这是目标检测中令人惊叹的 AI 模型之一。在这种情况下,您无需克隆存储库、设置要求并配置模型,就像在 YOLOv5 及其之前的版本中所做的那样。
在 YOLOv8 中,不需要执行这些手动任务。您只需安装 Ultralytics 即可,我将向您展示如何通过一个简单的命令安装它。
这是一个提升了先前 YOLO 版本成功率的模型,同时增加了新的功能和改进,以提高性能和灵活性。YOLOv8 是进行各种目标识别和跟踪、实例分割、图像分类和姿态估计任务的理想选择,因为它旨在快速、精确且易于使用。YOLOv8 的官方网站如下:https://github.com/ultralytics/ultralytics/
我们可以使用该模型执行三种类型的任务:
(1) 检测
(2) 分割
(3) 分类
检测
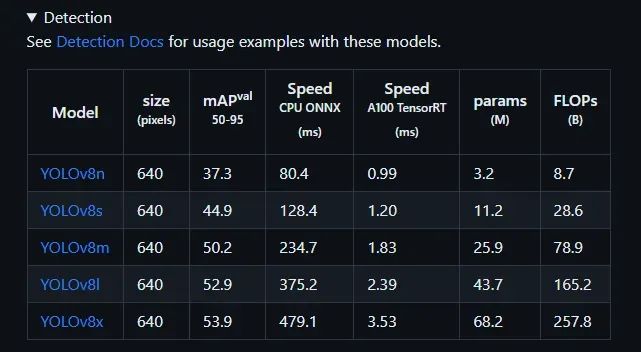
我们可以从下表中选择任一模型进行目标检测:
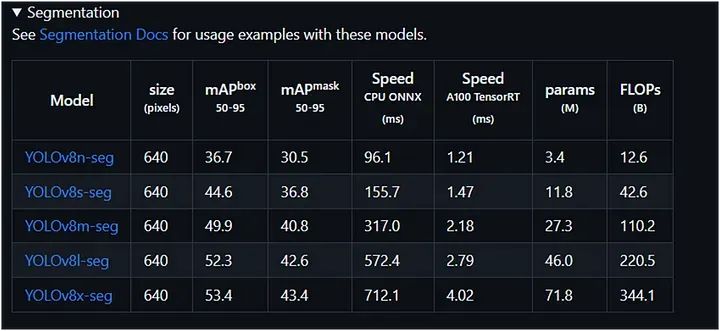
分割
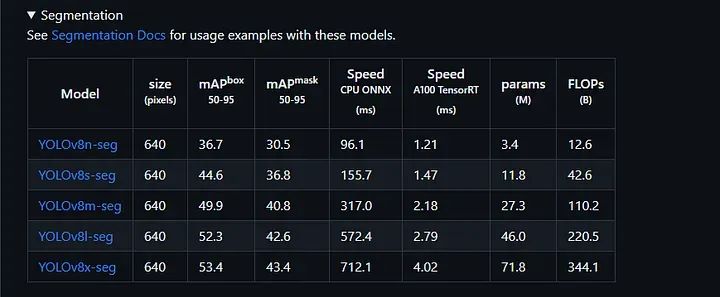
我们可以从下表中选择任一模型进行图像分割:
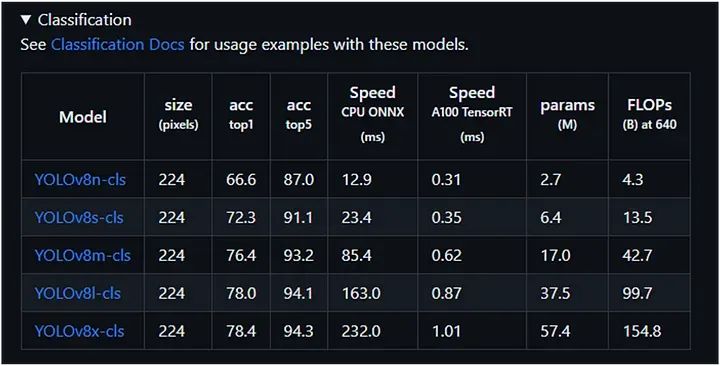
分类
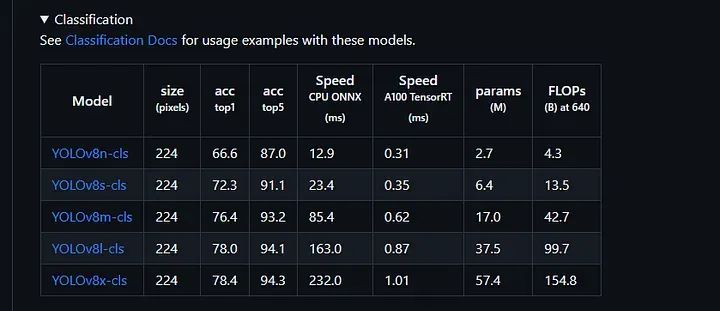
我们可以从下表中选择任一模型进行图像分类:
您可以在下面找到一个快速入门的安装和使用示例,以及完整的培训、验证、预测和部署文档可在 yolov8 文档中找到(https://docs.ultralytics.com/)。
使用 YOLOv8 有两种方式:
(1) CLI — 命令行界面
(2) Python 脚本
现在我将使用 Google Colab 进行训练。在安装之前,我需要连接到我的 GPU。
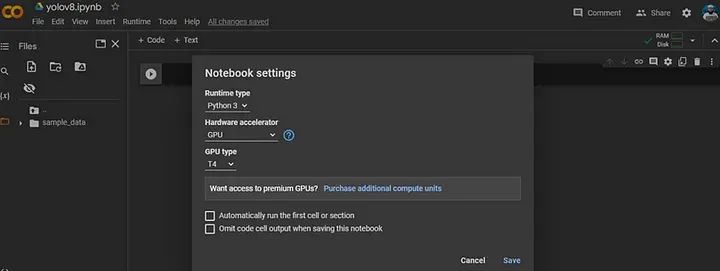 在上述屏幕中选择 GPU 作为硬件加速器后,点击“保存”按钮。
在上述屏幕中选择 GPU 作为硬件加速器后,点击“保存”按钮。
挂载 Google 云硬盘,以便 Colab 可以访问它的文件。
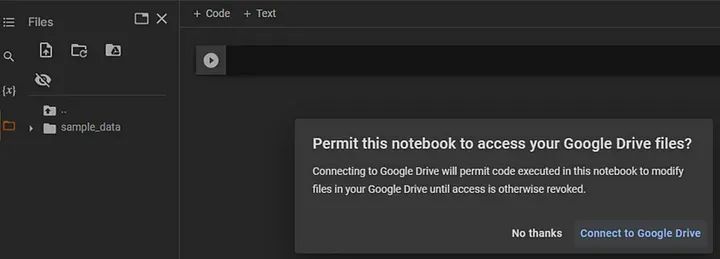 点击上述屏幕中的“连接到Google Drive”按钮后,选择挂载按钮。现在我们的笔记本已连接到Google Drive。
点击上述屏幕中的“连接到Google Drive”按钮后,选择挂载按钮。现在我们的笔记本已连接到Google Drive。
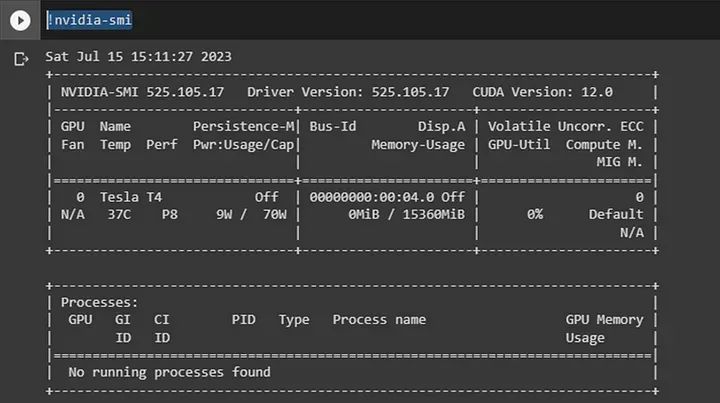
要测试是否获得了GPU,请在Colab上写入以下命令:
我们将通过下面的单个命令安装 YOLOv8 的所有要求和依赖项:

 现在安装成功了。
现在安装成功了。
它有三种模式:
(1) 训练模式 — 表达为 mode = train
(2) 验证模式 — 表达为 mode = val
(3) 预测模式 — 表达为 mode = predict
它执行三种类型的任务:
(1) 检测 — 表达为 task = detect
(2) 分割 — 表达为 task = segment
(3) 分类 — 表达为 task = classify
测试它是否工作,运行以下命令:
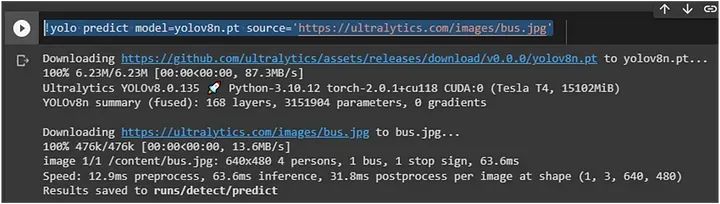
首先,它会下载模型和图像,然后分别对图像进行预测。在这里,我们选择了检测表中的第一个模型 — yolov8n。在下面的屏幕中,我们可以看到模型和图像已下载,并且预测的图像已保存在 `runs/detect/predict/bus.jpg` 中。
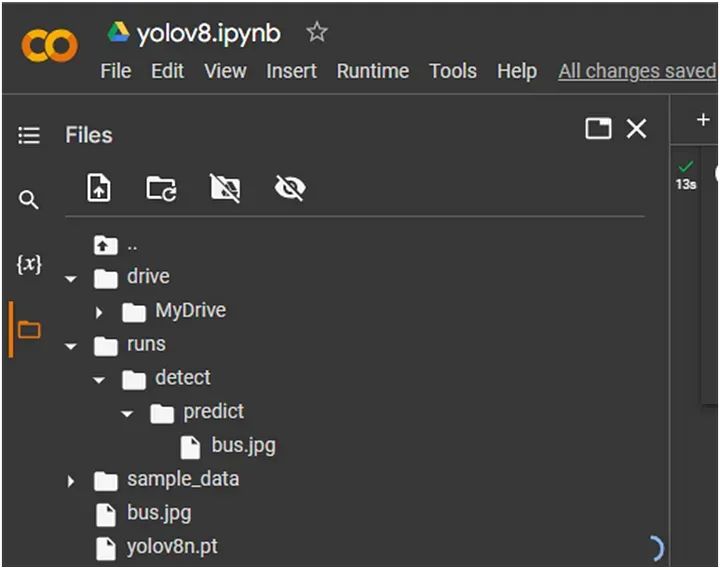
输入图像:

预测的图像:

现在,我将上传一张猫的图像到“images”文件夹进行预测:
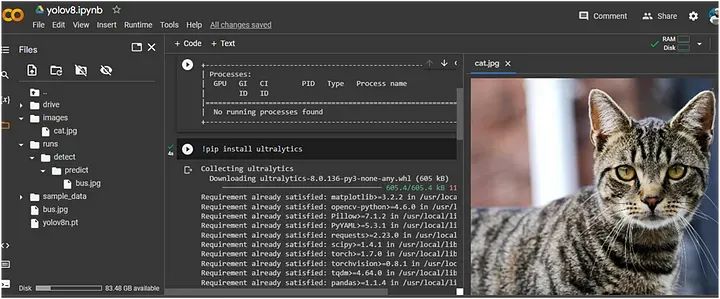
运行以下命令以从图像中检测猫:
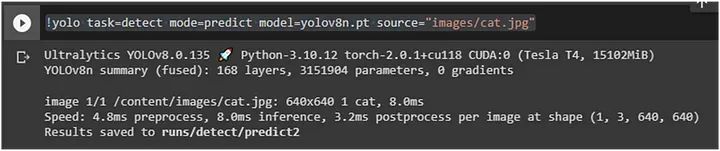
它成功地从图像中预测了猫,并将其保存到 `predict2` 文件夹中。
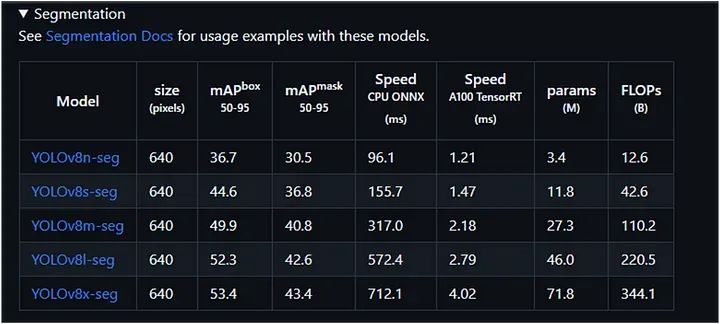
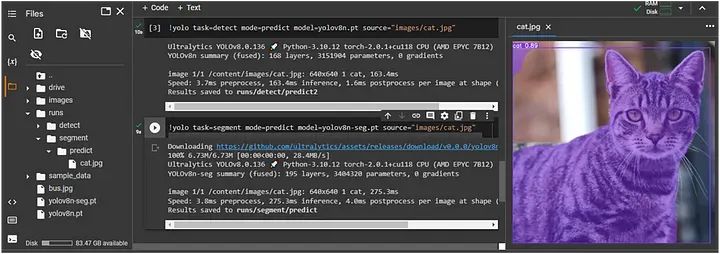
执行分割:
在这里,我们使用了上面表格中的第一个模型 YOLOv8n-seg:
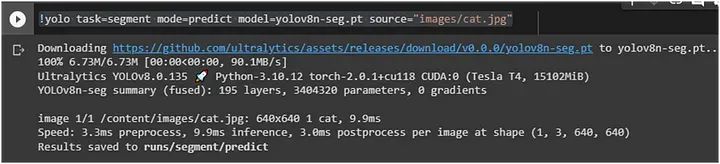
分割后的图像保存在 `runs/segment/predict` 中。
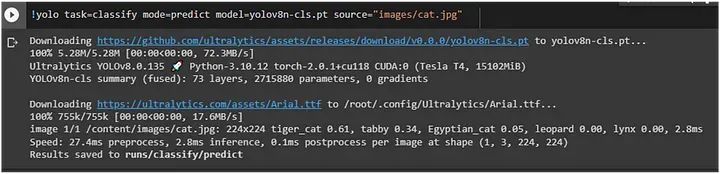
执行分类:
在这里,我们使用了上面表格中的第一个模型 YOLOv8n-cls:
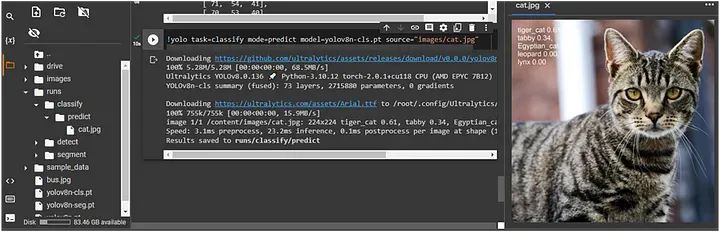
分类后的图像保存在 `runs/classify/predict` 中。
开始自定义训练:
我有一个准备好的数据集已上传到以下 Google Drive 链接:
[Google Drive 数据集链接](https://drive.google.com/drive/u/1/folders/1QQVa1PoaDxhFBU2GJHXWARlpMB_i-qGs)
Google Colab 笔记本链接:
[Google Colab 笔记本链接](https://colab.research.google.com/drive/1crJsLpHzKExZBot5DhDYGmfuTdi1KBxG?authuser=1#scrollTo=YpyuwrNlXc1P)
配置 `data.yaml` 文件:(我们使用上表中的第二个模型)
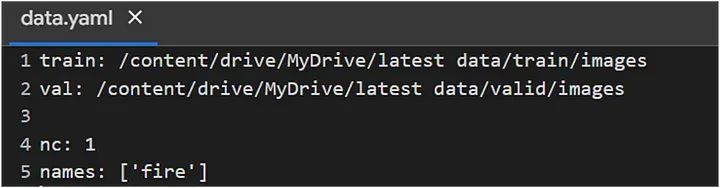
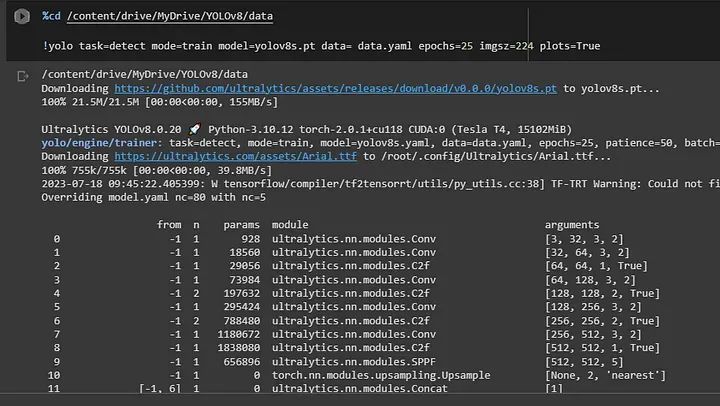
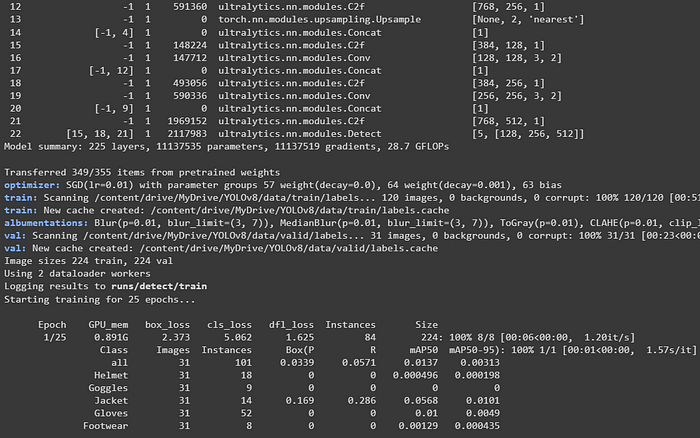
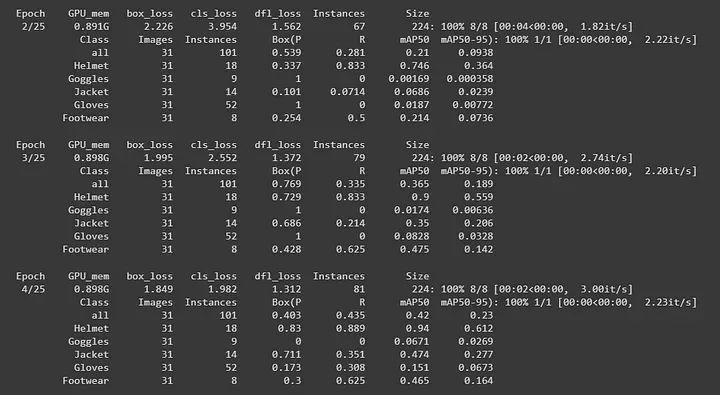
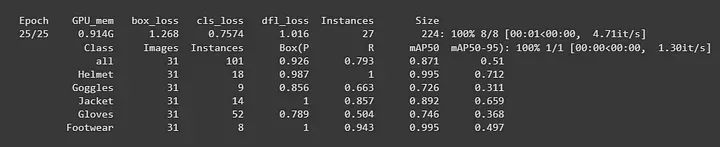
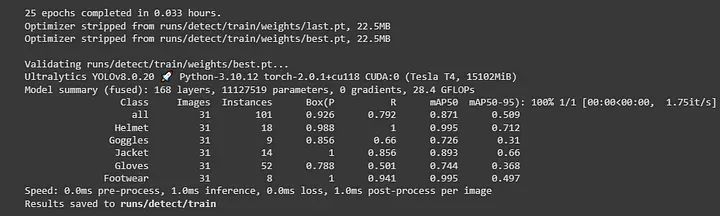
这里, data = data.yaml。在 `data.yaml` 文件中,我列出了所有我的图像路径。因此,它将自动从该文件夹获取图像和标签。

上述代码的解释:
-
IPython.display:IPython 是一个增强型的交互式 Python shell,提供比默认 Python shell 更多功能。通过 IPython.display 模块,它是 IPython 的一个组件,您可以在 Jupyter Notebook 或 IPython 环境中直接显示各种内容类型(如图片、视频、音频、HTML 等)。
-
Image:IPython.display 模块的 Image 类是其中的一个特殊元素。在 Jupyter Notebook 或 IPython 上下文中,它使图像显示变得可能。这意味着您无需在不同的软件中打开它们,即可直接在笔记本中显示照片、图片或其他图像文件。
图像的路径作为输入传递给 Image 类,并且 display() 函数在您的笔记本中输出图像。请注意,图像文件需要是受支持的格式(如 JPG、PNG 或 GIF),并且需要在您的 IPython 环境或 Jupyter Notebook 中可用。
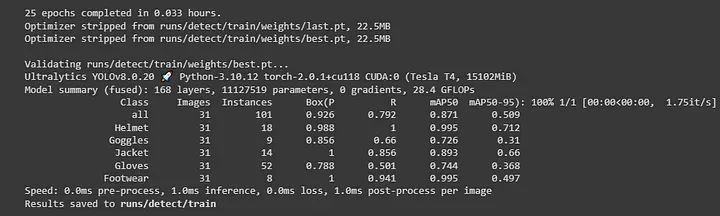
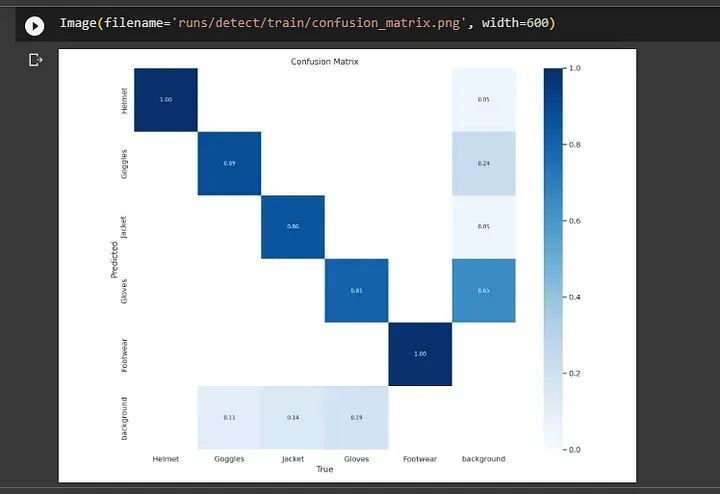
使用 IPython.display 和 Image 可以快速在笔记本中可视化图像,使它们更具教育性和吸引力。显示指定路径 ‘runs/detect/train/’ 中的名为 “confusion_matrix.png” 的图像。
上述代码的解释:
-
通过上述代码 `Image(filename=’runs/detect/train/confusion_matrix.png’, width=600)` 显示 “confusion_matrix.png” 位于 ‘runs/detect/train/’ 目录中。通过 `width=600` 选项将可见图像的宽度设置为 600 像素。
显示另一张名为 “confusion_matrix.png” 的图像,位于指定路径中:
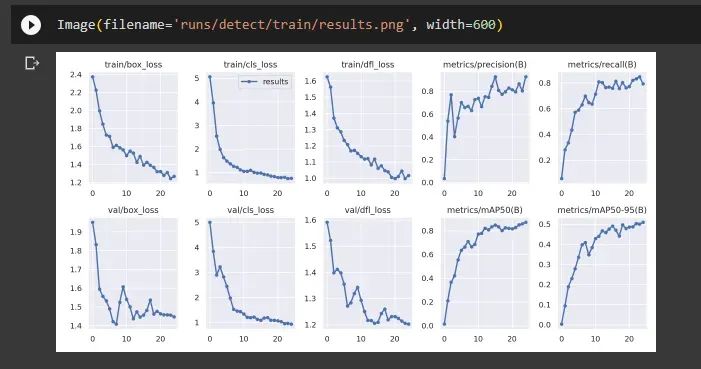
显示另一张名为 “val_batch0_pred.jpg” 的图像,位于指定路径 ‘runs/detect/train/’ 中:
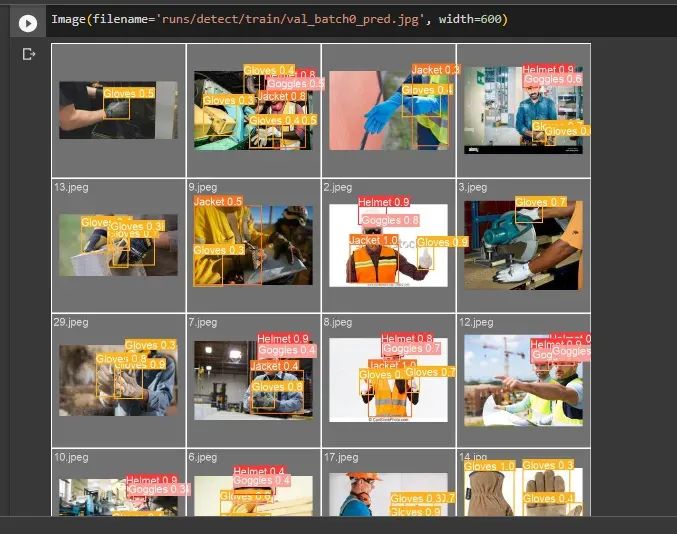
上述代码的解释:
-
通过上述代码 `Image(filename=’runs/detect/train/val_batch0_pred.jpg’, width=600)` 显示 “val_batch0_pred.jpg” 位于 ‘runs/detect/train/’ 给定路径中。通过 `width=600` 选项将可见图像的宽度设置为 600 像素。
使用训练好的 YOLO 模型在验证数据集上执行目标检测:
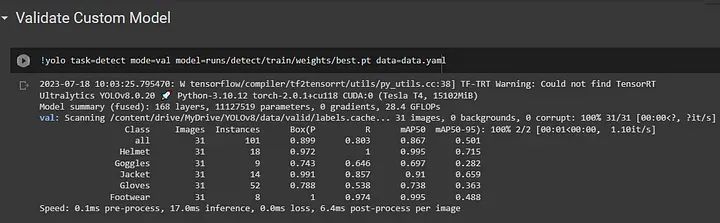
上述代码的解释:
-
命令行工具 `!yolo`:命令的开头的 `!` 符号是 Jupyter Notebook 特有的,表示它是一个在笔记本环境中运行的 shell 命令。
-
`Yolo task=detect`:Yolo 是一个命令行工具,`task=detect` 指示它检测对象。
-
当将 mode 参数设置为 val 时,将使用验证数据集完成任务。这用于评估在应用于新数据时训练的模型的性能。
-
`model=runs/detect/train/weights/best.pt`:指定用于检测的 YOLO 模型权重文件的路径。使用了在训练中获得的最佳权重(来自“train”模式)。
-
`data=data.yaml`:指定包含有关数据集、类别和训练和评估过程中使用的其他设置的数据配置文件(data.yaml)的路径。
使用自定义模型进行推理
使用训练好的 YOLO 模型在新图像上进行目标检测
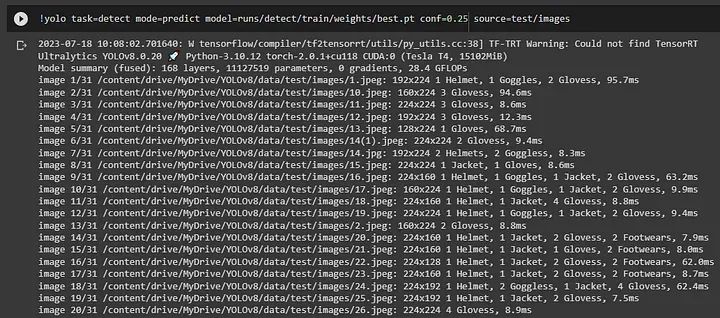

上述代码的解释:
-
选项 `mode=predict` 指示该工具预测并识别提供的照片中的物体。使用它可以对新的、未使用过的照片进行预测。
-
`model=runs/detect/train/weights/best.pt`:这指示 YOLO 模型的权重文件的位置,该权重文件将用于检测。在使用模型进行预测之前,它必须首先在数据集上进行训练。
-
`conf=0.25`:对象检测的置信度阈值设置为 0.25。输出将显示任何置信度大于 0.25 的检测到的对象。
-
`source=test/images`:`source=test/images` 标识包含用于目标检测的图像的目录。在这个例子中,工具将在存储在 test/images 目录中的照片中找到对象。
· END ·
HAPPY LIFE

本文仅供学习交流使用,如有侵权请联系作者删除
原文地址:https://blog.csdn.net/weixin_38739735/article/details/135578917
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。
如若转载,请注明出处:http://www.7code.cn/show_56088.html
如若内容造成侵权/违法违规/事实不符,请联系代码007邮箱:suwngjj01@126.com进行投诉反馈,一经查实,立即删除!






