输入会“随机”落入后门标签。因此,为了在没有偏见的情况下验证模型中是否存在水印,我们需要从分类结果中减去这个数量。
2.3 Backdoor-based Watermarking Schemes(基于后门的水印方案)
我们调查了最近在中提出的基于后门的方案。 这些方案中嵌入的水印可以具有以下三种形式之一:嵌入内容、预定义噪声和抽象图像。
a) 内容嵌入(Logo):这种方法在一组输入中添加一个固定的视觉标记(例如文本),即水印集。带有此水印的输入都将被分类为一个固定标签。
b) 预定噪声:这种方法将固定的高斯噪声实例作为水印添加到输入中。与内容嵌入水印方案类似,此方法将标记的输入映射到一个固定的标签。
c) 抽象图像:在这一类水印中,选择了一组抽象图像[1]或与训练数据不同分布的图像,并用预定义的类别对其进行标记。 在抽象图像水印和前两者之间有两个主要区别:i) 触发器集的不同子集映射到不同的类别,而不是一个固定的类别,ii) 水印不再是添加到任何输入的模式,而是一组固定的输入和标签。因此,水印测试集与水印训练集相同。
2.4 Backdoor-based Watermarking – Security(基于后门的水印 – 安全性)
我们强调,我们的攻击使得[1, 11, 32]提出的方案的安全性主张无效。Adi等人[1]为他们的安全性主张提供了一个优秀的形式化模型。然后,我们可以展示安全性已经破坏了比他们模型中假定的更弱的对手。我们强调我们攻击的特性:
• 我们不需要任何正确标记的数据。来自相同分布的数据,但没有任何标签就足以进行我们的攻击。因此,准备数据集的最耗时任务对于对手来说不再适用。
• 我们只需要对带有水印的模型进行少量查询,以推导出标签 – 与原始训练数据集的数量级相当。因此,对抗方的速率限制或阻止不是我们攻击的成功防御措施。
• 我们不需要触发器集或其后门的标签的任何知识。因此,对手只能在模型被水印化的假设下使用我们的算法。
• 我们的攻击,特别是白盒攻击,对于复杂的模型,如Image-Net数据集的ResNet-32,实现了可比较的准确性。因此,对手可以成功使用窃取的模型。
• 我们的白盒攻击所需的训练时间明显少于从头开始训练模型。因此,任何声称移除水印对于对手来说成本太高的说法都不适用 – 即使忽略准备数据的时间。
Adi等人[1]在他们的论文中正式定义了不可移除性、不可伪造性和强制非平凡所有权等安全性质。我们关注不可移除性属性,该属性防止对手移除水印,即使他/她知道水印的存在和使用的算法。不可移除性要求对于每个算法A,赢得以下游戏的机会都是可以忽略的:
我们提出了两个计算受限的A,它们不仅赢得了这个安全游戏,而且要求的条件更少。我们的黑盒攻击只需要对模型()和输入
进行API访问,即可移除水印并保持功能不变。我们的白盒攻击通过访问模型(
)参数和域中的公共输入
,使用更少的计算资源来实现这一点。尽管在游戏中被授予,但我们的任何一种攻击都不需要访问地面实况预言者
,即标记数据。相应的调整后的游戏分别在第3.1和第3.2节中呈现。
3 ATTACKS ON BACKDOOR-BASED WATERMARKING(基于后门的水印攻击)
我们攻击的假设是,第2.3节介绍的基于后门的水印方案将输入分布划分为两个不相交的分布:i) 主要分布,被正确分类;ii) 水印分布,被故意错误分类且不符合主要分布。这种在输入分布中的分离在所有三种类型的触发器集中都是共同的。这导致水印被视为主分类中的离群值,网络永远无法学会正确分类它。我们在第3.1和第3.2节中介绍了两种利用这种不相交性来移除水印的攻击。与原始的对手A (在第2.4节中介绍)相比,我们的攻击需要更少的要求,因为它们不需要访问训练数据和地面实况函数。它们还保证更高的有效性。原因是,如果攻击者A提出一个模型,使得该模型在测试上达到与带水印的模型
相似的准确性,同时𝑉𝑒𝑟𝑖𝑓𝑦(
, 𝑏) = 0,那么不可移除性游戏将被标记为获胜。从前一节的𝑉 𝑒𝑠𝑢𝑙𝑡 description中可以看出,如果以下条件成立,函数输出为零:
;意味着
将触发器集中的输入映射到与预定义标签不同的标签的数量超过了触发器集的一小部分。我们超越了这个条件,并引入了完全去除水印的两个条件:

在完全去除水印中,攻击者提出的模型 𝑀˜ 在测试集上仍然能够达到与带水印模型几乎相近的准确性。然而,在这个定义中,𝑀˜ 将触发器集中的输入映射到相应的预定义标签的数量不会超过随机标签分配的结果,即不会超过一个小部分,也就是说,任何水印的痕迹都被去除了。
3.1 Black-box Attack
在我们的黑盒攻击中,我们通过使用与前面讨论的主要分布类似的输入查询带水印模型,然后在其上训练一个替代模型来窃取功能。由于这个分布本质上不包含任何水印,所以窃取的模型只复制无后门的功能。我们的攻击需要有限数量的训练输入,尽管在计算上效率较低,但节省了繁重的数据准备任务。我们的黑盒攻击不假设对触发器集的任何访问,也不假设对任何带标签的数据,包括训练数据或带水印模型 的参数。我们的攻击仅依赖于公共信息。我们用输入
查询带水印模型
,并使用分类标签作为数据标签,以训练一个派生模型,如图3所示。注意
与带水印模型
的训练数据𝐷不同,但来自相同的应用领域。我们通过以下黑盒、完全去水印的游戏展示我们的攻击模型。游戏中的
表示通过预测 API 对
进行的黑盒访问。

攻击者 A 向 发送查询并根据
的响应训练其模型
。如果 A 能够达到原始模型的准确性并完全去除水印,则 A 获胜。

3.2 White-Box Attack
我们在前一节提出的黑盒攻击不需要有关模型参数的任何信息。然而,我们表明,如果攻击者 A 被保证能够访问模型参数,这是 Adi 等人不可移除游戏中的默认假设,他们可以更有效地去除水印。我们通过以下白盒完全去除水印游戏对白盒攻击建模,该游戏与黑盒模型相同,只是对模型 的访问被直接访问
替代。

回顾一下我们的目标是防止模型学习对水印至关重要的错误分类。如前所述,我们将水印样本视为主分布的异常值,并认为标记的模型过度拟合以学习对它们进行错误分类。为了去除水印,我们对标记的模型应用正则化以规范化权重并避免过拟合。我们的白盒攻击如图4所示。

白盒攻击包括以下两个子算法:正则化和微调。这两个子算法的输入都是,它与𝐷属于相同的域但是不同。

第一个子算法 A𝑅𝑒𝑔 在 上执行正则化。由于我们不知道哪一层对学习水印的错误分类起作用,我们定义了正则化以影响所有层,以防止对后门的过拟合。我们的实验表明,A𝑅𝑒𝑔使用 L2 正则化完全去除了水印。然而,与原始模型𝑀相比,它影响了测试准确性。为了弥补这一准确性下降,A𝑅𝑒𝑔 的输出随后被馈送到 A𝐹𝑖𝑛𝑒 进行微调,使用一个未标记的训练集。我们强调,我们的白盒攻击不需要地面真相函数或触发器集的任何信息就能赢得游戏。相反,它使用原始模型域中的一组随机输入,并查询模型
对它们进行标记。我们的实验表明,这种攻击比训练新模型更加高效,并且达到相同的准确性。
4 EXPERIMENTS
我们展示了对第2.3节中的水印方案应用我们的黑盒和白盒攻击的结果;这些结果证实我们的攻击成功地移除了水印。这些结果可以通过我们提供的代码进行验证。
4.1 Experiment Setup
在第3节中,我们通过完整的水印去除游戏介绍了我们的攻击,参与者包括挑战者 𝑀𝑀𝑜𝑑𝑒𝑙 和攻击者 A。在本节中,我们模拟了这两个实体并根据描述的算法运行实验。我们使用具有以下特征的计算基础设施:Intel(R) Xeon(R) CPU E5-2650 0 @ 2.00GHz,255GB RAM,Driver Version: 418.40.04,和 CUDA Version: 10.1。我们在 Image-Net 训练中使用 GPU 型号 Tesla P100 16GB,并在其他情况下使用 Tesla K10.G2.8GB。
4.1.1 数据集和模型。我们在深度神经网络文献中评估我们的攻击,使用了四个流行的数据集:MNIST、CIFAR-10、CIFAR-100 和 Image-Net。我们的数据预处理包括数据归一化以及数据增强。数据增强通过随机旋转、宽度和高度位移以及水平翻转来执行。对于MNIST数据集,我们使用LeNet模型,在60K训练图像上进行训练,并在10K测试图像上进行测试。对于CIFAR-10,我们使用VGG-16模型,训练模型在50K训练图像上,并在10K测试图像上进行测试。对于MNIST和CIFAR-10数据集,我们将训练数据一分为二,分别用于攻击者和所有者。我们的小批量包含64个元素,使用学习率为0.001的RMSProp优化器。在训练任何模型时,我们使用训练准确性的Early Stopping,最小增量为0.1%,耐心为2。与其他两个数据集不同,对于CIFAR-100 和 Image-Net,我们使用ResNet-32来训练模型。对于CIFAR-100 和 Image-Net,我们在攻击者和所有者之间使用重叠的训练数据,我们在第4.4节中讨论原因。我们使用批量大小为100,使用初始学习率为0.1和动量为0.9的SGD优化器。我们通过将学习速率除以10来调整学习速率,每次训练停滞时都会这样做。对于白盒攻击,我们使用10个epochs的常数进行正则化。我们对所有数据集使用0-1的“min-max feature scaling” 进行规范化。
4.1.2 原始模型和标记模型生成。我们首先在我们的完整水印移除游戏中模拟了𝑀𝑀𝑜𝑑𝑒𝑙算法,生成了原始模型 𝑀、带水印的模型 𝑀ˆ 和包含水印的水印集 𝑇 及其对应的标签 𝑇𝐿。不同方案的水印集示例如图5所示,根据第2.3节的描述构建。𝑀𝑀𝑜𝑑𝑒𝑙使用水印集的一部分和剩余训练集的一部分训练模型 𝑀ˆ。请注意,这两个集合的其余部分是形成测试集和水印测试集所需的。对于每个实验,我们使用随机选择的触发器集的子集来训练水印模型。回顾第2.3节,水印集和水印测试集对于Abstract Images水印方案是相同的,但对于Embedded Content或Pre-specified Noise方案则不同。

4.1.3 攻击算法 A 和生成 𝑀˜
. 在我们的黑盒和白盒攻击中,算法 A 的目标是推导出一个模型 𝑀˜,
保持与标记模型 𝑀ˆ 相同的测试准确性,同时将水印保留降低到 1
|𝐿|
,其中 |𝐿| 是有效类别的总数。这种减少表明该模型将水印输入关联到预定义类别的程度不超过随机分类器,因此表明成功完全去除水印。为了生成 𝑀˜
,我们的两种攻击都不使用原始模型 𝑀 的带有地面真实标签的训练数据,也不使用任何水印信息。相反,它们都使用公开已知的 𝑀ˆ
域中的输入向水印模型 𝑀ˆ 查询,并使用相应的标签对 𝑀˜
进行训练。白盒攻击使用 𝑀ˆ
的参数初始化 𝑀˜
,然后经历正则化,随后是使用 𝑀ˆ
标记的公共数据进行微调。
4.1.4 安全性和性能评估。在接下来的内容中,我们将使用具体的参数介绍和评估黑盒和白盒攻击的设置。正如本节前面提到的,我们的安全性评估指标是:i) 测试准确性和 ii) 水印保留。对于测试准确性,我们将通过比较我们攻击生成的模型在对未见过的测试集进行分类的准确性与目标模型的准确性来进行评估。对于水印保留,我们测量通过我们攻击生成的模型将一组带有标记的输入分类为它们的预定义标签的程度。我们还根据运行时间而不是纪元数来评估我们攻击的性能。纪元数取决于模型训练中的一些因素 – 例如输入大小,而时间是一个独立的度量。例如,在微调阶段(第3.2节)中,一个纪元的时间远远超过正则化中一个纪元的时间,因为微调的训练集大小至少是正则化中训练集大小的十倍。
4.2 Fine-Pruning Attack
Fine-pruning使用黑盒标签修剪休眠神经元 – 即激活频率低于阈值的神经元 – 以去除后门。修剪后会进行微调阶段以提高准确性。
我们的结果表明,使用黑盒标签进行精修不能同时去除嵌入式水印并保持测试准确性。图6显示了攻击在不同阈值下的准确性和水印保留情况。请注意,我们不考虑较大的阈值,因为修剪许多神经元会导致测试准确性显著下降。具体而言,在最佳情况下,对于抽象图像,精修将水印保留降低到22.2%,而在 CIFAR-10 数据集上则降低了8.4% 的测试准确性。相比之下,我们的白盒攻击将水印保留降低到12.8%,仅减少了1% 的准确性。
我们验证了在攻击者能够访问地面真实标签的情况下,精修攻击确实可以去除水印。然而,我们不将此攻击视为与我们的攻击进行公平比较,因为它在这种强假设下进行。
4.3 Our Results
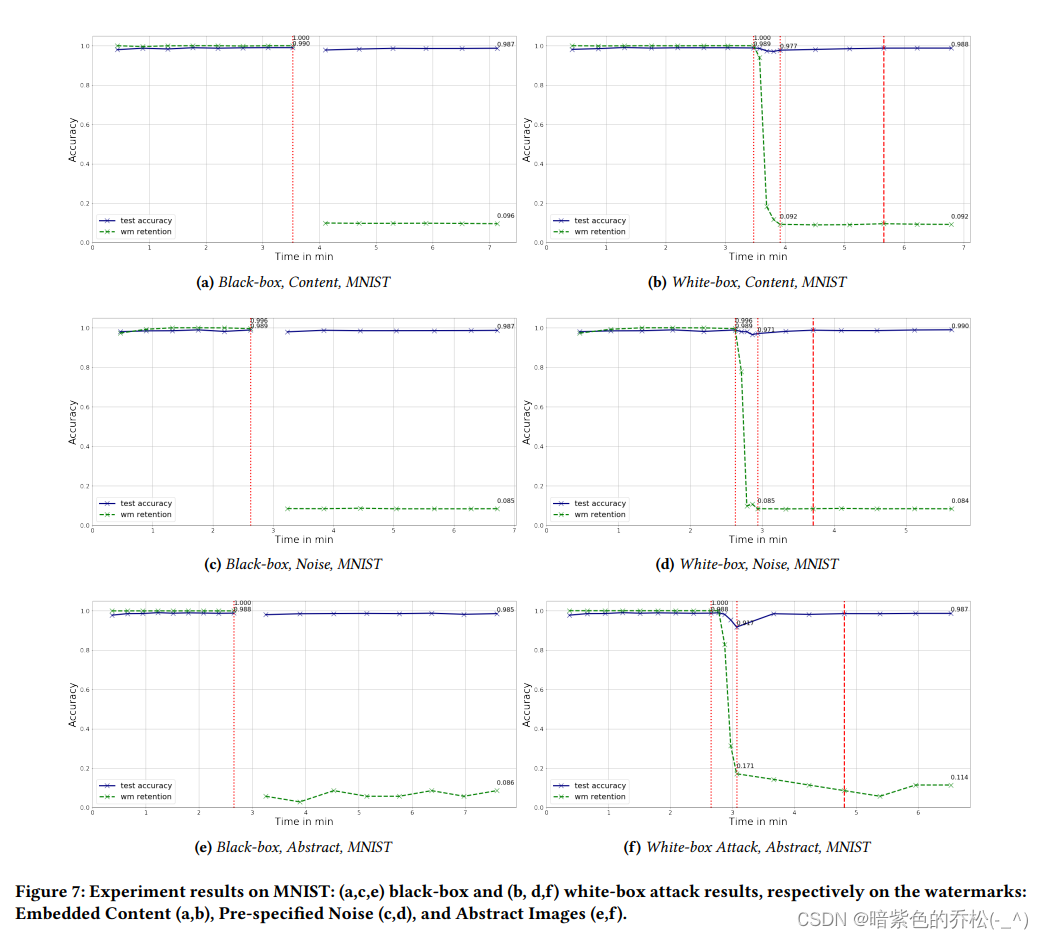
4.3.1 水印去除。我们在表1中总结了我们的黑盒和白盒攻击的结果。图形表示在图7、8和10中提供。我们在MNIST、CIFAR-10和Image-Net数据集上评估我们的攻击,针对第2.3节描述的每种水印方案进行评估:嵌入内容、预定义噪声和抽象图像。
由于Abstract Images在其原始论文[1]中也用于对在CIFAR-100上训练的模型进行水印处理,我们还包括了对这些模型进行水印去除的实验,如图9所示。图7、8、10和图9(a)中的子图(𝑎)、(𝑐)和(𝑒)表示黑盒攻击的结果。类似地,图7、8、10和图9(b)中的子图(𝑏)、(𝑑)和(𝑓)表示对相应数据集的白盒攻击结果。每个图表评估了由算法𝑀𝑀𝑜𝑑𝑒𝑙生成的模型,然后是A的评估,前者代表所有者的带水印的模型,后者代表攻击者的模型。如黑盒攻击图表(𝑎)、(𝑐)和(𝑒)所示,攻击者A在𝑀𝑀𝑜𝑑𝑒𝑙完成训练水印模型𝑀ˆ后开始训练其模型𝑀˜(红色虚线)。A从随机权重开始训练,并查询𝑀ˆ为其输入进行标记,然后训练模型。图表显示黑盒攻击所需的时间与𝑀𝑀𝑜𝑑𝑒𝑙训练𝑀ˆ所需的时间相比。在这两个模型中,训练持续到它们的测试准确性在所需水平上稳定。
我们的结果表明,黑盒攻击删除水印的性能与训练原始带水印的模型相当,而白盒攻击通过显著加速实现了这一目标。值得注意的是,通过允许精调时间更长,白盒攻击甚至可以达到比带水印模型更高的准确性。
对于Image-Net数据集,我们还包括了一种黑盒攻击,攻击者可以获取预测的概率向量的信息。我们展示了通过获得此信息,攻击者可以使用黑盒攻击偷取Image-Net模型,仅使准确性下降3%。在白盒攻击中,我们优化了攻击以达到相同水平的准确性,然后攻击者只需要模型所有者(或黑盒攻击)用于训练的30%的数据样本,但在很短的时间内就可以去除水印。白盒攻击者的准确性下降可以通过使用更大的(未标记的)数据集进一步降低。例如,当使用100%的数据样本时,白盒攻击对抽象图像水印的准确性下降不到1%。


4.4 Discussion on Experiments and Results
我们在这里进一步讨论我们攻击中的参数:
i) 阻止我们源模型达到最高准确度的限制,
ii) 我们选择模型背后的原因,
iii) 对模型必须在弹性后门和高准确性之间进行选择的深入调查,并提供证据,不能同时保持两者。
4.4.1 不是最高准确度。由于我们在实验中模拟了挑战者和攻击者,并希望不允许它们的训练数据集重叠,因此我们的模型实际上只能访问一半的训练数据集。这个限制阻止了我们的源模型,甚至在MNIST和CIFAR-10实验中未标记的模型,达到它们的最高可能准确度。然而,尽管存在这个限制,我们的攻击仍然成功地去除了嵌入的水印,同时保持了源模型的(降低的)准确度。对于CIFAR-100和Image-Net,不重叠的要求导致超过10%的准确度损失。因此,对于这种情况,我们允许水印模型和攻击者模型的训练集重叠。
4.4.2 模型选择。在我们的实验中,攻击者对𝑀˜采用与所有者为目标水印模型𝑀ˆ所使用的相同的模型架构。这个选择有两个动机:
i) 正如Juuti等人所述,更高复杂度的模型在它们与源模型一样复杂之前会提高预测准确性。因此,一方面,攻击者不能使用比目标模型容量更小的模型,否则他将失去准确性。另一方面,训练更高容量的模型需要更多资源,例如更多的查询。这阻止了攻击者训练比源模型容量更高的目标模型。因此,我们的目标模型是攻击者实现最佳准确性所需资源最少的最佳选择。
ii) 我们攻击中的水印去除取决于学习主分类,而不是学习针对具有与主数据不同分布的触发集的预期误分类。由于模型相似性可能增加后门传输的机会,我们为了增加攻击者保留水印的机会,选择使用与所有者相同的模型。这被认为是攻击者的最坏情况。尽管我们选择的模型是水印传输最有可能的情况之一,但我们的攻击成功地去除了水印,使得这种架构成为攻击者的最佳选择。
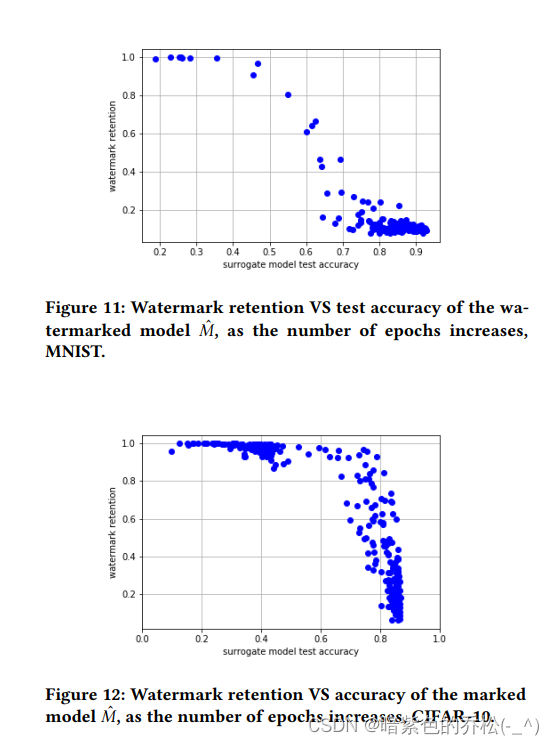
4.4.3 水印保留和测试准确性。除了我们攻击成功去除水印之外,我们在实验中观察到了另一个重要的结果。在我们的黑盒攻击中,我们将模型窃取应用于嵌入水印的完全训练好的模型 𝑀ˆ。为了研究对部分训练好的模型进行模型窃取的成功性,我们反复将攻击应用于标记的模型 𝑀ˆ 在其训练过程中。窃取的模型 𝑀˜ 的测试准确性和水印保留的结果绘制在图11和图12中,分别对应 MNIST 和 CIFAR-10 数据集。如果 𝑀ˆ 达到更高的测试准确性,攻击就会获得较低的水印保留。这增加模型准确性的结果是通过在训练 𝑀ˆ 过程中增加时代数来克服欠拟合的结果。欠拟合的模型 𝑀ˆ 将其水印(后门或偏向后门的偏见)传递给窃取的网络 𝑀˜,使其更具有去除水印的韧性。显然,我们的黑盒攻击可以成功对抗任何100%准确的模型。因此,对于白盒攻击,子图 (𝑏)、(𝑑) 和 (𝑓),A 从 𝑀𝑀𝑜𝑑𝑒𝑙 的参数开始运行算法(第一个红色虚线),并需要 𝑀ˆ 对其输入进行标记。A 首先经历了对 𝑀˜ 进行正则化的阶段,这个阶段所需的时间相比于模型的训练时间较短。在去除水印后(第二个红色虚线),A 进行微调,直到 𝑀˜ 在测试准确性上与 𝑀ˆ 为 𝜖-close(红色虚线)。

水印保留只能通过模型的不准确性引入。然而,我们的结果表明,这些不准确性需要相当显著才能导致基于后门的水印的成功保留。
5 RELATED WORK
5.1 Black-box Watermarking Schemes
通过仅通过远程 API 访问的神经网络的保护需求,鼓励在深度神经网络中使用黑盒水印。DeepSigns将水印嵌入目标层激活集的概率密度函数中,并引入了两个版本的框架,以在白盒和黑盒环境中提供水印。在另外两种方法中,作者使用对抗样本在零比特水印算法中进行水印处理,以实现在不需要模型参数的情况下提取水印。然而,这种方法需要对所使用的对抗样本在其他网络中的可转移性进行限制。基于后门的水印,正如本文所研究的那样,是黑盒水印的另一种最近的研究方向,它在训练过程中向模型提供秘密触发集及其预定义的标签以保护所有权。


5.2 Backdoor Removal
由于为神经网络设置后门可能带来其他威胁,识别和消除这些威胁在研究中引起了关注。然而,通常这些系统旨在与神经网络一起使用。它们的任务仅仅是防止积极使用嵌入的后门,而这对于攻击水印方案的情景并不适用,因为触发集从未被公开。有一些方案在任何时候都不需要访问触发集。NeuralCleanse方法首先通过检查输入图像中应该修改多少像素以使预测更改为另一个类别来检测模型中是否存在后门。当对于许多良性输入存在一致的小修改时,就假定存在后门,然后进行逆向工程和缓解过程。该方法仅适用于被限制在图像的小块中的后门,而这不是本文中所有水印类型的情况。Fine-Pruning方法通过修剪多余的神经元来消除后门。在第4.2节中详细讨论了这种攻击。我们展示了精细修剪攻击只能在访问正确标记的数据的情况下消除后门。
5.3 Removing Backdoor-based watermarks
在另一种消除基于后门的水印的方法中,Hitaj等人引入了Ensemble和Evasion攻击来消除基于后门的水印。Ensemble攻击窃取 𝑛 模型并收集每个查询的所有模型的响应。然后,它选择从被窃取的网络的响应中获得的最高投票的答案,并将其作为API预测提供。与此攻击相比,我们的攻击仅需要一个标记的模型,并生成一个可以重新分发的干净模型。在的Evasion攻击中,检测器机制阻止了水印的验证。当怀疑到一个查询是水印触发时,该服务将返回一个随机的类别预测。如果触发样本的分布与原始样本相似,这种方法在消除后门时将不起作用。Chen等人通过对模型进行微调来消除基于后门的水印,他们认为先前的结果[1]表明基于后门的水印方案对微调的抵抗力是由于学习速率的低值。他们使用标记的(20% – 80%)和未标记的数据的组合来消除水印。我们的攻击在不需要访问标记的数据、多个模型或规避旨在进行水印验证的查询的情况下破坏了基于后门的水印方案的安全性。
5.4 Model Stealing Attacks
Orekondy等人概括了模型窃取攻击,其要求较之前文献中的类似工作更少。我们在黑盒攻击中采用了与Orekondy等人类似的方法,有两个区别:i)我们使用与模型训练数据类似分布的数据而不是随机图像查询目标模型,ii)我们只需要查询的最终标签而不是它们的概率向量。与概率向量相比,仅限制对最终标签的访问是对先前模型窃取攻击的一种提出的防御方法。我们的黑盒攻击实现了接近标记模型的准确性,这表明这种提出的防御对模型窃取攻击是不足够的。
6 CONCLUSION
我们提出了两种简单而有效的攻击方法,针对深度神经网络中的最新基于后门的水印方案:i)黑盒攻击,和ii)白盒攻击。目标模型中的水印可以采用以下任何形式:i)标志或嵌入的内容,ii)预定义的噪声模式,或iii)抽象图像。我们的黑盒和白盒攻击不需要访问触发集、带水印模型的地面真相函数或任何标记数据。这在准备训练数据方面节省了大量的时间和资源。我们的攻击使用来自标记模型的公开已知领域的有限数量输入,并查询模型以获取标签。它们成功地去除了模型的水印,并对分类准确性几乎没有影响。我们的黑盒方法通过最小的访问要求,仅利用模型的分类标签,实现了这些目标。然而,提供更多信息(例如,标记模型的参数)使我们能够设计比我们的黑盒攻击更高效和准确的白盒攻击。
原文地址:https://blog.csdn.net/weixin_63967970/article/details/135585777
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。
如若转载,请注明出处:http://www.7code.cn/show_56078.html
如若内容造成侵权/违法违规/事实不符,请联系代码007邮箱:suwngjj01@126.com进行投诉反馈,一经查实,立即删除!






