本文介绍: 回顾LDM的优势:潜在扩散模型 (LDM) 可实现高质量图像合成,同时通过在压缩的低维潜在空间中训练扩散模型来避免过多的计算需求。本文将 LDM 范式应用于高分辨率视频生成,这是一项特别资源密集型的任务。具体步骤如下:1. 首先仅在图像上预训练 LDM;2. 然后,通过向潜在空间扩散模型引入时间维度并对编码图像序列(即视频)进行微调,将图像生成器变成视频生成器。类似地,我们在时间上对齐扩散模型上采样器,将它们转变为时间一致的视频超分辨率模型。1. 提出了一种有效的方法来训练基于LDM的。
目录
一. 项目概述与贡献

二. 方法详解

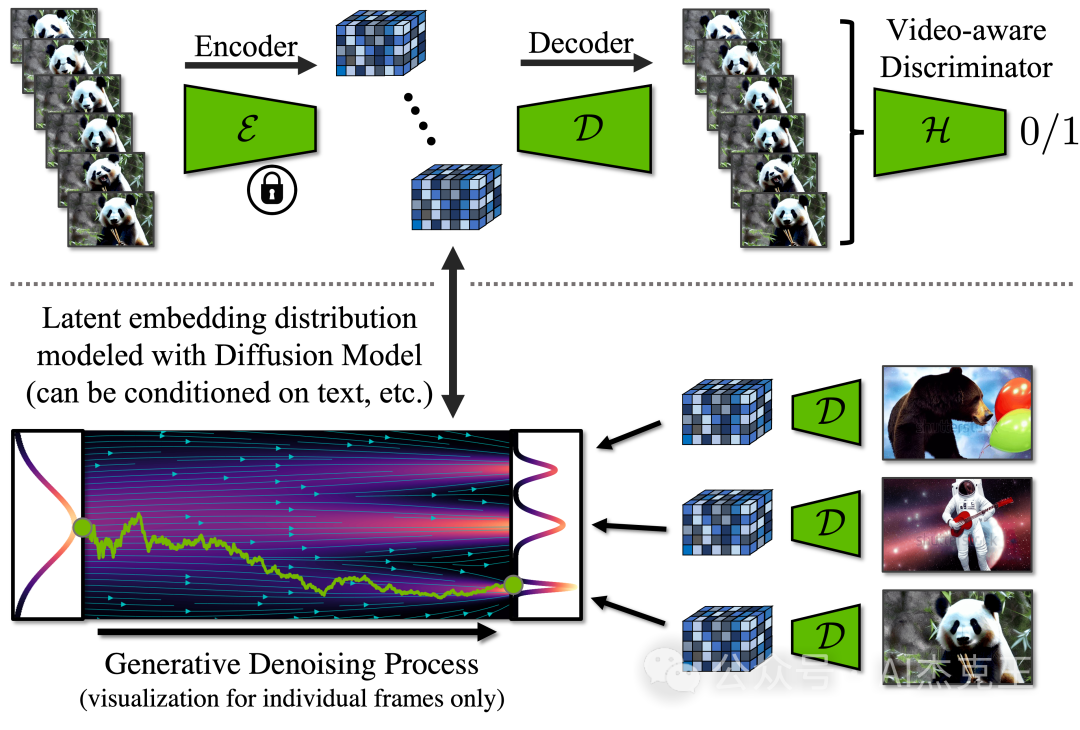

三. 应用总览
四. 个性化视频生成

五. 实时卷积合成

六. 更多结果

七. 论文
八. 个人思考

声明:本站所有文章,如无特殊说明或标注,均为本站原创发布。任何个人或组织,在未征得本站同意时,禁止复制、盗用、采集、发布本站内容到任何网站、书籍等各类媒体平台。如若本站内容侵犯了原著者的合法权益,可联系我们进行处理。






