本文介绍: ChatGPT提示词工程进阶
两种大型语言模型
清晰具体的书写提示词
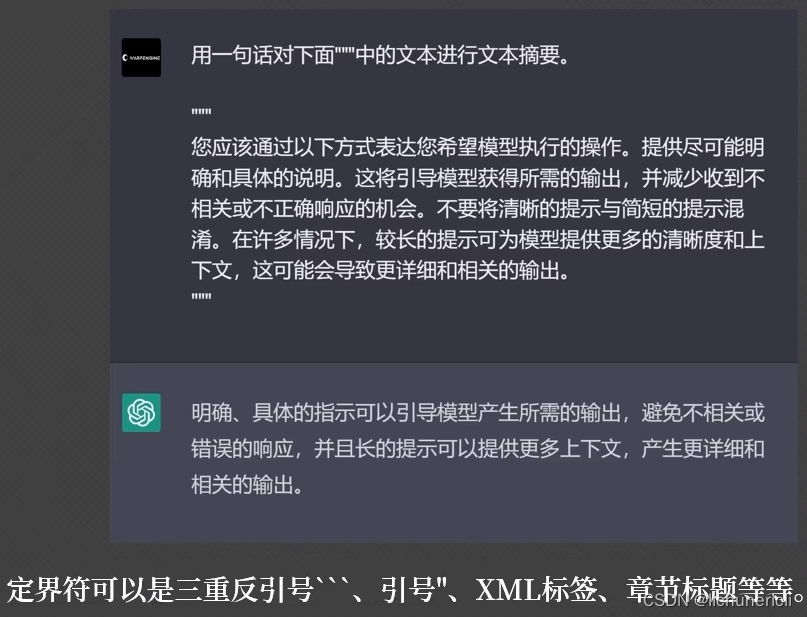




注意规避模型的局限性,例如:gpt-3.5-tuibo模型的局限性:
更好的迭代提示词

用大语言模型总结文本


使用大语言模型的语义推理
语义推理:让模型针对文本内容执行某种分析,例如:提取标签,提取名称,文本情感分析等等。
在传统的机器学习工作流程中,如果您想识别一段文本到底是积极还是消极的情感,就必须收集标签数据集、训练模型,弄清楚如何在某个地方部署模型并进行推理。


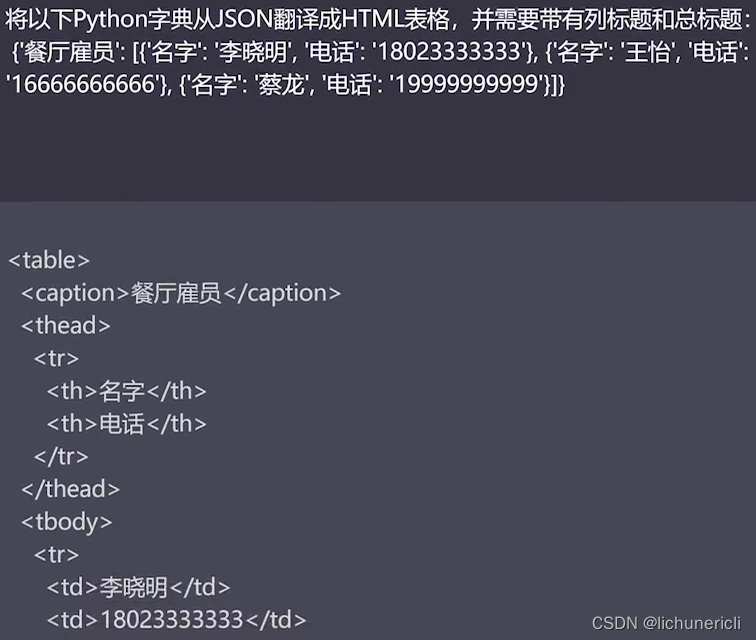
使用大模型进行文本转换



使用ChatGPT的温度值(temperature)

构建自己的聊天机器人

声明:本站所有文章,如无特殊说明或标注,均为本站原创发布。任何个人或组织,在未征得本站同意时,禁止复制、盗用、采集、发布本站内容到任何网站、书籍等各类媒体平台。如若本站内容侵犯了原著者的合法权益,可联系我们进行处理。






