本文介绍: 实施和维持健康的基础设施监控是一个涉及策略制定、工具选择、实践应用和持续改进的过程。监控的目标是保障系统的稳定运行,预防问题发生及时响应和解决故障,同时通过对采集到的数据进行深入分析,指导未来基础设施的优化和决策。6、无服务器架构并提供一个使用场景无服务器架构是一种云计算执行模型,在该模型中,云提供商运行服务端逻辑和服务器资源管理,而不是传统的、显式分配的、持久的云虚拟机。这里的“无服务器”并不意味着没有服务器,而是指开发人员不需要管理服务器。
1、DevOps 的理念是什么?
DevOps是一种组织文化、流程和工具的集合,旨在提高软件交付的速度和质量,通过自动化和持续改进的方法来促进开发(Dev)和运维(Ops)的协作。
DevOps的核心理念包括:
DevOps的实施
要实践DevOps,组织通常遵循几个实施步骤:
DevOps的效益
通过DevOps实践,组织可以获得多个方面的益处:
DevOps不是一个工具或是一个具体的方法论,它是融合文化、工具、流程和实践到一起的集合体,旨在缩短从开发到操作的软件开发生命周期,并提升持续交付的能力。
2、持续集成(CI)和持续部署(CD)?
持续集成(Continuous Integration,简称CI)和持续部署(Continuous Deployment,简称CD)是现代软件开发中使用的实践方法,特别是在遵循敏捷和DevOps原则的团队中。它们旨在提高软件开发和发布的速度和效率。另外,持续交付(也称为CD,有时用于区分持续部署)是这一实践的一个弱化版本。
持续集成(CI)
持续集成是一种开发实践,开发人员经常(通常是每日多次)将代码变更合并到共享仓库(如Git)中。每次代码合并后,都会自动触发一系列快速的构建和测试步骤,以确保新代码的变更不会引入错误,并且系统作为一个整体仍能正常工作。
持续部署(CD)
实施CI/CD时的考虑因素:
3、什么是基础设施即代码(IaC),并解释其优势?
基础设施即代码的核心概念:
基础设施即代码的实现方法:
基础设施即代码的优势:
实践中的IaC工具:
4、Docker 和 Kubernetes 的区别?
Docker
Kubernetes
Docker vs Kubernetes:
5、如何实施监控以确保基础设施的健康状况?
1. 建立监控目标
2. 设计监控架构
3. 选择监控工具
4. 实施日志管理
5. 建立阈值和警报
6. 构建自动化响应机制
7. 部署监控代理和集成数据收集
8. 数据可视化
9. 进行压力测试和容量规划
10. 持续审计和优化
11. 文档和培训
12. 符合合规性和安全性需求
总结
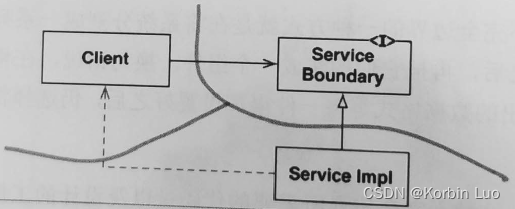
6、无服务器架构并提供一个使用场景
关键特点
组件
优势
缺点
使用场景:在线图片处理服务
实施步骤:
7、云提供商之间的多云策略是什么?
多云策略的关键组成部分:
1. 部署决策
2. 应用架构
3. 数据管理
4. 运营和自动化
5. 成本效益
6. 安全性和合规性
使用多云策略的优势:
使用场景举例:
国际金融服务公司
8、什么是微服务架构?
微服务架构的关键特征:
责任分离:
独立部署:
技术多样性:
分散治理:
灵活性:
可伸缩性:
弹性:
微服务架构的优势:
敏捷开发和部署:
可靠性:
伸缩性:
微服务架构的挑战:
复杂性:
数据一致性:
网络延迟:
测试:
跟踪和监控:
微服务使用场景举例:
9、如何管理和保密敏感的运维数据,如密码或秘钥?
1. 数据分类
2. 使用密码管理器
3. 使用密钥管理系统
4. 最小权限原则
5. 加密传输
6. 定期更换密钥
7. 审计与监控
8. 访问控制
9. 员工培训
10. 应急响应计划
11. 安全策略的设计与评审
12. 本地加密
13. 环境隔离
14. 持续监测与更新
10、蓝绿部署和金丝雀部署的区别?
蓝绿部署
金丝雀部署
比较
11、GitOps 是什么,以及它如何与 DevOps 协作?
GitOps 的关键组成部分:
GitOps 与 DevOps 的关系:
如何协作:
GitOps 的优势:
实践举例:
12、灾难恢复计划的重要组成部分?
1. 风险评估与业务影响分析(BIA)
2. 重要业务功能的识别
3. 定义恢复策略
4. 灾难恢复团队
5. 紧急联系信息
6. 详细的恢复步骤
7. 数据备份和复制
8. 备用设施和基础设施
9. 沟通计划
10. 测试和练习
11. 文档管理和更新
12. 法规遵从
13. 保险
14. 反馈和持续改进
13、如何优化构建和部署流程的速度?
1. 分析现有流程
2. 采用现代化的CI/CD工具
3. 优化构建工具和环境
4. 代码库维护
5. 并行化和分布式构建
6. 调整测试策略
7. 优化部署策略
8. 流程自动化
9. 监控和反馈
10. 文化和实践
11. 利用云服务和资源
12. 定期审查和优化
14、面临网络延迟和服务中断时,如何确保高可用性?
1. 冗余设计
2. 自动化故障转移和恢复
3. 服务质量(QoS)策略
4. 弹性和可扩展性
5. 性能优化
6. 全球分布式CDN
7. 网络优化
8. 强化数据持久性和备份
9. 应用层策略
10. 应用监控与分析
11. 实施业务连续性计划(BCP)
12. 安全性考虑
13. 文档与培训
14. 持续改进
15. 供应商管理
15、 Ansible、Chef 和 Puppet 有什么不同?
Ansible
Chef
Puppet
综合比较
16、如何解决合服期间的合并冲突?
识别冲突:
分析冲突:
解决冲突:
提交合并结果:
避免未来的冲突:
17、在生产环境中部署时应考虑哪些安全最佳实践?
1. 最小权限原则
2. 安全配置
3. 使用安全的部署流程
4. 秘密管理
5. 安全编码实践
6. 数据保护
7. 防火墙和网络隔离
8. 持续监控和日志记录
9. 应用层面的安全性
10. 定期更新和补丁管理
11. 事故响应计划
12. 安全培训
13. 遵循行业标准与合规
14. 使用TLS证书
15. 第三方安全评估
18、什么是持续监控,如何实现?
如何实现持续监控:
1. 设定监控目标和指标
2. 选择监控工具和软件
3. 配置监控系统
4. 集成日志管理
5. 实施自动化响应
6. 测试监控系统
7. 文档和培训
8. 持续审计和优化
9. 遵循合规性和最佳实践
10. 备份和灾难恢复计划
监控工具示例:
19、你如何处理在编排容器时遇到的存储问题?
1. 了解状态和无状态容器
2. 使用持久卷
3. 存储卷类型的选择
4. 集成存储解决方案
5. 数据备份和恢复策略
6. 适用性能考虑
7. 网络和存储优化
8. 可用性和冗余
9. 安全性
10. 更新和滚动更新的考虑
11. 监控和警报
示例:在 Kubernetes 中处理存储问题
20、12因素应用程序方法论
1. 基准代码 (Codebase)
2. 依赖项 (Dependencies)
3. 配置 (Config)
4. 后端服务 (Backing Services)
5. 构建、发布、运行 (Build, Release, Run)
6. 进程 (Processes)
7. 端口绑定 (Port Binding)
8. 并发 (Concurrency)
9. 可处置性 (Disposability)
10. 开发环境与生产环境等价 (Dev/Prod Parity)
11. 日志 (Logs)
12. 管理进程 (Admin Processes)
声明:本站所有文章,如无特殊说明或标注,均为本站原创发布。任何个人或组织,在未征得本站同意时,禁止复制、盗用、采集、发布本站内容到任何网站、书籍等各类媒体平台。如若本站内容侵犯了原著者的合法权益,可联系我们进行处理。