本文介绍: 该程序基于Hadoop MapReduce框架实现了简单的单词计数功能,适用于大规模文本数据的并行处理。WordCount(词频统计)/* Map函数,处理每一行的文本 */input//Value使用Text类型表示文本行2:从文本中提取文档ID和实际文本内容snippet;3:使用空格、单引号和破折号作为分隔符,将文本snippet分词;for文本snippet中的每个单词:5: 去除特殊字符后将写入context,发射给Reducer;end for。
词频统计
通过分析大量文本数据中的词频,可以识别常见词汇和短语,从而抽取文本的关键信息和概要,有助于识别文本中频繁出现的关键词,这对于理解文本内容和主题非常关键。同时,通过分析词在文本中的相对频率,可以帮助理解词在不同上下文中的含义和语境。
“纽约时报”评论数据集记录了有关《纽约时报》2017年1月至5月和2018年1月至4月发表的文章上的评论的信息。月度数据分为两个csv文件:一个用于包含发表评论的文章,另一个用于评论本身。评论的csv文件总共包含超过200万条评论,有34个特征,而文章的csv文件包含超过9000篇文章,有16个特征。
本实验需要提取其中的 articleID 和 snippet 字段进行词频统计
MapReduce
在Hadoop中,输入文件通常会通过InputFormat被分成一系列的逻辑分片,分片是输入文件的逻辑划分,每个分片由一个Mapper处理。
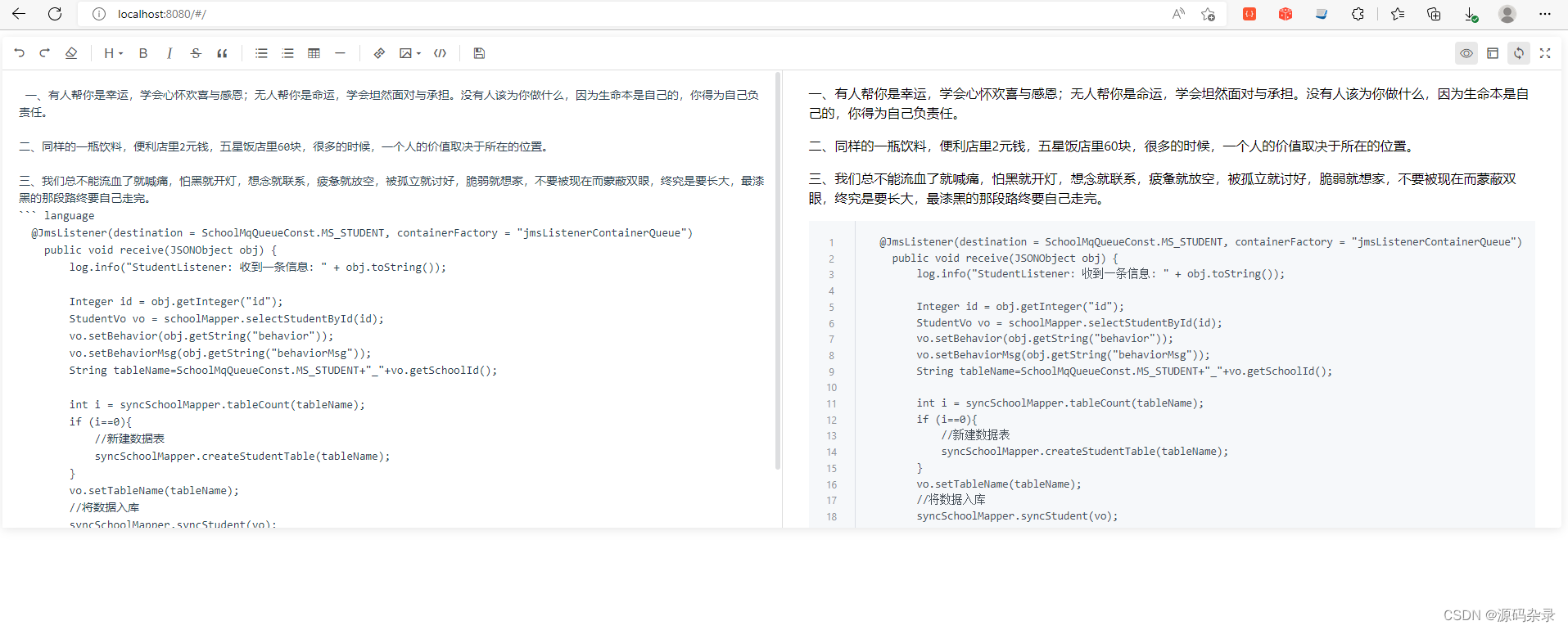
本实验中,WordCount通过MapReduce统计snippet 字段中每个单词出现的总次数。程序主要包括Mapper, Reducer, Driver三个部分。
自定义的Mapper和Reducer都要继承各自的父类。Mapper中的业务逻辑写在map()方法中,Reducer的业务逻辑写在reduce()方法中。整个程序还需要一个Driver来进行提交,提交的是一个描述了各种必要信息的job对象。
Mapper
Reducer
Driver
总结
代码
声明:本站所有文章,如无特殊说明或标注,均为本站原创发布。任何个人或组织,在未征得本站同意时,禁止复制、盗用、采集、发布本站内容到任何网站、书籍等各类媒体平台。如若本站内容侵犯了原著者的合法权益,可联系我们进行处理。