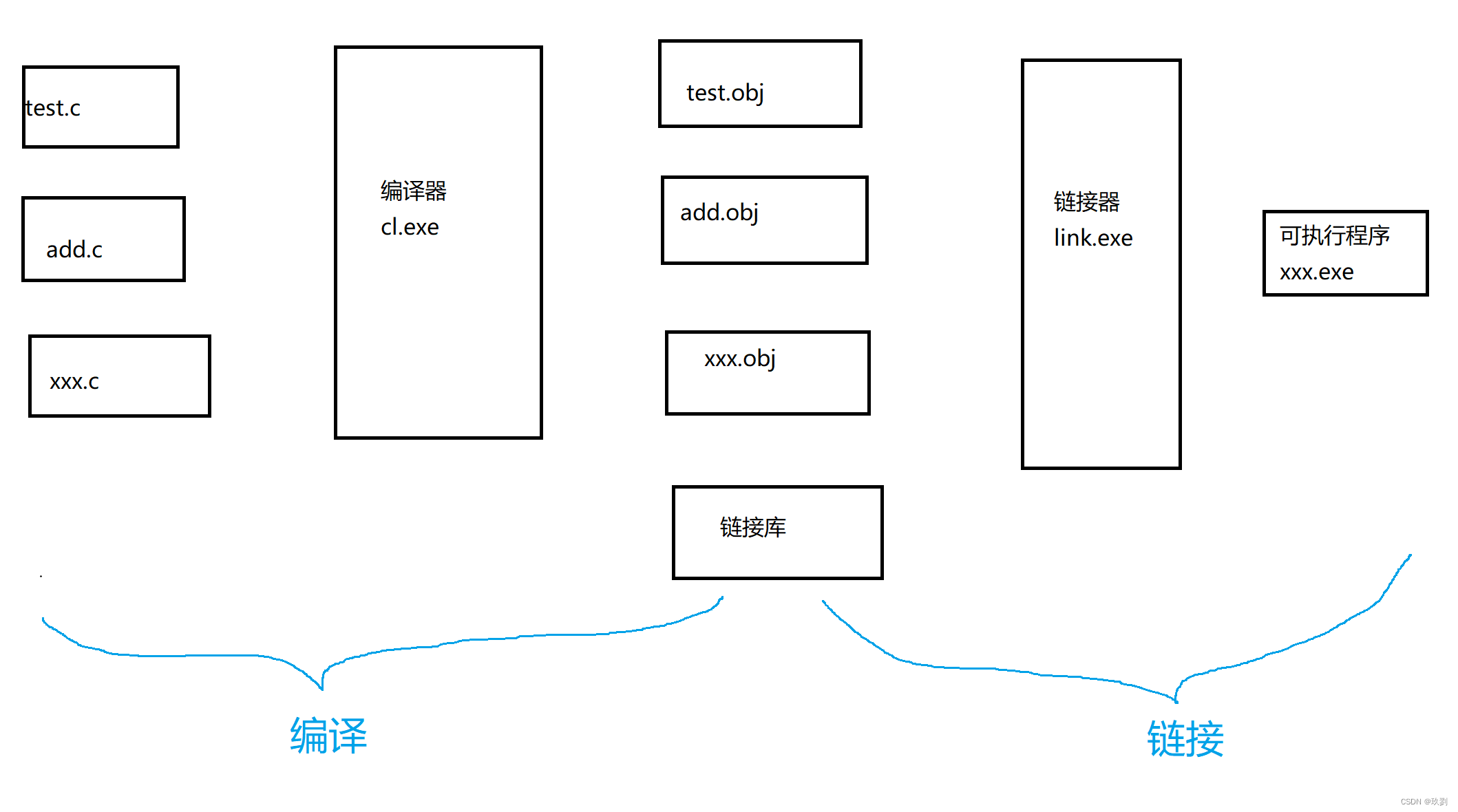
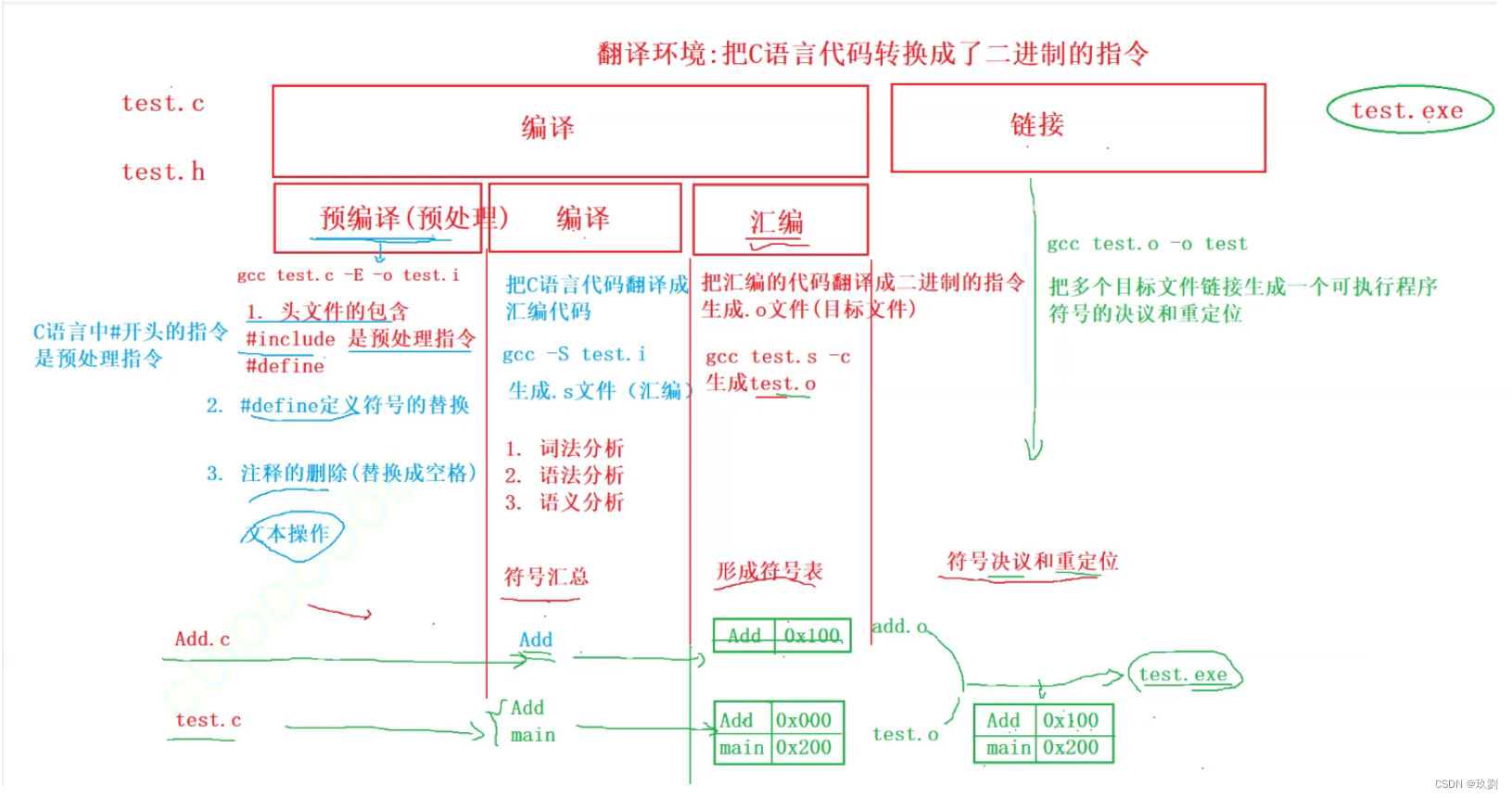
本文介绍: 所以当我无法知道宏定义或者头文件是否包含正确的时候,可以查看预处理后的.i文件来确认,但比较遗憾的是,.i文件一般是作为临时文件的,最后会被系统直接删除,所以在文件夹中找不到,在VS这样的集成环境下是无法观察的,但在gcc下可以用命令观察到。比如:目标文件的格式elf,链接底层实现中的空间与地址分配,符号解析和重定位等,如果你有兴趣,可以看《程序的自我修养》⼀书来详细了解。将源代码程序被输入扫描器,扫描器的任务就是简单的进行词法分析,把代码中的字符分割成⼀系列的记号(关键字、标识符、字面量、特殊字符等)。
目录
一:翻译环境和运行环境


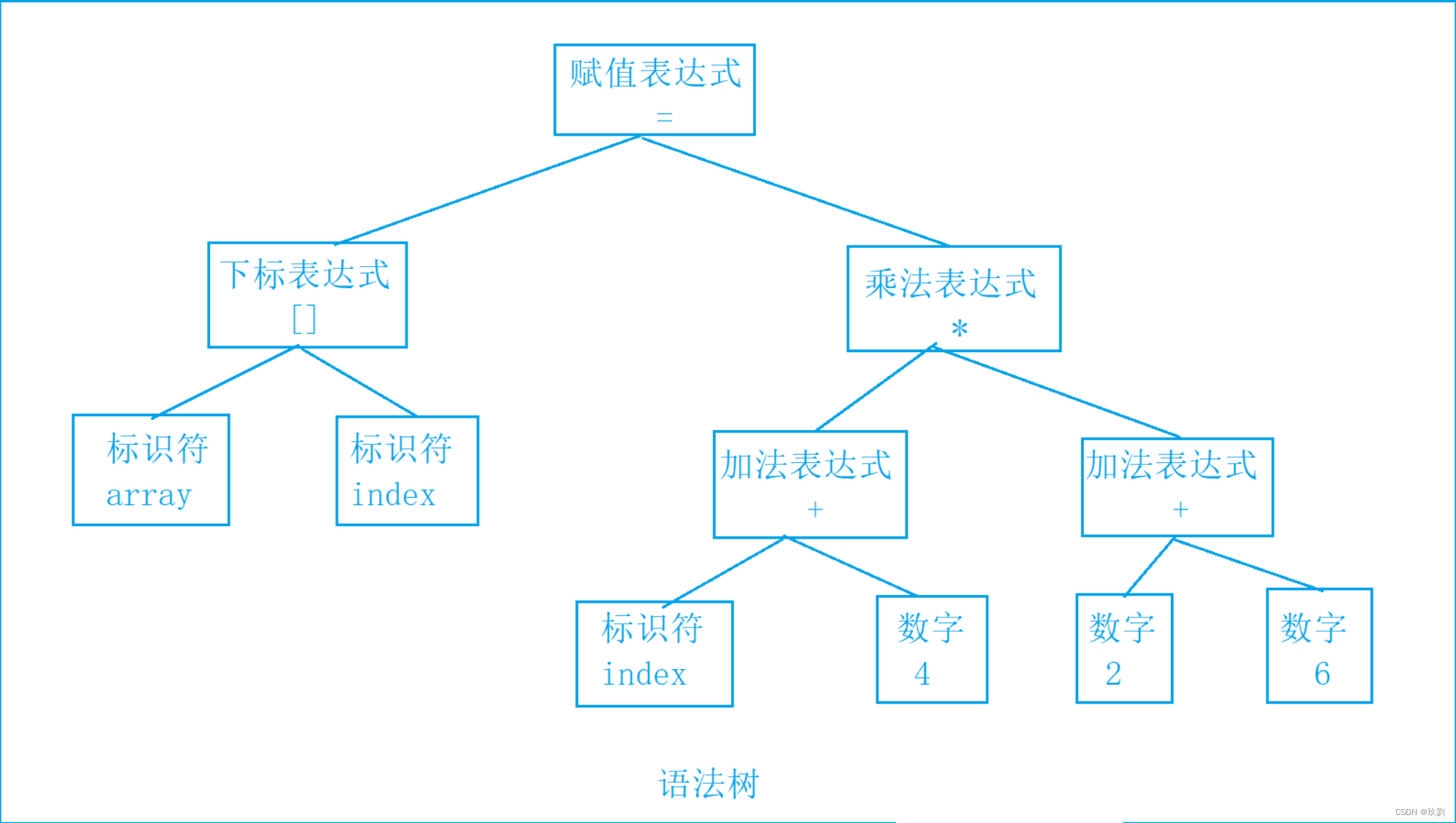
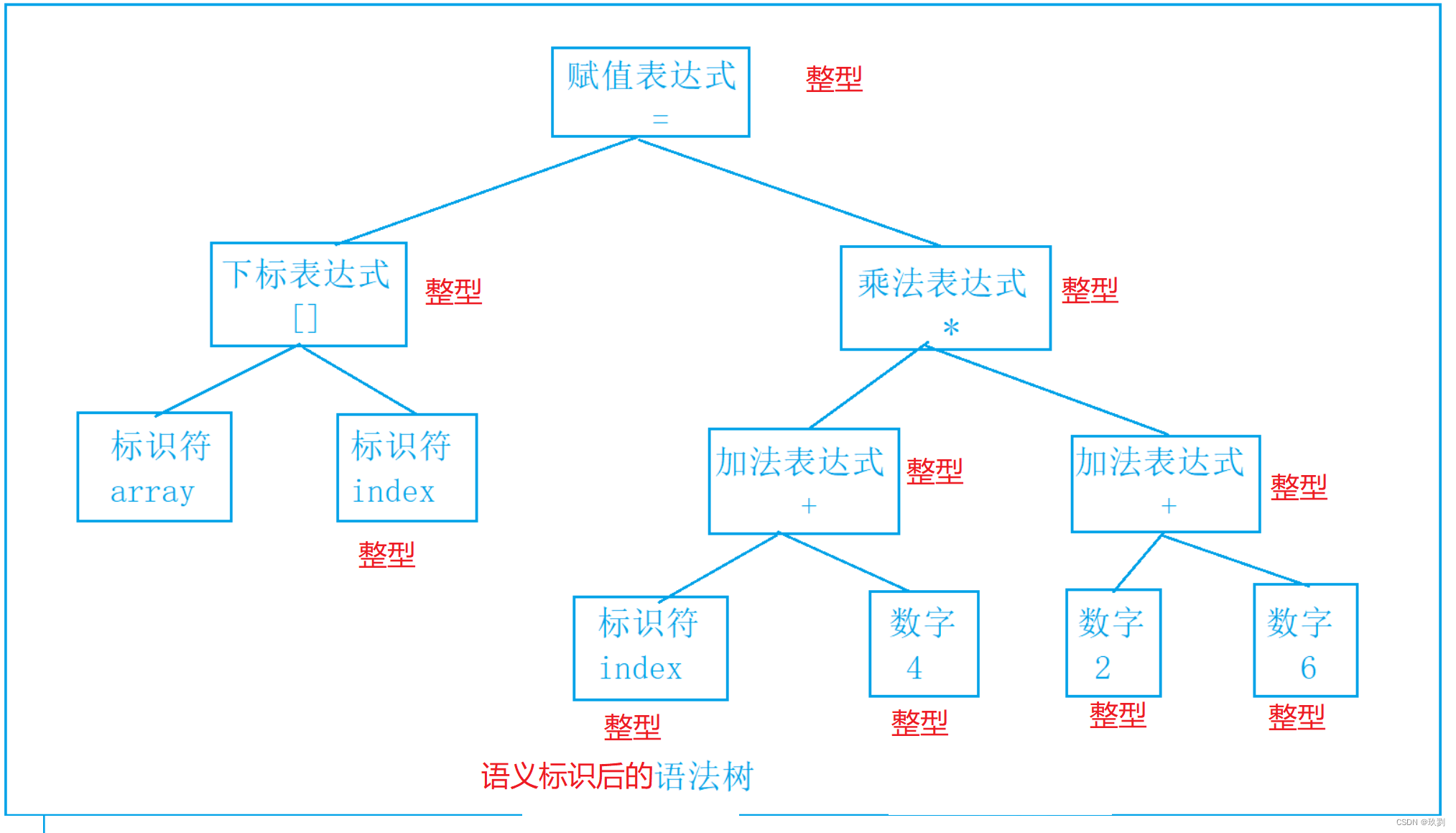

声明:本站所有文章,如无特殊说明或标注,均为本站原创发布。任何个人或组织,在未征得本站同意时,禁止复制、盗用、采集、发布本站内容到任何网站、书籍等各类媒体平台。如若本站内容侵犯了原著者的合法权益,可联系我们进行处理。