🎉欢迎您来到我的MySQL基础复习专栏
☆* o(≧▽≦)o *☆哈喽~我是小小恶斯法克🍹
✨博客主页:小小恶斯法克的博客
🎈该系列文章专栏:重拾MySQL
🍹文章作者技术和水平很有限,如果文中出现错误,希望大家能指正🙏
📜 感谢大家的关注! ❤️

目录
🚀事务
事务是数据库管理系统(DBMS)中的一个重要概念,用于确保数据库操作的一致性和完整性。事务是一组数据库操作(例如插入、更新、删除等),这些操作被视为一个不可分割的工作单元,要么全部成功执行,要么全部回滚(撤销)。
在使用事务时,通常需要使用事务控制语句(例如BEGIN、COMMIT和ROLLBACK)来明确地开始、提交或回滚事务。
需要注意的是,事务的使用需要谨慎考虑,并且合理设计事务的边界和范围,以避免潜在的并发问题和性能影响。
举例:
A —— 100 元
B —— 100 元
A 给 B 转账100元 那么A的钱就减少100元,B的钱增加100元,这是一组数据库操作,被视为一个不可分割的工作单元,要么同时成功,要么同时失败
解析:
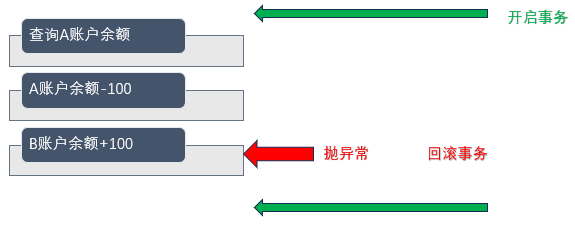
正常情况下,类似转账的操作,可拆分为以下三步
1.查询A账户余额
2.A账户余额减少100 A的余额100-100=0
3.B账户余额增加100 B的余额100+100=200
异常情况下,类似转账的操作,也是这三步,此时在执行第三步时抛出异常
1.查询张三账户余额
2.A账户余额减少100 A的余额100-100=0
3.B账户余额不变 B的余额100
如何解决上述问题?
我们只需要在业务逻辑执行之前开启事务,执行 完毕后提交事务。如果执行过程中报错,则回滚事务,把数据恢复到事务开始之前的状态。
注意:默认MySQL的事务是自动提交的,也就是说,当执行完一条DML语句时,MySQL会立即隐式的提交事务
🚀事务操作
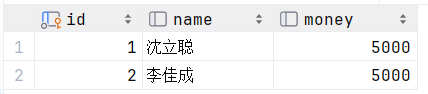
数据准备:
drop table if exists bank; ---如果存在表bank我们就删去
create table bank(
id int primary key auto_increment comment '账户ID',
name varchar(20) comment '账户姓名',
money double(10,2) comment '账户余额'
) comment '账户表';
insert into bank(name, money) values ('沈立聪',5000), ('李佳成',5000);
执行:
🚀 未控制事务
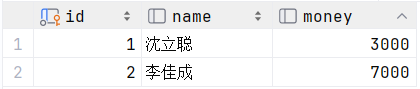
✨测试正常情况
-- 1. 查询沈立聪余额
select * from bank where name = '沈立聪';
-- 2. 沈立聪的余额减少2000
update bank set money = money - 2000 where name = '沈立聪';
-- 3. 李佳成的余额增加2000
update bank set money = money + 2000 where name = '李佳成';
执行:(数据一致)
✨测试异常情况
首先将原数据手动恢复一下:
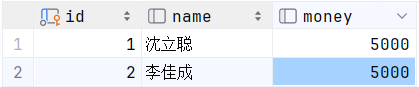
再执行下列语句查看效果
-- 1. 查询沈立聪余额
select * from bank where name = '沈立聪';
-- 2. 沈立聪的余额减少2000
update bank set money = money - 2000 where name = '沈立聪';
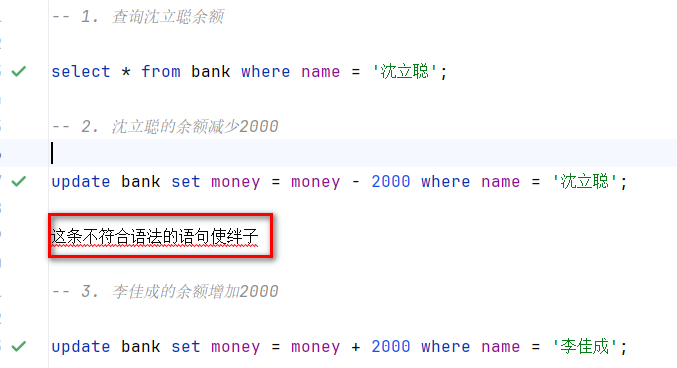
这条不符合语法的语句使绊子...
-- 3. 李佳成的余额增加2000
update bank set money = money + 2000 where name = '李佳成';
执行过程:
我们采用一句不符合语法的句子,中途阻塞一下给李佳成余额增加2000的第三步操作。最终效果如下 (沈立聪2000元扣除,但是李佳成2000元没有加上)
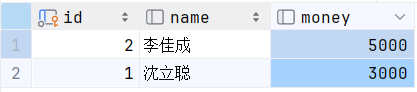
发现前后数据量是不对的
🚀 控制事务
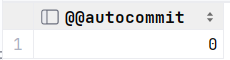
✨查看事务状态
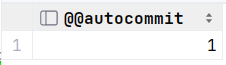
你可以使用以下语句来查看当前事务的状态:
SELECT @@autocommit ; --注意只针对当前窗口有效
这将显示当前的自动提交(autocommit)设置,如果它的值为1,表示自动提交已启用;如果为0,表示自动提交已禁用。
执行:
✨设置事务
你可以使用以下语句来设置事务的自动提交选项:
注意:如果你已经将事务的提交方式设置为了手动提交,此时当你在执行任何一个DML语句时,它只是去临时修改了表数据,并没有提交给数据库,要提交给数据库,必须执行commit命令
SET autocommit = 0; -- 禁用自动提交,开启事务
执行:
✨提交事务
一旦你禁用了自动提交,你可以使用以下语句来提交事务:
COMMIT;
✨开启事务
START TRANSACTION 或 BEGIN ;✨回滚事务
如果在事务执行过程中出现了错误,你可以使用以下语句来回滚事务:
ROLLBACK;注意:上述的这种方式,我们是修改了事务的自动提交行为, 把默认的自动提交修改为了手动提交, 此时我们执行的DML语句都不会提交, 需要手动执行commit操作进行提交。控制事务二
🚀注意事项
在使用事务时,需要注意以下几点:
-
谨慎使用事务:事务应该被精心设计,避免事务范围过大或持续时间过长,以免影响数据库性能和并发性。
-
避免长时间锁定:长时间的事务可能会导致数据库中的行或表被长时间锁定,影响其他事务的执行。因此,应尽量避免长时间的事务操作。
-
异常处理:在事务中应该包含适当的异常处理机制,以便在出现错误时能够回滚事务并进行恰当的处理。
-
保持事务简洁:尽量避免在事务中进行复杂的逻辑或长时间的计算,以免影响其他事务的执行。
-
定时提交:如果可能的话,应该在事务中定期进行提交,而不是等到事务结束才提交,以减小锁定的范围和时间。
-
并发控制:在设计事务时,需要考虑并发控制的问题,避免出现数据不一致或并发冲突的情况。
以上是一些使用事务时需要注意的事项。合理的使用事务可以确保数据库操作的一致性和完整性,但需要注意避免潜在的性能和并发问题。
转账案例:
-- 开启事务
begin ;
-- 1. 查询张三余额
select * from bank where name = '沈立聪';
-- 2. 沈立聪的余额减少2000
update bank set money = money - 2000 where name = '沈立聪';
-- 3. 李佳成的余额增加2000
update bank set money = money + 2000 where name = '李佳成';
-- 如果正常执行完毕, 则提交事务
commit;
-- 如果执行过程中报错, 则执行回滚事务
rollback;执行:
![]()
若执行异常,事务回滚之后
![]()
🚀事务四大特性
事务是指一组数据库操作,这些操作要么全部执行成功,要么全部回滚。在数据库中,事务具有四个基本特性,即ACID特性。下面我将对这四个特性进行详细描述:
原子性(Atomicity)
原子性是指一个事务中的所有操作要么全部执行成功,要么全部回滚。如果在事务执行过程中出现任何错误,所有已经执行的操作都将被回滚,数据库状态将恢复到事务开始之前的状态。
一致性(Consistency)
一致性是指在事务执行过程中,数据库从一个一致性状态转换到另一个一致性状态。这意味着事务执行过程中不会破坏数据库的完整性约束,如主键、外键、约束等。
隔离性(Isolation)
隔离性是指在并发环境下,每个事务都应该被隔离开来,互不干扰。每个事务应该感觉到自己在单独地操作数据库,即使在并发执行的情况下也是如此。这意味着一个事务的结果不应该受到其他事务的影响。
持久性(Durability)
持久性是指在事务提交后,对数据库所做的更改应该永久保存在数据库中,并且即使在系统故障的情况下也应该得到保持。
在实际应用中,事务的隔离性是最容易被忽略的一个特性。当多个事务并发执行时,可能会出现一些问题,如脏读、不可重复读和幻读等问题。这些问题是由于事务之间的相互干扰导致的。
为了解决这些问题,数据库定义了四个事务隔离级别,分别为读未提交(Read Uncommitted)、读已提交(Read Committed)、可重复读(Repeatable Read)和串行化(Serializable)。不同的隔离级别提供了不同的事务隔离程度,具体如下:
读未提交(Read Uncommitted)
在此隔离级别下,一个事务可以读取另一个事务未提交的数据。这种隔离级别的优点是并发性高,但缺点是可能会出现脏读、不可重复读和幻读等问题。
读已提交(Read Committed)
在此隔离级别下,一个事务只能读取另一个事务已经提交的数据。这种隔离级别可以避免脏读的问题,但仍然可能出现不可重复读和幻读等问题。
可重复读(Repeatable Read)
在此隔离级别下,一个事务在执行期间读取的数据集合是固定的。这种隔离级别可以避免脏读和不可重复读的问题,但仍然可能出现幻读的问题。
串行化(Serializable)
在此隔离级别下,所有事务都是串行执行的。这种隔离级别可以避免所有并发问题,但是会降低并发性能。
需要注意的是,隔离级别越高,事务的并发性能就越低,因此需要根据具体的业务需求和性能要求进行适当的选择。
🚀并发事务问题
在数据库中,当多个事务同时并发执行时,可能会出现一些并发事务问题。这些问题包括脏读、不可重复读和幻读。下面我将对这些问题进行详细解读:
1. 脏读(Dirty Read)
脏读指的是一个事务读取了另一个事务未提交的数据。假设事务A修改了某个数据,但还没有提交,此时事务B读取了这个数据。如果事务A在后续的操作中回滚了,那么事务B读取的数据就是脏数据,即脏读。
2. 不可重复读(Non-Repeatable Read)
不可重复读指的是在一个事务内,由于并发事务的修改,同一查询条件的结果在事务执行过程中发生了变化。例如,事务A首先读取了某个数据,然后事务B修改了这个数据并提交,接着事务A再次读取相同的数据,发现数据已经发生了变化,这就是不可重复读。
3. 幻读(Phantom Read)
幻读指的是在一个事务内,由于并发事务的插入或删除操作,同一查询条件的结果集发生了变化。例如,事务A首先读取了某个范围的数据,然后事务B插入了符合这个范围的新数据并提交,接着事务A再次读取相同的范围数据,发现数据集合发生了变化,这就是幻读。
并发事务问题的解决方法
为了解决并发事务问题,数据库系统提供了不同的事务隔禅级别,如读未提交、读已提交、可重复读和串行化。通过设置不同的隔离级别,可以控制事务之间的相互影响,从而避免脏读、不可重复读和幻读等问题。
此外,还可以通过加锁机制来解决并发事务问题。数据库系统提供了行级锁、表级锁、页级锁等不同的锁机制,可以在事务执行过程中对数据进行加锁,从而避免并发事务问题的发生。
总的来说,合理设置事务隔离级别、使用合适的锁机制以及精心设计事务操作,可以有效地解决并发事务问题,确保数据库操作的一致性和完整性。
🚀事务隔离级别
|
隔离级别 |
脏读 |
不可重复读 |
幻读 |
|
Read uncommitted |
√ |
√ |
√ |
|
Read committed |
× |
√ |
√ |
|
Repeatable Read(默认) |
× |
× |
√ |
|
Serializable |
× |
× |
× |
查看事务隔离级别
SELECT @@TRANSACTION_ISOLATION;设置事务隔离级别
SET TRANSACTION ISOLATION LEVEL <isolation_level>;
其中,
<isolation_level>是指定的隔离级别,可以是以下四个隔离级别之一:READ UNCOMMITTED、READ COMMITTED、REPEATABLE READ、SERIALIZABLE。
例如,要将事务隔离级别设置为可重复读(REPEATABLE READ),可以使用以下SQL语句:
SET TRANSACTION ISOLATION LEVEL REPEATABLE READ;
❤️谢谢你这么好看还来关注我!❤️
原文地址:https://blog.csdn.net/qq_69178067/article/details/135593414
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。
如若转载,请注明出处:http://www.7code.cn/show_56148.html
如若内容造成侵权/违法违规/事实不符,请联系代码007邮箱:suwngjj01@126.com进行投诉反馈,一经查实,立即删除!