本文介绍: 当我们有一个服务器,服务器上面有4-5个GPU,那么我们需要时刻看哪个GPU空着,当发现服务器空闲了,我们就可以跑自己的深度学习了。然而,人盯着总是费时费力的,所以可以让Python看到哪个GPU空闲就插进去吗?进行下面步骤即可。
问题描述
当我们有一个服务器,服务器上面有4-5个GPU,那么我们需要时刻看哪个GPU空着,当发现服务器空闲了,我们就可以跑自己的深度学习了。
然而,人盯着总是费时费力的,所以可以让Python看到哪个GPU空闲就插进去吗?
进行下面步骤即可。
第一步、安装GPU信息查看包
名字为:nvidia_ml_py-12.535.133-py3-none-any.whl,
下载地址:https://pypi.org/project/nvidia-ml-py/
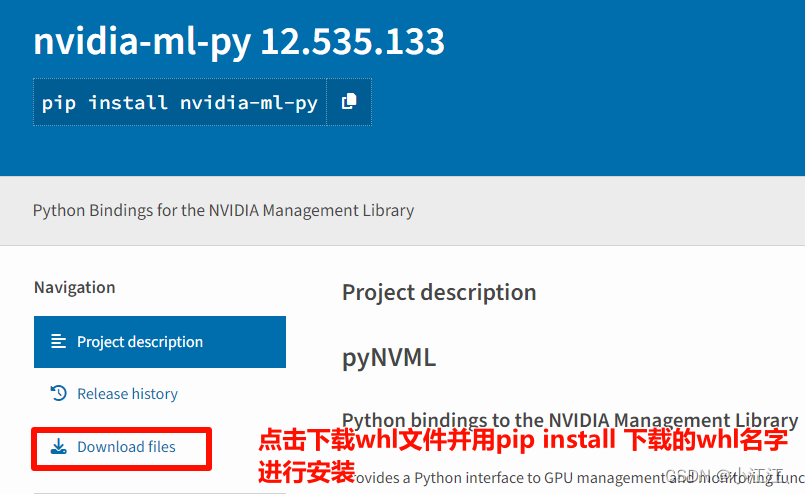
当然,如果网络足够好,可以直接利用pip安装:
第二步、编码select_gpu
即判定抢占GPU的代码
select_gpu共三个参数
select_gpu 用于抢占GPU
参数1:count传GPU个数,默认传torch.cuda.device_count(),即存在的GPU个数
参数2:threshold是阈值,低于此阈值说明GPU是空闲的,默认1024MB [GPU一般什么都不跑,也会被占用几十MB]
参数3:second是每几秒进行继续轮训,默认5秒
第三步、编写运行深度学习代码,以YOLOv8为例
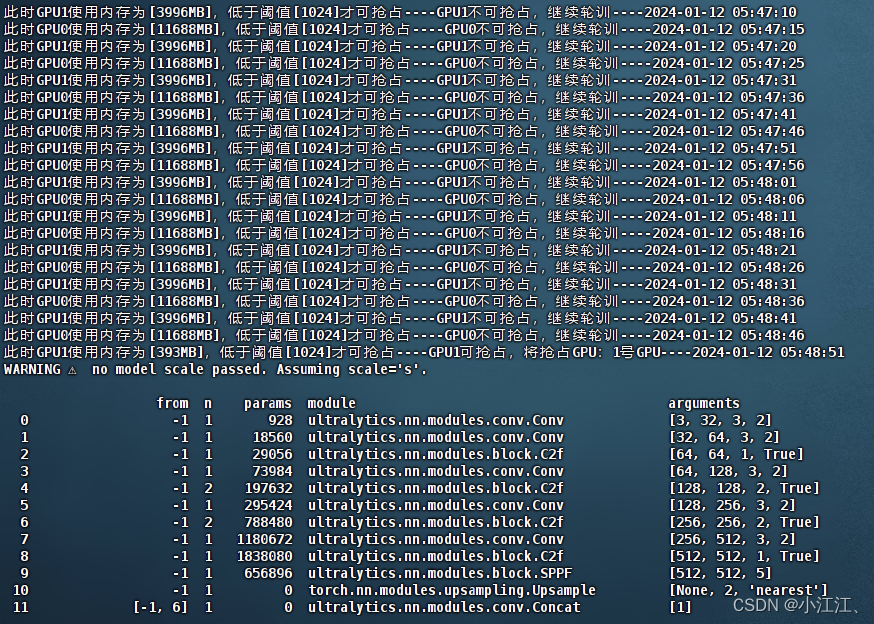
第四步、运行代码,查看运行效果
声明:本站所有文章,如无特殊说明或标注,均为本站原创发布。任何个人或组织,在未征得本站同意时,禁止复制、盗用、采集、发布本站内容到任何网站、书籍等各类媒体平台。如若本站内容侵犯了原著者的合法权益,可联系我们进行处理。